python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下
import requests as req
import re
def getHTMLText(url):
try:
r = req.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parasePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序列号", "价格", "商品名称"))
count = 0
for j in ilt:
count = count + 1
print(tplt.format(count, j[0], j[1]))
def main():
goods = "python爬虫"
depth = 3
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parasePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
效果图:
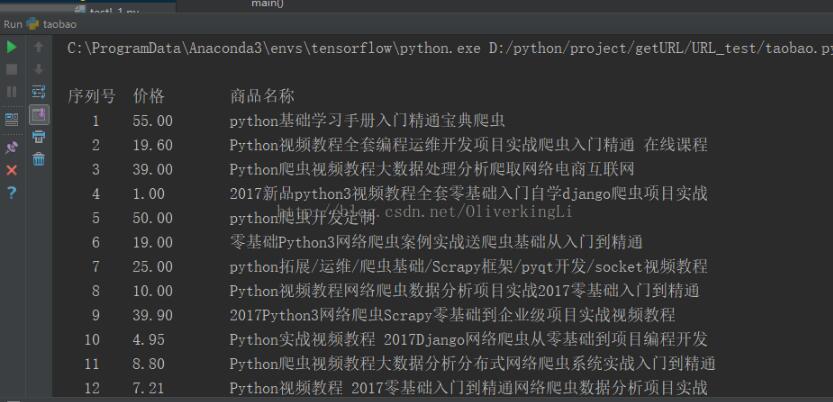
更多内容请参考专题《python爬取功能汇总》进行学习。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
