Python使用中文正则表达式匹配指定中文字符串的方法示例
本文实例讲述了Python使用中文正则表达式匹配指定中文字符串的方法。分享给大家供大家参考,具体如下:
业务场景:
从中文字句中匹配出指定的中文子字符串 .这样的情况我在工作中遇到非常多, 特梳理总结如下.
难点:
处理GBK和utf8之类的字符编码, 同时正则匹配Pattern中包含汉字,要汉字正常发挥作用,必须非常谨慎.推荐最好统一为utf8编码,如果不是这种最优情况,也有酌情处理.
往往一个具有普适性的正则表达式会简化程序和代码的处理,使过程简洁和事半功倍,这往往是高手和菜鸟最显著的差别。
示例一:
从QQ纯真数据库中解析出省市县等特定词语,这里的正则表达式基本能够满足业务场景,懒惰匹配?非常必要,因为处理不好,会得不到我们想要的效果。个中妙处,还请各位看官自己琢磨,我这里只点到为止!
代码如下:
#!/usr/bin/env python
#encoding: utf-8
#description: 从字符串中提取省市县等名称,用于从纯真库中解析解析地理数据
import re
import sys
reload(sys)
sys.setdefaultencoding('utf8')
#匹配规则必须含有u,可以没有r
#这里第一个分组的问号是懒惰匹配,必须这么做
PATTERN = \
ur'([\u4e00-\u9fa5]{2,5}?(?:省|自治区|市))([\u4e00-\u9fa5]{2,7}?(?:市|区|县|州)){0,1}([\u4e00-\u9fa5]{2,7}?(?:市|区|县)){0,1}'
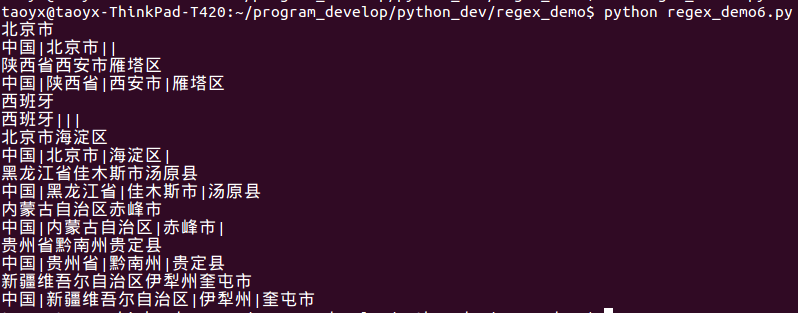
data_list = ['北京市', '陕西省西安市雁塔区', '西班牙', '北京市海淀区', '黑龙江省佳木斯市汤原县', '内蒙古自治区赤峰市',
'贵州省黔南州贵定县', '新疆维吾尔自治区伊犁州奎屯市']
for data in data_list:
data_utf8 = data.decode('utf8')
print data_utf8
country = data
province = ''
city = ''
district = ''
#pattern = re.compile(PATTERN3)
pattern = re.compile(PATTERN)
m = pattern.search(data_utf8)
if not m:
print country + '|||'
continue
#print m.group()
country = '中国'
if m.lastindex >= 1:
province = m.group(1)
if m.lastindex >= 2:
city = m.group(2)
if m.lastindex >= 3:
district = m.group(3)
out = '%s|%s|%s|%s' %(country, province, city, district)
print out
运行截图
示例二:
从ip138中获取指定ip的地理位置等信息。
ip138是我们日常使用较多的ip查询网站,我为了获取每个ip对应的isp信息,需要查询这个页面

我在网上搜索了很久,没有找到ip138返回json之类的接口,只能以这种方式查询,那么我们不可避免地需要解析出上图中红框标注的isp信息。如果使用DOM解析指定div标签之类的常规思路恐怕不太凑效,更简捷的方式是使用中文正则匹配,直接从返回的html中得到“本站主数据:”那部分的信息。
下面是我摸索的代码
#!/usr/bin/env python
#encoding: utf-8
#date: 2016-03-31
#note: 测试中遇到的问题,请求指定的链接会有超时现象,可以多请求几次
import requests, re
import sys
reload(sys)
sys.setdefaultencoding('utf8')
IP138_API = 'http://www.ip138.com/ips138.asp?ip='
PATTERN = ur'<li>本站主数据:(.*?)</li>'
def query_api(url):
data = ''
r = requests.get(url)
if r.status_code == 200:
data = r.content
return data
def parse_ip138(html):
#只能是unicode编码,不能在后面再转换为utf-8,否则无法正则匹配上.
html = unicode(html, 'gb2312')
#html = unicode(html, 'gb2312').encode('utf-8')
#print html
pattern = re.compile(PATTERN)
m = pattern.search(html)
if m:
print m.group(1)
else:
print 'regex match failed'
if __name__ == '__main__':
url = IP138_API + '14.192.60.0'
resp = query_api(url)
if not resp:
print 'no content'
parse_ip138(resp)
下面是截图

PS:这里再为大家提供2款非常方便的正则表达式工具供大家参考使用:
JavaScript正则表达式在线测试工具:
http://tools.jb51.net/regex/javascript
正则表达式在线生成工具:
http://tools.jb51.net/regex/create_reg
更多关于Python相关内容可查看本站专题:《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。