python 计算数组中每个数字出现多少次--“Bucket”桶的思想
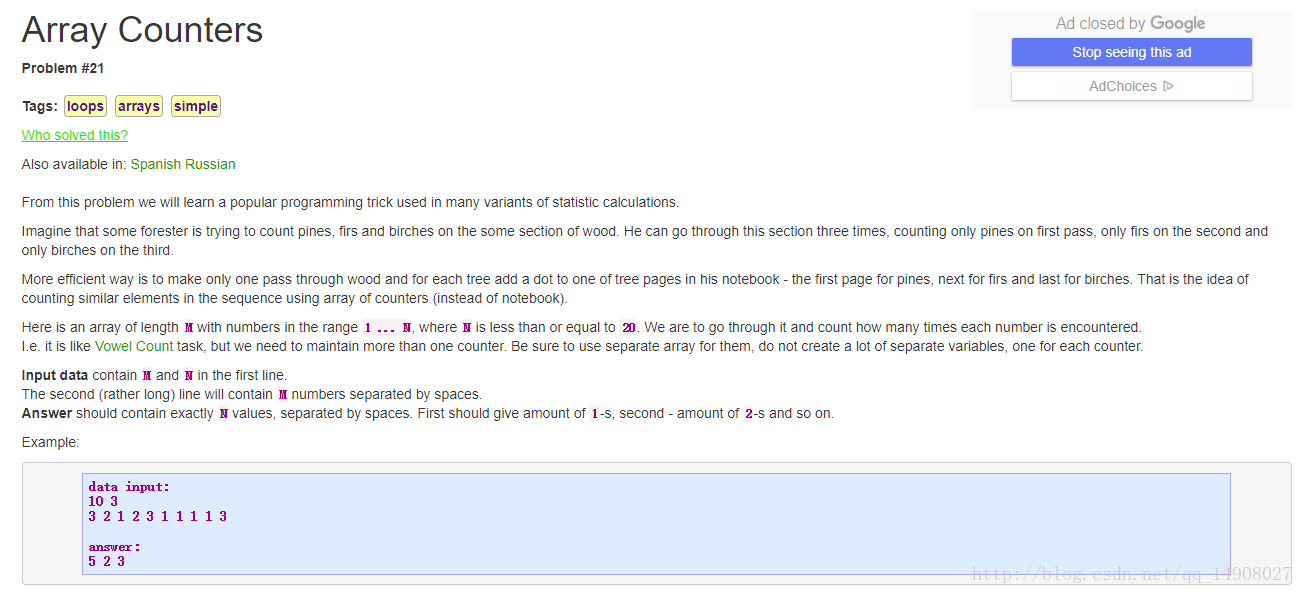
题目:
解法一:比较元素是否相等
思路说明:
这种应该是普通人最先想到的解法,先获取到数组之后进行有小到大排序,然后初始化一个min=0(代表新数字的开始角标),然后遍历新数组的每一个元素,如果两个元素不相等,count等于i-min,然后再把i赋值给min,当i遍历到最后一个元素时,count等于数组长度-min(这里的min是上一轮循环后最后一组数字的第一个元素的角标),当然这种解法面试官不会喜欢?
(m, n) = input().split()
ar = [int(x) for x in input().split()]
res = []
ar.sort()
min = 0
for i in range(1,len(ar)) :
if ar[i-1] != ar[i]:
count = i - min
min = i
res.append(str(count))
if i == (len(ar)-1):
count = len(ar)-min
res.append(str(count))
print(' '.join(res))
解法二:桶计算
思路:获取到输入的数组之后,获取该数组的长度,因为根据题目N<=20,也就是说数组的元素不会超过20,那么我们定义一个1维,长度为20的数组res,并初始化元素为0是足够的。先上代码,再进行解析
(m, n) = input().split()
ar = [int(x) for x in input().split()]
result = []
res = [0 for x in range(20)]
for a in ar:
res[a-1]+=1
for r in res:
if r != 0:
result.append(str(r))
print(' '.join(result))
以上的而核心代码就在于这两行
for a in ar: res[a-1]+=1
我们遍历输入的数组ar的每一个元素,用res[a]的数值代表a出现的次数,我们每次循环,总能找到合适的桶存放a,那么我们直接+1即可,比如说ar = [2, 2, 1, 4]
循环1: a = 2 res[2] = 0+1 = 1 循环2: a = 2 res[2] = 1 +1 =2 循环3: a = 1 res[1] = 0+1 = 1 循环4: a = 4 res[4] = 0+1 = 1 这样我们得到的 res = [0, 1 ,2 ,0 ,1 ,0 ····]
延伸:桶排序
根据以上的思路我们得到了一个新的数组res,仔细分析这个数组的意思,1出现1次,2出现2次,4出现1次,因为数组的特性保证元素的角标是从小到大排序,这就衍生出了桶排序的概念,忽略0的情况,用两个循环,外层循环遍历len(res)次,角标为i,内层循环遍历res[i]次,角标为j,意思就是有几个输出几个,例如1有1个,那就输出1个,2有两个,就循环两次,输出两次,4有1个,就输出一个,扩展代码如下:
#省略上述代码
for i in range(len(res)):
if res[i] != 0:
for j in range(res[i]):
result.append(i)
print(result)
执行结果如下:
