TF-IDF算法解析与Python实现方法详解
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。比较容易理解的一个应用场景是当我们手头有一些文章时,我们希望计算机能够自动地进行关键词提取。而TF-IDF就是可以帮我们完成这项任务的一种统计方法。它能够用于评估一个词语对于一个文集或一个语料库中的其中一份文档的重要程度。
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率(另一说:TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数)。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。(另一说:IDF反文档频率(Inverse Document Frequency)是指果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。)但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
为了演示在Python中实现TF-IDF的方法,一些基于自然语言处理的预处理过程也会在本文中出现。如果你对NLTK和Scikit-Learn两个库还很陌生可以参考如下文章:
必要的预处理过程
首先,我们给出需要引用的各种包,以及用作处理对象的三段文本。
import nltk import math import string from nltk.corpus import stopwords from collections import Counter from nltk.stem.porter import * from sklearn.feature_extraction.text import TfidfVectorizer text1 = "Python is a 2000 made-for-TV horror movie directed by Richard \ Clabaugh. The film features several cult favorite actors, including William \ Zabka of The Karate Kid fame, Wil Wheaton, Casper Van Dien, Jenny McCarthy, \ Keith Coogan, Robert Englund (best known for his role as Freddy Krueger in the \ A Nightmare on Elm Street series of films), Dana Barron, David Bowe, and Sean \ Whalen. The film concerns a genetically engineered snake, a python, that \ escapes and unleashes itself on a small town. It includes the classic final\ girl scenario evident in films like Friday the 13th. It was filmed in Los Angeles, \ California and Malibu, California. Python was followed by two sequels: Python \ II (2002) and Boa vs. Python (2004), both also made-for-TV films." text2 = "Python, from the Greek word (πύθων/πύθωνας), is a genus of \ nonvenomous pythons[2] found in Africa and Asia. Currently, 7 species are \ recognised.[2] A member of this genus, P. reticulatus, is among the longest \ snakes known." text3 = "The Colt Python is a .357 Magnum caliber revolver formerly \ manufactured by Colt's Manufacturing Company of Hartford, Connecticut. \ It is sometimes referred to as a \"Combat Magnum\".[1] It was first introduced \ in 1955, the same year as Smith & Wesson's M29 .44 Magnum. The now discontinued \ Colt Python targeted the premium revolver market segment. Some firearm \ collectors and writers such as Jeff Cooper, Ian V. Hogg, Chuck Hawks, Leroy \ Thompson, Renee Smeets and Martin Dougherty have described the Python as the \ finest production revolver ever made."
TF-IDF的基本思想是:词语的重要性与它在文件中出现的次数成正比,但同时会随着它在语料库中出现的频率成反比下降。 但无论如何,统计每个单词在文档中出现的次数是必要的操作。所以说,TF-IDF也是一种基于 bag-of-word 的方法。
首先我们来做分词,其中比较值得注意的地方是我们设法剔除了其中的标点符号(显然,标点符号不应该成为最终的关键词)。
def get_tokens(text): lowers = text.lower() #remove the punctuation using the character deletion step of translate remove_punctuation_map = dict((ord(char), None) for char in string.punctuation) no_punctuation = lowers.translate(remove_punctuation_map) tokens = nltk.word_tokenize(no_punctuation) return tokens
