快速查询Python文档方法分享
Pydoc本地HTML形式查看
我们在编写Python代码时,常常会去查询某些模块及函数的使用,会选择dir()及help()函数、或查看CHM格式的Python帮助文档、或查看Python对应文件的源码、或网上搜索等方式。
这边提供一个本地快速查询Python文档的方式:将pydoc文档以本地HTML形式来查看;不论是Python内建模块,还是你本机已下载的三方模块,都能查看得到,且能定位到你本机的文件地址。
先来看下HTML页面的显示,首页如下,可使用浏览器CTRL+F搜索当前页面,快速定位到你要查询的模块。

下面说下具体实现方式,其实很容易。CMD 窗口,DOS下输入命令行 python -m pydoc -p 7777
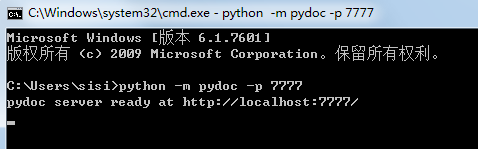
7777为本机端口号,也可改成其他端口号;然后浏览器中访问http://localhost:{端口号}/,如http://localhost:7777/即可
你也可以把该命令行写成批处理格式bat方便快速启动。
总结
以上就是本文关于本地快速查询Python文档方法分享的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
