一篇文章搞懂Python的类与对象名称空间
代码块的分类
python中分几种代码块类型,它们都有自己的作用域,或者说名称空间:
文件或模块整体是一个代码块,名称空间为全局范围
函数代码块,名称空间为函数自身范围,是本地作用域,在全局范围的内层
- 函数内部可嵌套函数,嵌套函数有更内一层的名称空间
类代码块,名称空间为类自身
- 类中可定义函数,类中的函数有自己的名称空间,在类的内层
- 类的实例对象有自己的名称空间,和类的名称空间独立
- 类可继承父类,可以链接至父类名称空间
正是这一层层隔离又连接的名称空间将变量、类、对象、函数等等都组织起来,使得它们可以拥有某些属性,可以进行属性查找。
本文详细解释类和对象涉及的名称空间,属于纯理论类的内容,有助于理解python面向对象的细节。期间会涉及全局和本地变量作用域的查找规则,如有不明白之处,可先看文章:Python作用域详述
一个概括全文的示例
以下是一个能在一定程度上概括全文的示例代码段:
x = 11 # 全局变量x def f(): # 全局变量f print(x) # 引用全局变量x def g(): # 全局变量g x = 22 # 定义本地变量x print(x) # 引用本地变量x class supcls(): # 全局变量supcls x = 33 # 类变量x def m(self): # 类变量m,类内函数变量self x = 44 # 类内函数变量x self.x = 55 # 对象变量x class cls(supcls): # 全局变量cls x = supcls.x # 引用父类属性x,并定义cls类属性x def n(self): # 类变量n self.x = 66 # 对象变量x
如果能理解上面的每个x属于哪个作用域、哪个名称空间,本文内容基本上就理解了。
类的名称空间
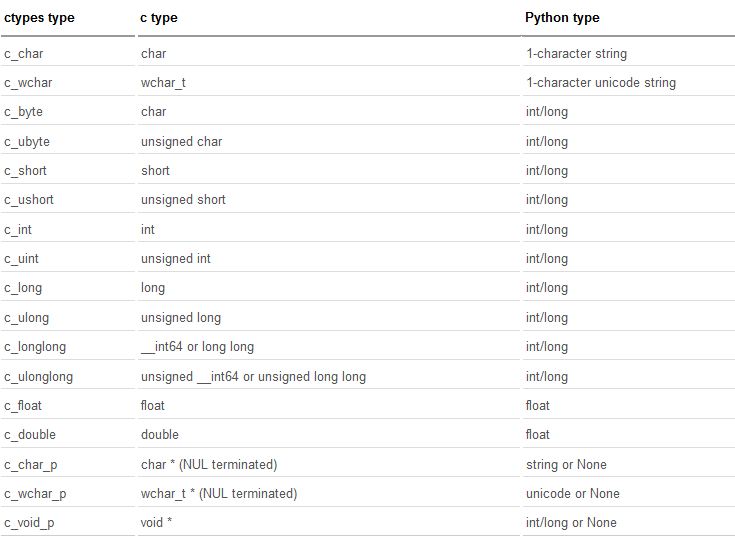
下面有一个类,类中有类属性x、y,有类方法m和n。
class supcls(): x = 3 y = 4 def m(self): x = 33 self.x = 333 self.y = 444 self.z = 555 def n(self): return self.x, self.y, self.z
当python解释到supcls代码块后,知道这是一个类,类有自己的名称空间。所以,当知道了这个类里面有x、y、m、n后,这几个属性都会放进类supcls的名称空间中。
如下图:
在上图中,类的名称空间中有属性x、y、m和n,它们都称为类属性。需要说明的是,在python中,函数变量m、n和普通变量没什么区别,仅仅只是它保存了指向函数体的地址,函数体即上图中用func m和func n所表示的对象。
因为有名称空间,可以直接使用完全限定名称去访问这个名称空间中的内容。例如:
print(supcls.x) print(supcls.y) print(supcls.m) print(supcls.n)
输出结果:
3
4
<function supcls.m at 0x02B83738>
<function supcls.n at 0x02B836F0>
因为函数m和n也是类的属性,它们也可以直接通过类名来访问执行。例如,新加入一个函数,但不用self参数了,然后执行它。
class testcls(): z = 3 def a(): x = 1 print(x) # print(z) # 这是错的 testcls.a()
但是需要注意,类方法代码块中看不见类变量。虽然类和类方法的作用域关系类似于全局作用域和函数本地作用域,但并不总是等价。例如,方法a()中无法直接访问类变量z。这就像类内部看不到全局变量一样。
上面全都是使用类名.属性这种完全限定名称去访问类中的属性的。如果生成类的对象,则可以通过对象去访问相关对象属性,因为对象有自己的名称空间,且部分属性来源于类。
对象名称空间
类就像一个模板,可以根据这个模板大量生成具有自己特性的对象。在Python中,只需像调用函数一样直接调用类就可以创建对象。
例如,下面创建了两个cls类的对象o1和o2,创建类的时候可以传递参数给类,这个参数可以传递给类的构造函数__init__()。
o1 = cls()
o2 = cls("some args")
对象有自己的名称空间。因为对象是根据类来创建的,类是它们的模板,所以对象名称空间中包含所有类属性,但是对象名称空间中这些属性的值不一定和类名称空间属性的值相同。
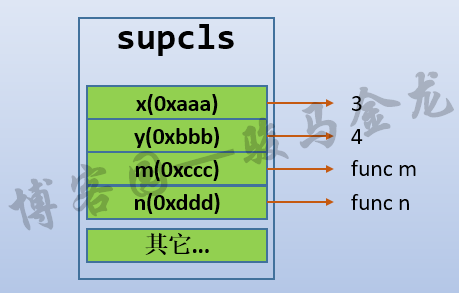
现在根据supcls类构造两个对象s1和s2:
class supcls(): x = 3 y = 4 def m(self): x = 33 self.x = 333 self.y = 444 self.z = 555 def n(self): return self.x, self.y, self.z s1 = supcls() s2 = supcls()
那么它们的名称空间,以及类的名称空间的关系如下图所示:
现在仅仅只是对象s1、s2连接到了类supcls,对象s1和s2有自己的名称空间。但因为类supcls中没有构造方法__init__()初始化对象属性,所以它们的名称空间中除了python内部设置的一些"其它"属性,没有任何属于自己的属性。
但因为s1、s2连接到了supcls类,所以可以进行对象属性查找,如果对象中没有,将会向上找到supcls。例如:
print(s1.x) # 输出3,搜索到类名称空间 print(s1.y) # 输出4,搜索到类名称空间 # print(s1.z) # 这是错的
上面不再是通过完全限定的名称去访问类中的属性,而是通过对象属性查找的方式搜索到了类属性。但上面访问z属性将报错,因为还没有调用m方法。
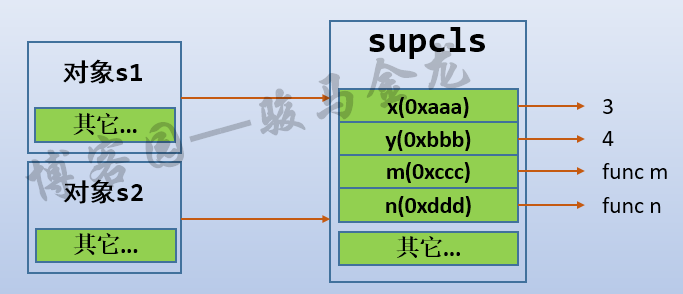
当调用m方法后,将会通过self.xxx的方式设置完全属于对象自身的属性,包括x、y、z。
s1.m() s2.m()
现在,它们的名称空间以及类的名称空间的关系如下图所示:
现在对象名称空间中有x、y和z共3个属性(不考虑其它python内部设置的属性),再通过对象名去访问对象属性,仍然会查找属性,但对于这3个属性的搜索不会进一步搜索到类的名称空间。但如果访问对象中没有的属性,比如m和n,它们不存在于对象的名称空间中,所以会搜索到类名称空间。
print(s1.x) # 对象属性333,搜索到对象名称空间 print(s1.y) # 对象属性444,搜索到对象名称空间 print(s1.z) # 对象属性555,搜索到对象名称空间 s1.m() # 搜索到类名称空间 s1.n() # 搜索到类名称空间
对象与对象之间的名称空间是完全隔离的,对象与类之间的名称空间存在连接关系。所以,s1和s2中的x和y和z是互不影响的,谁也看不见谁。
但现在想要访问类变量x、y,而不是对象变量,该怎么办?直接通过类名的完全限定方式即可:
print(s1.x) # 输出333,对象属性,搜索到对象名称空间 print(supcls.x) # 输出3,类属性,搜索到类名称空间
