Python用 KNN 进行验证码识别的实现方法
前言
之前做了一个校园交友的APP,其中一个逻辑是通过用户的教务系统来确认用户是一名在校大学生,基本的想法是通过用户的账号和密码,用爬虫的方法来确认信息,但是许多教务系统都有验证码,当时是通过本地服务器去下载验证码,然后分发给客户端,然后让用户自己填写验证码,与账号密码一并提交给服务器,然后服务器再去模拟登录教务系统以确认用户能否登录该教务系统。验证码无疑让我们想使得用户快速认证的想法破灭了,但是当时也没办法,最近看了一些机器学习的内容,觉得对于大多数学校的那些极简单的验证码应该是可以用KNN这种方法来破解的,于是整理了一下思绪,撸起袖子做起来!
分析
我们学校的验证码是这样的: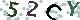 ,其实就是简单地把字符进行旋转然后加上一些微弱的噪点形成的。我们要识别,就得逆行之,具体思路就是,首先二值化去掉噪点,然后把单个字符分割出来,最后旋转至标准方向,然后从这些处理好的图片中选出模板,最后每次新来一张验证码就按相同方式处理,然后和这些模板进行比较,选择判别距离最近的一个模板作为其判断结果(亦即KNN的思想,本文取K=1)。接下来按步骤进行说明。
,其实就是简单地把字符进行旋转然后加上一些微弱的噪点形成的。我们要识别,就得逆行之,具体思路就是,首先二值化去掉噪点,然后把单个字符分割出来,最后旋转至标准方向,然后从这些处理好的图片中选出模板,最后每次新来一张验证码就按相同方式处理,然后和这些模板进行比较,选择判别距离最近的一个模板作为其判断结果(亦即KNN的思想,本文取K=1)。接下来按步骤进行说明。
获得验证码
首先得有大量的验证码,我们通过爬虫来实现,代码如下
#-*- coding:UTF-8 -*-
import urllib,urllib2,cookielib,string,Image
def getchk(number):
#创建cookie对象
cookie = cookielib.LWPCookieJar()
cookieSupport= urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(cookieSupport, urllib2.HTTPHandler)
urllib2.install_opener(opener)
#首次与教务系统链接获得cookie#
#伪装browser
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip,deflate',
'Accept-Language':'zh-CN,zh;q=0.8',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36'
}
req0 = urllib2.Request(
url ='http://mis.teach.ustc.edu.cn',
headers = headers #请求头
)
# 捕捉http错误
try :
result0 = urllib2.urlopen(req0)
except urllib2.HTTPError,e:
print e.code
#提取cookie
getcookie = ['',]
for item in cookie:
getcookie.append(item.name)
getcookie.append("=")
getcookie.append(item.value)
getcookie = "".join(getcookie)
#修改headers
headers["Origin"] = "http://mis.teach.ustc.edu.cn"
headers["Referer"] = "http://mis.teach.ustc.edu.cn/userinit.do"
headers["Content-Type"] = "application/x-www-form-urlencoded"
headers["Cookie"] = getcookie
for i in range(number):
req = urllib2.Request(
url ="http://mis.teach.ustc.edu.cn/randomImage.do?date='1469451446894'",
headers = headers #请求头
)
response = urllib2.urlopen(req)
status = response.getcode()
picData = response.read()
if status == 200:
localPic = open("./source/"+str(i)+".jpg", "wb")
localPic.write(picData)
localPic.close()
else:
print "failed to get Check Code "
if __name__ == '__main__':
getchk(500)
这里下载了500张验证码到source目录下面。如图:

二值化
matlab丰富的图像处理函数能给我们省下很多时间,,我们遍历source文件夹,对每一张验证码图片进行二值化处理,把处理过的图片存入bw目录下。代码如下
mydir='./source/'; bw = './bw/'; if mydir(end)~='\' mydir=[mydir,'\']; end DIRS=dir([mydir,'*.jpg']); %扩展名 n=length(DIRS); for i=1:n if ~DIRS(i).isdir img = imread(strcat(mydir,DIRS(i).name )); img = rgb2gray(img);%灰度化 img = im2bw(img);%0-1二值化 name = strcat(bw,DIRS(i).name) imwrite(img,name); end end
处理结果如图:

