关于Python数据结构中字典的心得
本篇主要介绍:常见的字典方法、如何处理查不到的键、标准库中 dict 类型的变种、散列表的工作原理等。一下是全部内容:
泛映射类型
collections.abc 模块中有 Mapping 和 MutableMapping 这两个抽象基类,它们的作用是为 dict 和其他类似的类型定义形式接口。
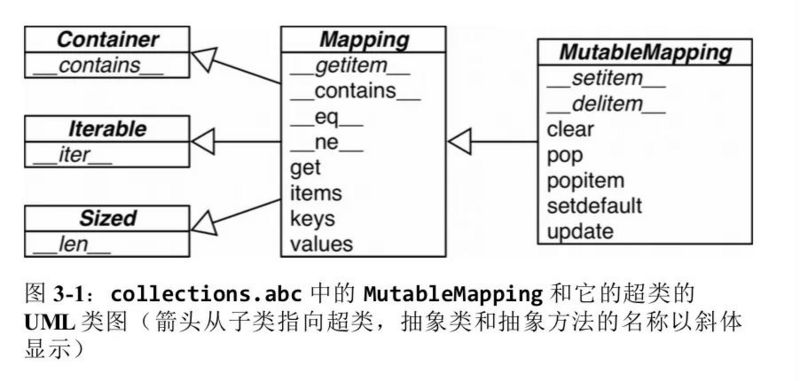
标准库里所有映射类型都是利用 dict 来实现的,它们有个共同的限制,即只有可散列的数据类型才能用做这些映射里的键。
问题: 什么是可散列的数据类型?
在 python 词汇表(https://docs.python.org/3/glossary.html#term-hashable)中,关于可散列类型的定义是这样的:
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现 __hash__() 方法。另外可散列对象还要有 __eq__() 方法,这样才能跟其他键做比较。如果两个可散列对象是相等的,那么它们的散列只一定是一样的
根据这个定义,原子不可变类型(str,bytes和数值类型)都是可散列类型,frozenset 也是可散列的(因为根据其定义,frozenset 里只能容纳可散列类型),如果元组内都是可散列类型的话,元组也是可散列的(元组虽然是不可变类型,但如果它里面的元素是可变类型,这种元组也不能被认为是不可变的)。
一般来讲,用户自定义的类型的对象都是可散列的,散列值就是它们的 id() 函数的返回值,所以这些对象在比较的时候都是不相等的。(如果一个对象实现了 eq 方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的。)
根据这些定义,字典提供了很多种构造方法,https://docs.python.org/3/library/stdtypes.html 这个页面有个例子来说明创建字典的不同方式。
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> a == b == c == d == e
True
除了这些方法以外,还可以用字典推导的方式来建造新 dict。
字典推导
自 Python2.7 以来,列表推导和生成器表达式的概念就移植到了字典上,从而有了字典推导。字典推导(dictcomp)可以从任何以键值对作为元素的可迭代对象中构建出字典。
比如:
>>> data = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> data_dict = {num: letter for num, letter in data}
>>> data_dict
{1: 'a', 2: 'b', 3: 'c'}
常见的映射方法
下表为我们展示了 dict、defaultdict 和 OrderedDict 的常见方法(后两种是 dict 的变种,位于 collections模块内)。
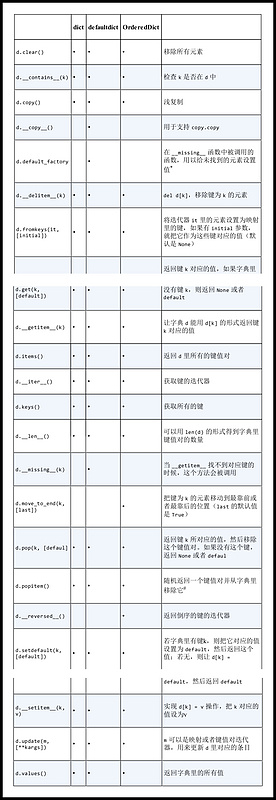
default_factory 并不是一个方法,而是一个可调用对象,它的值 defaultdict 初始化的时候由用户设定。 OrderedDict.popitem() 会移除字典最先插入的元素(先进先出);可选参数 last 如果值为真,则会移除最后插入的元素(后进先出)。用 setdefault 处理找不到的键
当字典 d[k] 不能找到正确的键的时候,Python 会抛出异常,平时我们都使用d.get(k, default) 来代替 d[k],给找不到的键一个默认值,还可以使用效率更高的 setdefault
my_dict.setdefault(key, []).append(new_value) # 等同于 if key not in my_dict: my_dict[key] = [] my_dict[key].append(new_value)
这两段代码的效果一样,只不过,后者至少要进行两次键查询,如果不存在,就是三次,而用 setdefault 只需一次就可以完成整个操作。
那么,我们取值的时候,该如何处理找不到的键呢?