因为对象有了自己的名称空间,就可以直接向这个名称空间添加属性或设置属性。例如,下面为s1对象添加一个新的属性,但并不是在类内部设置,而是在类的外部设置:
s1.x = 3333 # 在外部设置已有属性x s1.var1 = "aaa" # 在外部添加新属性var1
新属性var1将只存在于s1,不存在于s2和类supcls中。
类属性和对象属性
属于类的属性称为类属性,即那些存在于类名称空间的属性。类属性分为类变量和类方法。有些类方法无法通过对象来调用,这类方法称为称为静态方法。
类似的,属于对象名称空间的属性称为对象属性。对象属性脱离类属性,和其它对象属性相互隔离。
例如:
class cls: x=3 def f(): y=4 print(y) def m(self): self.z=3
上面的x、f、m都是类属性,x是类变量,f和m是类方法,z是对象属性。
- x可以通过类名和对象名来访问。
- f没有参数,不能通过对象来调用(通过对象调用时默认会传递对象名作为方法的第一个参数),只能通过类名来调用,所以f属于静态方法。
- m可以通过对象名来调用,也可以通过类名来调用(但这很不伦不类,因为你要传递一个本来应该是实例名称的参数)。
- z通过self设置,独属于每个self参数代表的对象,所以是对象属性。
子类继承时的名称空间
子类和父类之间有继承关系,它们的名称空间也通过一种特殊的方式进行了连接:子类可以继承父类的属性。
例如下面的例子,子类class childcls(supcls)表示childcls继承了父类supcls。
class supcls(): x = 3 y = 4 def m(self): x = 33 self.x = 333 self.y = 444 self.z = 555 def n(self): return self.x, self.y, self.z class childcls(supcls): y = supcls.y + 1 # 通过类名访问父类属性 def n(self): self.z = 5555
当python解释完这两段代码块时,初始时的名称空间结构图如下:
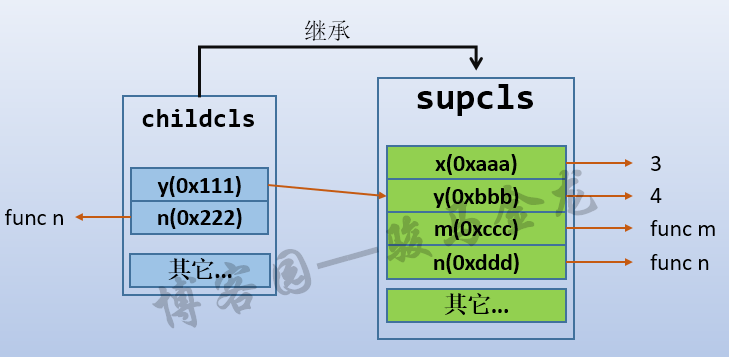
当执行完class childcls(supcls)代码块之后,子类childcls就有了自己的名称空间。初始时,这个名称空间中除了连接到父类supcls外,还有自己的类变量y和方法n(),子类中的方法n()重写了父类supcls的方法n()。
因为有自己的名称空间,所以可以访问类属性。当访问的属性不存在于子类中时,将自动向上搜索到父类。
print(childcls.x) # 父类属性,搜索到父类名称空间 print(childcls.y) # 子类自身属性,搜索到子类名称空间 print(childcls.z) # 错误,子类和父类都没有该属性
当创建子类对象的时候,子类对象的变量搜索规则:
- 子类对象自身名称空间
- 子类的类名称空间
- 父类的类名称空间
例如,创建子类对象c1,并调用子类的方法n():
c1 = childcls() c1.n()
现在,子类对象c1、子类childcls和父类supcls的关系如下图所示:
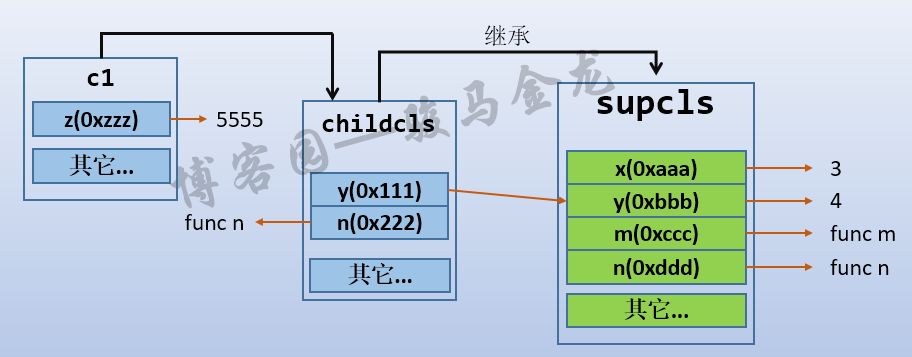
通过前面的说明,想必已经不用过多解释。
多重继承时的名称空间
python支持多重继承,只需将需要继承的父类放进子类定义的括号中即可。