分割
mydir='./bw/'; letter = './letter/'; if mydir(end)~='\' mydir=[mydir,'\']; end DIRS=dir([mydir,'*.jpg']); %扩展名 n=length(DIRS); for i=1:n if ~DIRS(i).isdir img = imread(strcat(mydir,DIRS(i).name )); img = im2bw(img);%二值化 img = 1-img;%颜色反转让字符成为联通域,方便去除噪点 for ii = 0:3 region = [ii*20+1,1,19,20];%把一张验证码分成四个20*20大小的字符图片 subimg = imcrop(img,region); imlabel = bwlabel(subimg); % imshow(imlabel); if max(max(imlabel))>1 % 说明有噪点,要去除 % max(max(imlabel)) % imshow(subimg); stats = regionprops(imlabel,'Area'); area = cat(1,stats.Area); maxindex = find(area == max(area)); area(maxindex) = 0; secondindex = find(area == max(area)); imindex = ismember(imlabel,secondindex); subimg(imindex==1)=0;%去掉第二大连通域,噪点不可能比字符大,所以第二大的就是噪点 end name = strcat(letter,DIRS(i).name(1:length(DIRS(i).name)-4),'_',num2str(ii),'.jpg') imwrite(subimg,name); end end end
处理结果如图:

旋转
接下来进行旋转,哪找一个什么标准呢?据观察,这些字符旋转不超过60度,那么在正负60度之间,统一旋转至字符宽度最小就行了。代码如下
if mydir(end)~='\' mydir=[mydir,'\']; end DIRS=dir([mydir,'*.jpg']); %扩展名 n=length(DIRS); for i=1:n if ~DIRS(i).isdir img = imread(strcat(mydir,DIRS(i).name )); img = im2bw(img); minwidth = 20; for angle = -60:60 imgr=imrotate(img,angle,'bilinear','crop');%crop 避免图像大小变化 imlabel = bwlabel(imgr); stats = regionprops(imlabel,'Area'); area = cat(1,stats.Area); maxindex = find(area == max(area)); imindex = ismember(imlabel,maxindex);%最大连通域为1 [y,x] = find(imindex==1); width = max(x)-min(x)+1; if width<minwidth minwidth = width; imgrr = imgr; end end name = strcat(rotate,DIRS(i).name) imwrite(imgrr,name); end end
处理结果如图,一共2000个字符的图片存在rotate文件夹中

模板选取
现在从rotate文件夹中选取一套模板,涵盖每一个字符,一个字符可以选取多个图片,因为即使有前面的诸多处理也不能保证一个字符的最终呈现形式只有一种,多选几个才能保证覆盖率。把选出来的模板图片存入samples文件夹下,这个过程很耗时耗力。可以找同学帮忙~,如图