映射的弹性查询
有时候,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。有两个途径能帮我们达到这个目的,一个是通过 defaultdict 这个类型而不是普通的 dict,另一个是给自己定义一个 dict 的子类,然后在子类中实现 __missing__ 方法。
defaultdict:处理找不到的键的一个选择
首先我们看下如何使用 defaultdict :
import collections index = collections.defaultdict(list) index[new_key].append(new_value)
这里我们新建了一个字典 index,如果键 new_key 在 index 中不存在,表达式 index[new_key] 会按以下步骤来操作:
调用 list() 来建立一个新的列表把这个新列表作为值,'new_key' 作为它的键,放入 index 中返回这个列表的引用。
而这个用来生成默认值的可调用对象存放在名为 default_factory 的实例属性中。
defaultdict 中的 default_factory 只会在 getitem 里调用,在其他方法中不会发生作用。比如 index[k] 这个表达式会调用 default_factory 创造的某个默认值,而 index.get(k) 则会返回 None。(这是因为特殊方法 missing 会在 defaultdict 遇到找不到的键的时候调用 default_factory,实际上,这个特性所有映射方法都可以支持)。
特殊方法 missing
所有映射在处理找不到的键的时候,都会牵扯到 missing 方法。但基类 dict 并没有提供 这个方法。不过,如果有一个类继承了 dict ,然后这个继承类提供了 missing 方法,那么在 getitem 碰到找不到键的时候,Python 会自动调用它,而不是抛出一个 KeyError 异常。
__missing__ 方法只会被 __getitem__ 调用。提供 missing 方法对 get 或者 __contains__(in 运算符会用到这个方法)这些方法的是有没有影响。
下面这段代码实现了 StrKeyDict0 类,StrKeyDict0 类在查询的时候把非字符串的键转化为字符串。
class StrKeyDict0(dict): # 继承 dict def __missing__(self, key): if isinstance(key, str): # 如果找不到的键本身就是字符串,抛出 KeyError raise KeyError(key) # 如果找不到的键不是字符串,转化为字符串再找一次 return self[str(key)] def get(self, key, default=None): # get 方法把查找工作用 self[key] 的形式委托给 __getitem__,这样在宣布查找失败钱,还能通过 __missing__ 再给键一个机会 try: return self[key] except KeyError: # 如果抛出 KeyError 说明 __missing__ 也失败了,于是返回 default return default def __contains__(self, key): # 先按传入的键查找,如果没有再把键转为字符串再找一次 return key in self.keys() or str(key) in self.keys()
contains 方法存在是为了保持一致性,因为 k in d 这个操作会调用它,但我们从 dict 继承到的 contains 方法不会在找不到键的时候用 missing 方法。
my_dict.keys() 在 Python3 中返回值是一个 "视图","视图"就像是一个集合,而且和字典一样速度很快。但在 Python2中,my_dict.keys() 返回的是一个列表。 所以 k in my_dict.keys() 操作在 python3中速度很快,但在 python2 中,处理效率并不高。
如果要自定义一个映射类型,合适的策略是继承 collections.UserDict 类。这个类就是把标准 dict 用 python 又实现了一遍,UserDict 是让用户继承写子类的,改进后的代码如下:
import collections class StrKeyDict(collections.UserDict): def __missing__(self, key): if isinstance(key, str): raise KeyError(key) return self[str(key)] def __contains__(self, key): # 这里可以放心假设所有已经存储的键都是字符串。因此只要在 self.data 上查询就好了 return str(key) in self.data def __setitem__(self, key, item): # 这个方法会把所有的键都转化成字符串。 self.data[str(key)] = item
因为 UserDict 继承的是 MutableMapping,所以 StrKeyDict 里剩下的那些映射类型都是从 UserDict、MutableMapping 和 Mapping 这些超类继承而来的。
Mapping 中提供了 get 方法,和我们在 StrKeyDict0 中定义的一样,所以我们在这里不需要定义 get 方法。
字典的变种
在 collections 模块中,除了 defaultdict 之外还有其他的映射类型。
collections.OrderedDict collections.ChainMap collections.Counter 不可变的映射类型
问题:标准库中所有的映射类型都是可变的,如果我们想给用户提供一个不可变的映射类型该如何处理呢?
