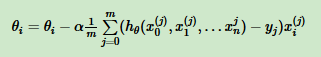Python3 伪装浏览器的方法示例
一、伪装浏览器
对于一些需要登录的网站,如果不是从浏览器发出的请求,则得不到响应。所以,我们需要将爬虫程序发出的请求伪装成浏览器正规军。
具体实现:自定义网页请求报头。
二、使用Fiddler查看请求和响应报头
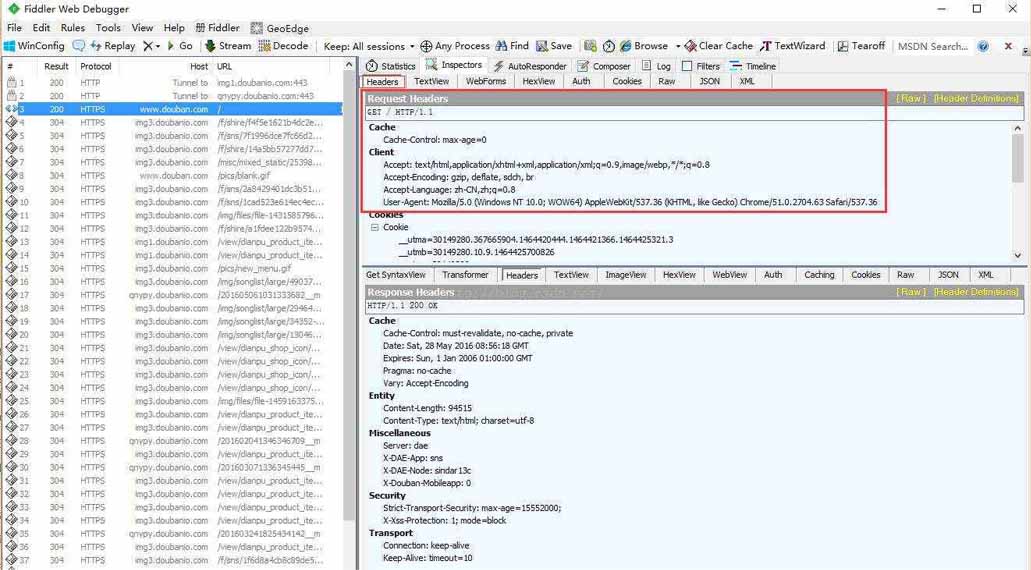
打开工具Fiddler,然后再浏览器访问“https://www.douban.com/”,在Fiddler左侧访问记录中,找到“200 HTTPS www.douban.com”这一条,点击查看其对应的请求和响应报头具体内容:
三、访问豆瓣
我们自定义请求报头与上图Request Headers相同内容:
'''''
伪装浏览器
对于一些需要登录的网站,如果不是从浏览器发出的请求,则得不到响应。
所以,我们需要将爬虫程序发出的请求伪装成浏览器正规军。
具体实现:自定义网页请求报头。
'''
#实例二:依然爬取豆瓣,采用伪装浏览器的方式
import urllib.request
#定义保存函数