class cls1(): ... class cls2(): ... class cls3(cls1,cls2): ...
上面cls3继承了cls1和cls2,它的名称空间将连接到两个父类名称空间,也就是说只要cls1或cls2拥有的属性,cls3构造的对象就拥有(注意,cls3类是不拥有的,只有cls3类的对象才拥有)。
但多重继承时,如果cls1和cls2都具有同一个属性,比如cls1.x和cls2.x,那么cls3的对象c3.x取哪一个?会取cls1中的属性x,因为规则是按照(括号中)从左向右的方式搜索父类。
再考虑一个问题,如果cls1中没有属性x,但它继承自cls0,而cls0有x属性,那么,c3.x取哪个属性。
在python中,父类属性的搜索规则是先左后右,先深度后广度,搜索到了就停止。
如下图:
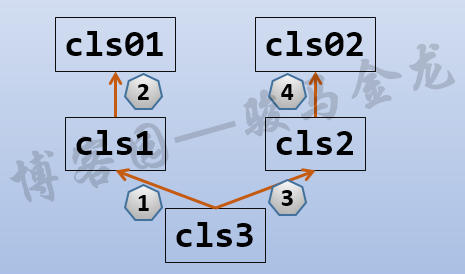
一般不建议使用多重继承,甚至不少语言根本就不支持多重继承,因为很容易带来属性混乱的问题。
类自身就是一个全局属性
在python中,类并没有什么特殊的,它存在于模块文件中,是全局名称空间中的一个属性。
例如,在模块文件中定义了一个类cls,那么这个cls就是一个全局变量,只不过这个变量中保存的地址是类代码块所在数据对象。
# 模块文件顶层 class cls(): n = 3
而模块本身是一个对象,有自己的模块对象名称空间(即全局名称空间),所以类是这个模块对象名称空间中的一个属性,仅此而已。
另外需要注意的是,类代码块和函数代码块不一样,涉及到类代码块中的变量搜索时,只会根据对象与类的连接、子类与父类的继承连接进行搜索。不会像全局变量和函数一样,函数内可以向上搜索全局变量、嵌套函数可以搜索外层函数。
例如:
# 全局范围 x = 3 def f(): print(x) # 搜索到全局变量x class sup(): # print(x) # 这是错的,不会搜索全局变量 y = 3 print(y) # 这是对的,存在类属性y def m(self): # print(y) # 这是错的,不会搜索到类变量 self.z = 4 class childcls(sup): # print(y) # 这是错的,不会搜索到父类
其实很容易理解为什么面向对象要有自己的搜索规则。对象和类之间是is a的关系,子类和父类也是is a的关系,这两个is a是面向对象时名称空间之间的连接关系,在搜索属性的时候可以顺着"这根树"不断向上爬,直到搜索到属性。
__dict__就是名称空间
前面一直说名称空间,这个抽象的东西用来描述作用域,比如全局作用域、本地作用域等等。
在其他语言中可能很难直接查看名称空间,但是在python中非常容易,因为只要是数据对象,只要有属性,就有自己的__dict__属性,它是一个字典,表示的就是名称空间。__dict__内的所有东西,都可以直接通过点"."的方式去访问、设置、删除,还可以直接向__dict__中增加属性。
例如:
class supcls():
x=3
class childcls(supcls):
y=4
def f(self):
self.z=5
>>> c=childcls()
>>> c.__dict__.keys()
dict_keys([])
>>> c.f()
>>> c.__dict__
{'z': 5}
可以直接去增、删、改这个dict,所作的修改都会直接对名称空间起作用。
>>> c.newkey = "NEWKEY"
>>> c.__dict__["hello"] = "world"
>>> c.__dict__
{'z': 5, 'newkey': 'NEWKEY', 'hello': 'world'}
注意,__dict__表示的是名称空间,所以不会显示类的属性以及父类的属性。正如上面刚创建childcls的实例时,dict中是空的,只有在c.f()之后才设置独属于对象的属性。
如果要显示类以及继承自父类的属性,可以使用dir()。
例如:
>>> c1 = childcls()
>>> c1.__dict__
{}
>>> dir(c1)
['__class__', '__delattr__', '__dict__',
......
'f', 'x', 'y']
关于__dict__和dir()的详细说明和区别,参见dir()和__dict__的区别。
__class__和__base__
前面多次提到对象和类之间有连接关系,子类与父类也有连接关系。但是到底是怎么连接的?
对象与类之间,通过__class__进行连接:对象的__class__的值为所属类的名称
子类与父类之间,通过__bases__进行连接:子类的__bases__的值为父类的名称
例如:
class supcls(): x=3 class childcls(supcls): y=4 def f(self): self.z=5 c = childcls()
c是childcls类的一个实例对象:
>>> c.__class__ <class '__main__.childcls'>
childcls继承自父类supcls,父类supcls继承自祖先类object:
>>> childcls.__bases__ (<class '__main__.supcls'>,) >>> supcls.__bases__ (<class 'object'>,)
查看类的继承层次
下面通过__class__和__bases__属性来查看对象所在类的继承树结构。
代码如下:
def classtree(cls, indent):
print("." * indent + cls.__name__)
for supcls in cls.__bases__:
classtree(supcls, indent + 3)
def objecttree(obj):
print("Tree for %s" % obj)
classtree(obj.__class__, 3)
class A: pass
class B(A): pass
class C(A): pass
class D(B, C): pass
class E: pass
class F(D, E): pass
objecttree(B())
print("==============")
objecttree(F())
运行结果:
Tree for <__main__.B object at 0x037D1630>
...B
......A
.........object
==============
Tree for <__main__.F object at 0x037D1630>
...F
......D
.........B
............A
...............object
.........C
............A
...............object
......E
.........object
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对【听图阁-专注于Python设计】的支持。