python爬虫神器Pyppeteer入门及使用
前言
提起selenium想必大家都不陌生,作为一款知名的Web自动化测试框架,selenium支持多款主流浏览器,提供了功能丰富的API接口,经常被我们用作爬虫工具来使用。但是selenium的缺点也很明显,比如速度太慢、对版本配置要求严苛,最麻烦是经常要更新对应的驱动。
今天就给大家介绍另一款web自动化测试工具Pyppeteer,虽然支持的浏览器比较单一,但在安装配置的便利性和运行效率方面都要远胜selenium。
01.Pyppeteer简介
介绍Pyppeteer之前先说一下Puppeteer,Puppeteer是谷歌出品的一款基于Node.js开发的一款工具,主要是用来操纵Chrome浏览器的 API,通过Javascript代码来操纵Chrome浏览器,完成数据爬取、Web程序自动测试等任务。
Pyppeteer其实是Puppeteer的Python版本,下面简单介绍下Pyppeteer的两大特点,chromium浏览器和asyncio框架:
1).chromium
Chromium是一款独立的浏览器,是Google为发展自家的浏览器Google Chrome而开启的计划,相当于Chrome的实验版,Chromium的稳定性不如Chrome但是功能更加丰富,而且更新速度很快,通常每隔数小时就有新的开发版本发布。
Pyppeteer的web自动化是基于chromium来实现的,由于chromium中某些特性的关系,Pyppeteer的安装配置非常简单,关于这一点稍后我们会详细介绍。
2).asyncio
asyncio是Python的一个异步协程库,自3.4版本引入的标准库,直接内置了对异步IO的支持,号称是Python最有野心的库,官网上有非常详细的介绍:
02.安装与使用
1).极简安装
使用pip install pyppeteer命令就能完成pyppeteer库的安装,至于chromium浏览器,只需要一条pyppeteer-install命令就会自动下载对应的最新版本chromium浏览器到pyppeteer的默认位置。
如果不运行pyppeteer-install命令,在第一次使用pyppeteer的时候也会自动下载并安装chromium浏览器,效果是一样的。总的来说,pyppeteer比起selenium省去了driver配置的环节。
当然,出于某种原因,也可能会出现chromium自动安装无法顺利完成的情况,这时可以考虑手动安装:首先,从下列网址中找到自己系统的对应版本,下载chromium压缩包;
- 'linux': 'https://storage.googleapis.com/chromium-browser-snapshots/Linux_x64/575458/chrome-linux.zip'
- 'mac': 'https://storage.googleapis.com/chromium-browser-snapshots/Mac/575458/chrome-mac.zip'
- 'win32': 'https://storage.googleapis.com/chromium-browser-snapshots/Win/575458/chrome-win32.zip'
- 'win64': 'https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/575458/chrome-win32.zip'
然后,将压缩包放到pyppeteer的指定目录下解压缩,windows系统的默认目录。其他系统下的默认目录可以参照下面这幅图:

2).使用
安装完后就来试试效果。一起来看下面这段代码,在main函数中,先是建立一个浏览器对象,然后打开新的标签页,访问百度主页,对当前页面截图并保存为“example.png”,最后关闭浏览器。前文也提到过,pyppeteer是基于asyncio构建的,所以在使用的时候需要用到async/await结构。

运行上面这段代码会发现并没有浏览器弹出运行,这是因为Pyppeteer默认使用的是无头浏览器,如果想要浏览器显示,需要在launch函数中设置参数“headless =False”,程序运行结束后在同一目录下会出现截取到的网页图片:

03.实战异步基金爬取
我们前面一直在说Pyppeteer是一款非常高效的web自动化测试工具,其本质原因是由于Pyppeteer是基于asyncio构建的,它的所有属性和方法几乎都是coroutine对象,因此在构建异步程序的时候非常方便,天生就支持异步运行。
下面就来对比顺序执行和异步运行的效率究竟如何:
1).基金爬取
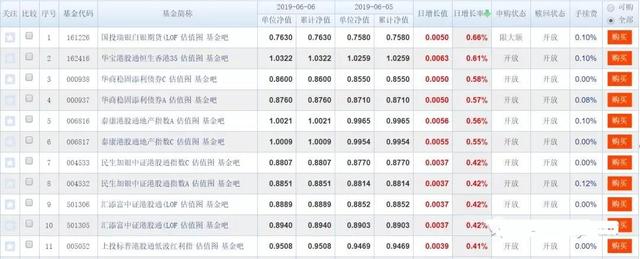
我们把天天基金网中的开放式基金净值数据爬取作为本次的实验任务,下面这张图是一支基金的历史净值数据,这个页面是js加载的,没办法通过requests直接获取内容信息,因此可以考虑使用模拟浏览器操作的方式进行数据抓取。(事实上基金净值数据的获取是有API接口的,本次任务只是为了演示,不具备实用价值)

为了使效果更加明显,我们此次爬取基金列表页(下图)前50支基金的近20个交易日的净值数据。
2).顺序执行
程序构建的基本思路是新建一个browser浏览器和一个页面page,依次访问每个基金的净值数据页面并爬取数据。核心代码如下:
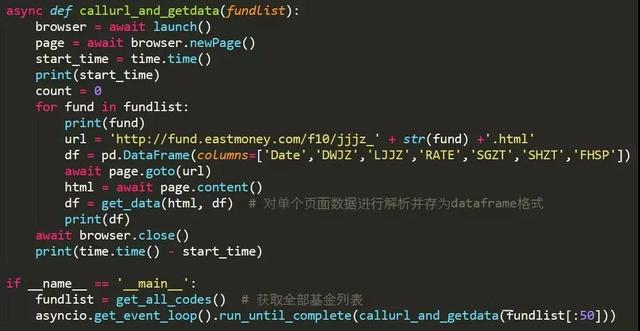
代码中的get_data()函数用于净值数据页面解析和数据的转化,get_all_codes()函数用于获取全部开放式基金的基金代码(共6000余个)。虽然程序也使用了async/await的结构,但是对多个基金的净值数据获取都是在callurl_and_getdata()函数中顺序执行的,之所以这样写是因为pyppeteer中的方法都是coroutine对象,必须以这种形式构建程序。
为了排除打开浏览器的耗时干扰,我们仅统计访问页面和数据抓取的用时,其结果为:12.08秒。
3).异步执行
下面我们把程序改造一下,功能函数都不变,主要是把对fundlist的循环运行改装成async的task对象。核心代码如下:
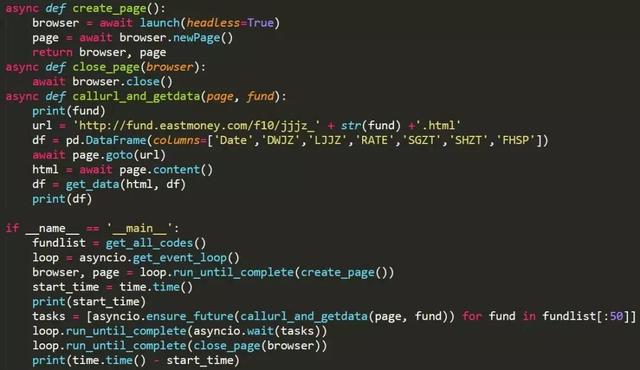
耗时的统计区间仍然从浏览器打开后开始计算,其运行用时为:2.18秒,相比顺序执行要快了6倍。可以想象,如果需要爬取的工作量比较大,顺序执行需要10个小时的话,异步执行可能只需要不到2个小时,优化效果可谓非常明显了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。