下面的代码用于测试上述分词结果,Counter() 函数用于统计每个单词出现的次数。
tokens = get_tokens(text1) count = Counter(tokens) print (count.most_common(10))
执行上述代码后可以得到如下结果,我们输出了其中出现次数最多的10个词。
[('the', 6), ('python', 5), ('a', 5), ('and', 4), ('films', 3), ('in', 3),
('madefortv', 2), ('on', 2), ('by', 2), ('was', 2)]
显然,像 the, a, and 这些词尽管出现的次数很多,但是它们与文档所表述的主题是无关的,所以我们还要去除“词袋”中的“停词”(stop words),代码如下:
def stem_tokens(tokens, stemmer):
stemmed = []
for item in tokens:
stemmed.append(stemmer.stem(item))
return stemmed
同样,我们来测试一下上述代码的执行效果。
tokens = get_tokens(text1)
filtered = [w for w in tokens if not w in stopwords.words('english')]
count = Counter(filtered)
print (count.most_common(10))
从下面的输出结果你会发现,之前那些缺乏实际意义的 the, a, and 等词已经被过滤掉了。
[('python', 5), ('films', 3), ('film', 2), ('california', 2), ('madefortv', 2),
('genetically', 1), ('horror', 1), ('krueger', 1), ('filmed', 1), ('sean', 1)]
但这个结果还是不太理想,像 films, film, filmed 其实都可以看出是 film,而不应该把每个词型都分别进行统计。这时就需要要用到我们在前面文章中曾经介绍过的 Stemming 方法。代码如下:
tokens = get_tokens(text1)
filtered = [w for w in tokens if not w in stopwords.words('english')]
stemmer = PorterStemmer()
stemmed = stem_tokens(filtered, stemmer)
类似地,我们输出计数排在前10的词汇(以及它们出现的次数):
count = Counter(stemmed) print(count)
上述代码执行结果如下:
Counter({'film': 6, 'python': 5, 'madefortv': 2, 'california': 2, 'includ': 2, '2004': 1,
'role': 1, 'casper': 1, 'robert': 1, 'sequel': 1, 'two': 1, 'krueger': 1,
'ii': 1, 'sean': 1, 'lo': 1, 'clabaugh': 1, 'finalgirl': 1, 'wheaton': 1,
'concern': 1, 'whalen': 1, 'cult': 1, 'boa': 1, 'mccarthi': 1, 'englund': 1,
'best': 1, 'direct': 1, 'known': 1, 'favorit': 1, 'movi': 1, 'keith': 1,
'karat': 1, 'small': 1, 'classic': 1, 'coogan': 1, 'like': 1, 'elm': 1,
'fame': 1, 'malibu': 1, 'sever': 1, 'richard': 1, 'scenario': 1, 'town': 1,
'friday': 1, 'david': 1, 'unleash': 1, 'vs': 1, '2000': 1, 'angel': 1, 'nightmar': 1,
'zabka': 1, '13th': 1, 'jenni': 1, 'seri': 1, 'horror': 1, 'william': 1,
'street': 1, 'wil': 1, 'escap': 1, 'van': 1, 'snake': 1, 'evid': 1, 'freddi': 1,
'bow': 1, 'dien': 1, 'follow': 1, 'engin': 1, 'also': 1})
至此,我们就完成了基本的预处理过程。
TF-IDF的算法原理
预处理过程中,我们已经把停词都过滤掉了。如果只考虑剩下的有实际意义的词,前我们已经讲过,显然词频(TF,Term Frequency)较高的词之于一篇文章来说可能是更为重要的词(也就是潜在的关键词)。但这样又会遇到了另一个问题,我们可能发现在上面例子中,madefortv、california、includ 都出现了2次(madefortv其实是原文中的made-for-TV,因为我们所选分词法的缘故,它被当做是一个词来看待),但这显然并不意味着“作为关键词,它们的重要性是等同的”。
因为”includ”是很常见的词(注意 includ 是 include 的词干)。相比之下,california 可能并不那么常见。如果这两个词在一篇文章的出现次数一样多,我们有理由认为,california 重要程度要大于 include ,也就是说,在关键词排序上面,california 应该排在 include 的前面。
于是,我们需要一个重要性权值调整参数,来衡量一个词是不是常见词。如果某个词比较少见,但是它在某篇文章中多次出现,那么它很可能就反映了这篇文章的特性,它就更有可能揭示这篇文字的话题所在。这个权重调整参数就是“逆文档频率”(IDF,Inverse Document Frequency),它的大小与一个词的常见程度成反比。
知道了 TF 和 IDF 以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。如果用公式来表示,则对于某个特定文件中的词语 ti 而言,它的 TF 可以表示为:
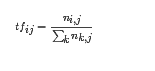
其中 ni,j是该词在文件 dj中出现的次数,而分母则是文件 dj 中所有词汇出现的次数总和。如果用更直白的表达是来描述就是,
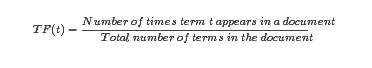
某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数即可:
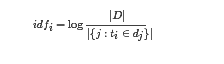
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|。同样,如果用更直白的语言表示就是

最后,便可以来计算 TF-IDF(t)=TF(t)×IDF(t)。
下面的代码实现了计算TF-IDF值的功能。
def tf(word, count): return count[word] / sum(count.values()) def n_containing(word, count_list): return sum(1 for count in count_list if word in count) def idf(word, count_list): return math.log(len(count_list) / (1 + n_containing(word, count_list))) def tfidf(word, count, count_list): return tf(word, count) * idf(word, count_list)
再给出一段测试代码:
countlist = [count1, count2, count3]
for i, count in enumerate(countlist):
print("Top words in document {}".format(i + 1))
scores = {word: tfidf(word, count, countlist) for word in count}
sorted_words = sorted(scores.items(), key=lambda x: x[1], reverse=True)
for word, score in sorted_words[:3]:
print("\tWord: {}, TF-IDF: {}".format(word, round(score, 5)))
输出结果如下:
Top words in document 1 Word: film, TF-IDF: 0.02829 Word: madefortv, TF-IDF: 0.00943 Word: california, TF-IDF: 0.00943 Top words in document 2 Word: genu, TF-IDF: 0.03686 Word: 7, TF-IDF: 0.01843 Word: among, TF-IDF: 0.01843 Top words in document 3 Word: revolv, TF-IDF: 0.02097 Word: colt, TF-IDF: 0.02097 Word: manufactur, TF-IDF: 0.01398
利用Scikit-Learn实现的TF-IDF
因为 TF-IDF 在文本数据挖掘时十分常用,所以在Python的机器学习包中也提供了内置的TF-IDF实现。主要使用的函数就是TfidfVectorizer(),来看一个简单的例子。
>>> corpus = ['This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',]
>>> vectorizer = TfidfVectorizer(min_df=1)
>>> vectorizer.fit_transform(corpus)
<4x9 sparse matrix of type '<class 'numpy.float64'>'
with 19 stored elements in Compressed Sparse Row format>
>>> vectorizer.get_feature_names()
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
>>> vectorizer.fit_transform(corpus).toarray()
array([[ 0. , 0.43877674, 0.54197657, 0.43877674, 0. ,
0. , 0.35872874, 0. , 0.43877674],
[ 0. , 0.27230147, 0. , 0.27230147, 0. ,
0.85322574, 0.22262429, 0. , 0.27230147],
[ 0.55280532, 0. , 0. , 0. , 0.55280532,
0. , 0.28847675, 0.55280532, 0. ],
[ 0. , 0.43877674, 0.54197657, 0.43877674, 0. ,
0. , 0.35872874, 0. , 0.43877674]])
最终的结果是一个 4×9 矩阵。每行表示一个文档,每列表示该文档中的每个词的评分。如果某个词没有出现在该文档中,则相应位置就为 0 。数字 9 表示语料库里词汇表中一共有 9 个(不同的)词。例如,你可以看到在文档1中,并没有出现 and,所以矩阵第一行第一列的值为 0 。单词 first 只在文档1中出现过,所以第一行中 first 这个词的权重较高。而 document 和 this 在 3 个文档中出现过,所以它们的权重较低。而 the 在 4 个文档中出现过,所以它的权重最低。
最后需要说明的是,由于函数 TfidfVectorizer() 有很多参数,我们这里仅仅采用了默认的形式,所以输出的结果可能与采用前面介绍的(最基本最原始的)算法所得出之结果有所差异(但数量的大小关系并不会改变)。有兴趣的读者可以参考这里来了解更多关于在Scikit-Learn中执行 TF-IDF 算法的细节。
总结
以上就是本文关于TF-IDF算法解析与Python实现方法详解的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
Python算法输出1-9数组形成的结果为100的所有运算式
如有不足之处,欢迎留言指出。
记者问一个大爷:大爷,您保持亮丽的秘诀是什么?
大爷说:白天敲代码,晚上撸系统,姿势不要动,眼动手动就可以。
记者:啊?大爷您是做什么工作的?
大爷:敲代码的呀。
记者:那大爷您是本身就很喜欢光头的吗?
大爷:掉光的~