python利用selenium进行浏览器爬虫
前言
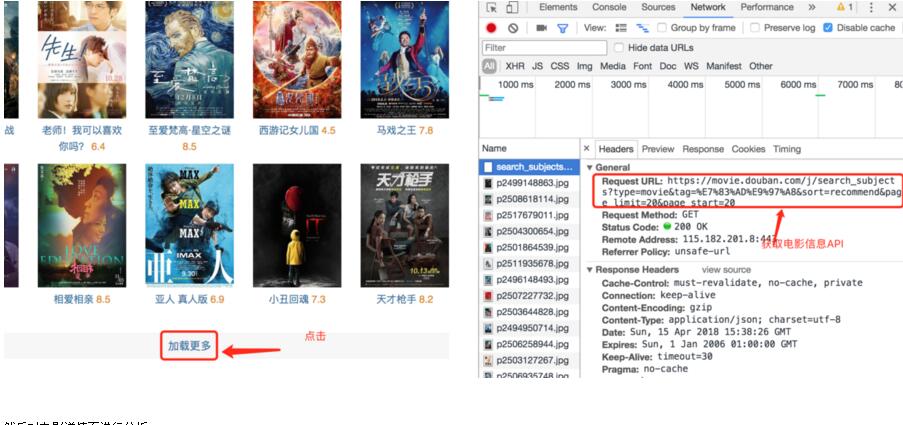
相信大家刚开始在做爬虫的时候,是不是requests和sound这两个库来使用,这样确实有助于我们学习爬虫的知识点,下面来介绍一个算事较复杂的爬虫案例selenium进形打开浏览器爬取网站的信息
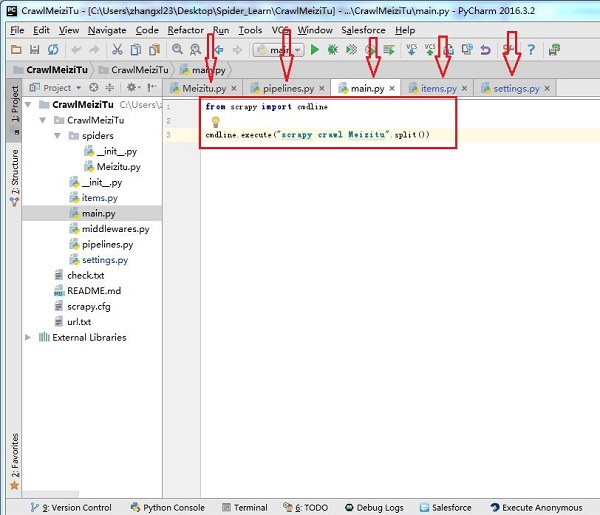
导入第三方库

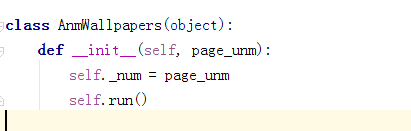
自执行函数
解析信息

保存文件信息
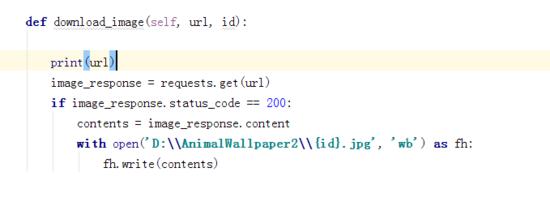
打开浏览器

获取链接信息
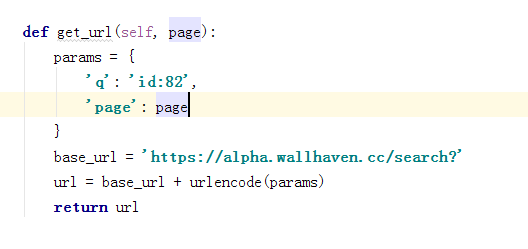
执行函数
运行结果

总结
以上所述是小编给大家介绍的python利用selenium进行浏览器爬虫,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!