从 Python3.3 开始 types 模块中引入了一个封装类名叫 MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图(如果原映射做了改动,这个视图的结果页会相应的改变)。例如
>>> from types import MappingProxy Type
>>> d = {1: 'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({1: 'A'})
>>> d_proxy[1]
'A'
>>> d_proxy[2] = 'x'
Traceback(most recent call last):
File "<stdin", line 1, in <module>
TypeError: 'MappingProxy' object does not support item assignment
>>> d[2] = 'B'
>>> d_proxy[2] # d_proxy 是动态的,d 的改动会反馈到它上边
'B'
字典中的散列表
散列表其实是一个稀疏数组(总有空白元素的数组叫稀疏数组),在 dict 的散列表中,每个键值都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
python 会设法保证大概有1/3 的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间。
如果要把一个对象放入散列表,那么首先要计算这个元素的散列值。
Python内置的 hash() 方法可以用于计算所有的内置类型对象。
如果两个对象在比较的时候是相等的,那么它们的散列值也必须相等。例如 1==1.0 那么,hash(1) == hash(1.0)
散列表算法
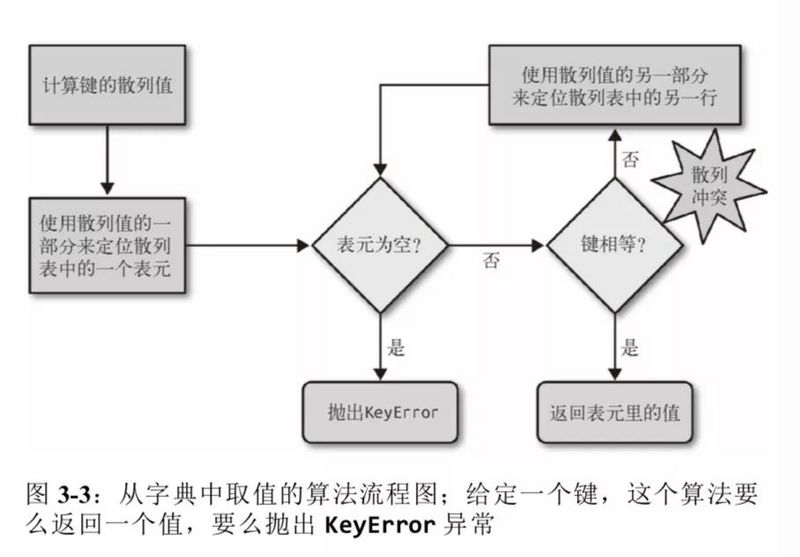
为了获取 my_dict[search_key] 的值,Python 会首先调用 hash(search_key) 来计算 search_key 的散列值,把这个值的最低几位当做偏移量在散列表中查找元。若表元为空,抛出 KeyError 异常。若不为空,则表元会有一对 found_key:found_value。
这时需要校验 search_key == found_key,如果相等,返回 found_value。
如果不匹配(散列冲突),再在散列表中再取几位,然后处理一下,用处理后的结果当做索引再找表元。 然后重复上面的步骤。
取值流程图如下:
添加新值和上述的流程基本一致,只不过对于前者,在发现空表元的时候会放入一个新元素,而对于后者,在找到相应表元后,原表里的值对象会被替换成新值。
另外,在插入新值是,Python 可能会按照散列表的拥挤程度来决定是否重新分配内存为它扩容,如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加字典的优势和限制
1、键必须是可散列的
可散列对象要求如下:
支持 hash 函数,并且通过__hash__() 方法所得的散列值不变支持通过 __eq__() 方法检测相等性若 a == b 为真, 则 hash(a) == hash(b) 也为真
2、字典开销巨大
因为字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上效率低下。
3、键查询很快
dict 的实现是典型的空间换时间:字典类型由着巨大的内存开销,但提供了无视数据量大小的快速访问。
4、键的次序决定于添加顺序
当往 dict 里添加新键而又发生散列冲突时,新建可能会被安排存放在另一个位置。
5、往字典里添加新键可能会改变已有键的顺序
无论何时向字典中添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把原有的键添加到新的散列表中,这个过程中可能会发生新的散列冲突,导致新散列表中次序发生变化。
因此,不要对字典同时进行迭代和修改。