def saveFile(data):
path = "E:\\projects\\Spider\\02_douban.out"
f = open(path,'wb')
f.write(data)
f.close()
#网址
url = "https://www.douban.com/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
#也可以把爬取的内容保存到文件中
saveFile(data)
data = data.decode('utf-8')
#打印抓取的内容
print(data)
#打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
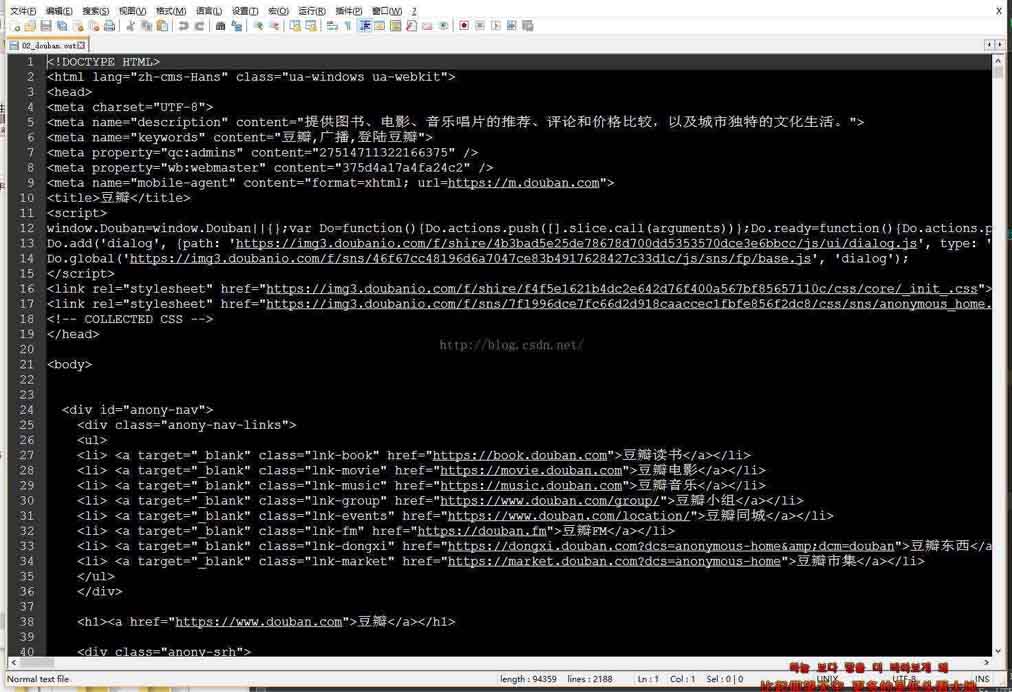
四、输出的结果结果(截取部分)
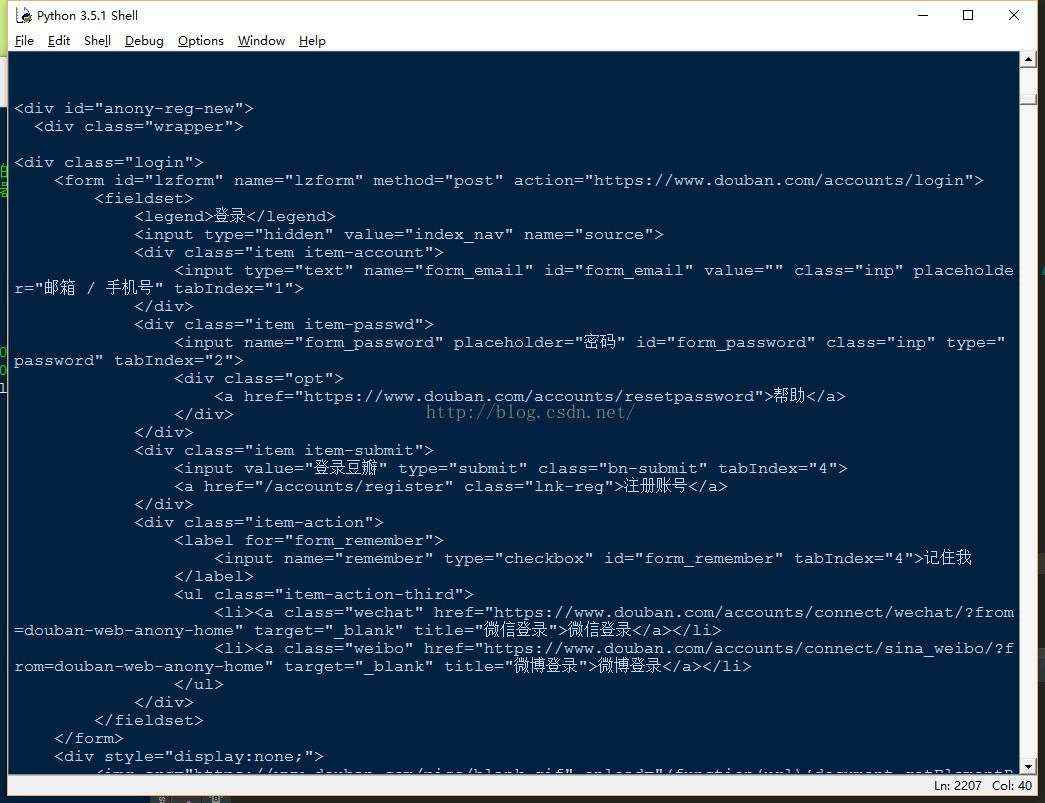
结果文件内容
GitHub代码链接
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。