测试
测试代码如下:首先对测试验证码进行上述操作,然后和选出来的模板进行比较,采用差分值最小的模板作为测试样本的字符选择,代码如下
% 具有差分最小值的图作为答案
mydir='./test/';
samples = './samples/';
if mydir(end)~='\'
mydir=[mydir,'\'];
end
if samples(end)~='\'
samples=[samples,'\'];
end
DIRS=dir([mydir,'*.jpg']); %扩展?
DIRS1=dir([samples,'*.jpg']); %扩展名
n=length(DIRS);%验证码总图数
singleerror = 0;%单个错误
uniterror = 0;%一张验证码错误个数
for i=1:n
if ~DIRS(i).isdir
realcodes = DIRS(i).name(1:4);
fprintf('验证码实际字符:%s\n',realcodes);
img = imread(strcat(mydir,DIRS(i).name ));
img = rgb2gray(img);
img = im2bw(img);
img = 1-img;%颜色反转让字符成为联通域
subimgs = [];
for ii = 0:3
region = [ii*20+1,1,19,20];%奇怪,为什么这样才能均分?
subimg = imcrop(img,region);
imlabel = bwlabel(subimg);
if max(max(imlabel))>1 % 说明有杂点
stats = regionprops(imlabel,'Area');
area = cat(1,stats.Area);
maxindex = find(area == max(area));
area(maxindex) = 0;
secondindex = find(area == max(area));
imindex = ismember(imlabel,secondindex);
subimg(imindex==1)=0;%去掉第二大连通域
end
subimgs = [subimgs;subimg];
end
codes = [];
for ii = 0:3
region = [ii*20+1,1,19,20];
subimg = imcrop(img,region);
minwidth = 20;
for angle = -60:60
imgr=imrotate(subimg,angle,'bilinear','crop');%crop 避免图像大小变化
imlabel = bwlabel(imgr);
stats = regionprops(imlabel,'Area');
area = cat(1,stats.Area);
maxindex = find(area == max(area));
imindex = ismember(imlabel,maxindex);%最大连通域为1
[y,x] = find(imindex==1);
width = max(x)-min(x)+1;
if width<minwidth
minwidth = width;
imgrr = imgr;
end
end
mindiffv = 1000000;
for jj = 1:length(DIRS1)
imgsample = imread(strcat(samples,DIRS1(jj).name ));
imgsample = im2bw(imgsample);
diffv = abs(imgsample-imgrr);
alldiffv = sum(sum(diffv));
if alldiffv<mindiffv
mindiffv = alldiffv;
code = DIRS1(jj).name;
code = code(1);
end
end
codes = [codes,code];
end
fprintf('验证码测试字符:%s\n',codes);
num = codes-realcodes;
num = length(find(num~=0));
singleerror = singleerror + num;
if num>0
uniterror = uniterror +1;
end
fprintf('错误个数:%d\n',num);
end
end
fprintf('\n-----结果统计如下-----\n\n');
fprintf('测试验证码的字符数量:%d\n',n*4);
fprintf('测试验证码的字符错误数量:%d\n',singleerror);
fprintf('单个字符识别正确率:%.2f%%\n',(1-singleerror/(n*4))*100);
fprintf('测试验证码图的数量:%d\n',n);
fprintf('测试验证码图的错误数量:%d\n',uniterror);
fprintf('填对验证码的概率:%.2f%%\n',(1-uniterror/n)*100);
结果:
验证码实际字符:2B4E
验证码测试字符:2B4F
错误个数:1
验证码实际字符:4572
验证码测试字符:4572
错误个数:0
验证码实际字符:52CY
验证码测试字符:52LY
错误个数:1
验证码实际字符:83QG
验证码测试字符:85QG
错误个数:1
验证码实际字符:9992
验证码测试字符:9992
错误个数:0
验证码实际字符:A7Y7
验证码测试字符:A7Y7
错误个数:0
验证码实际字符:D993
验证码测试字符:D995
错误个数:1
验证码实际字符:F549
验证码测试字符:F5A9
错误个数:1
验证码实际字符:FMC6
验证码测试字符:FMLF
错误个数:2
验证码实际字符:R4N4
验证码测试字符:R4N4
错误个数:0
-----结果统计如下-----
测试验证码的字符数量:40
测试验证码的字符错误数量:7
单个字符识别正确率:82.50%
测试验证码图的数量:10
测试验证码图的错误数量:6
填对验证码的概率:40.00%
可见单个字符准确率是比较高的的了,但是综合准确率还是不行,观察结果至,错误的字符就是那些易混淆字符,比如E和F,C和L,5和3,4和A等,所以我们能做的事就是增加模板中的样本数量,以期尽量减少混淆。
增加了几十个样本过后再次试验,结果:
验证码实际字符:2B4E
验证码测试字符:2B4F
错误个数:1
验证码实际字符:4572
验证码测试字符:4572
错误个数:0
验证码实际字符:52CY
验证码测试字符:52LY
错误个数:1
验证码实际字符:83QG
验证码测试字符:83QG
错误个数:0
验证码实际字符:9992
验证码测试字符:9992
错误个数:0
验证码实际字符:A7Y7
验证码测试字符:A7Y7
错误个数:0
验证码实际字符:D993
验证码测试字符:D993
错误个数:0
验证码实际字符:F549
验证码测试字符:F5A9
错误个数:1
验证码实际字符:FMC6
验证码测试字符:FMLF
错误个数:2
验证码实际字符:R4N4
验证码测试字符:R4N4
错误个数:0
-----结果统计如下-----
测试验证码的字符数量:40
测试验证码的字符错误数量:5
单个字符识别正确率:87.50%
测试验证码图的数量:10
测试验证码图的错误数量:4
填对验证码的概率:60.00%
可见无论是单个字符识别正确率还是整个验证码正确的概率都有了提升。能够预见:随着模板数量的增多,正确率会不断地提高。
总结
这种方法的可扩展性很弱,而且只适用于简单的验证码,12306那种根本就别提了。
