python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下
1、需求目标 :
进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等。
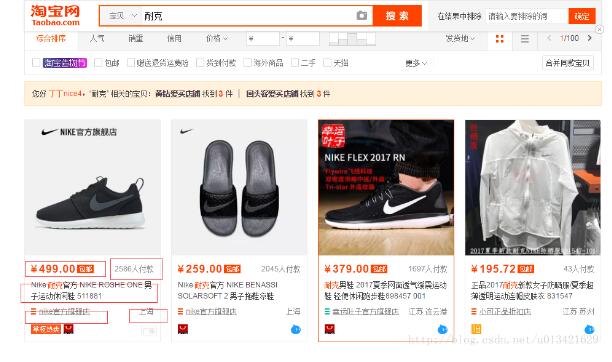
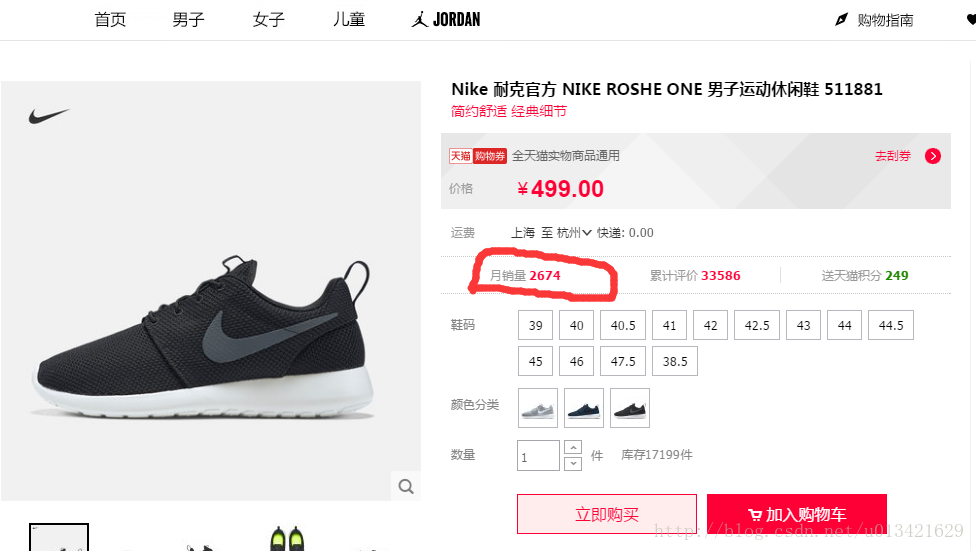

2、结果展示
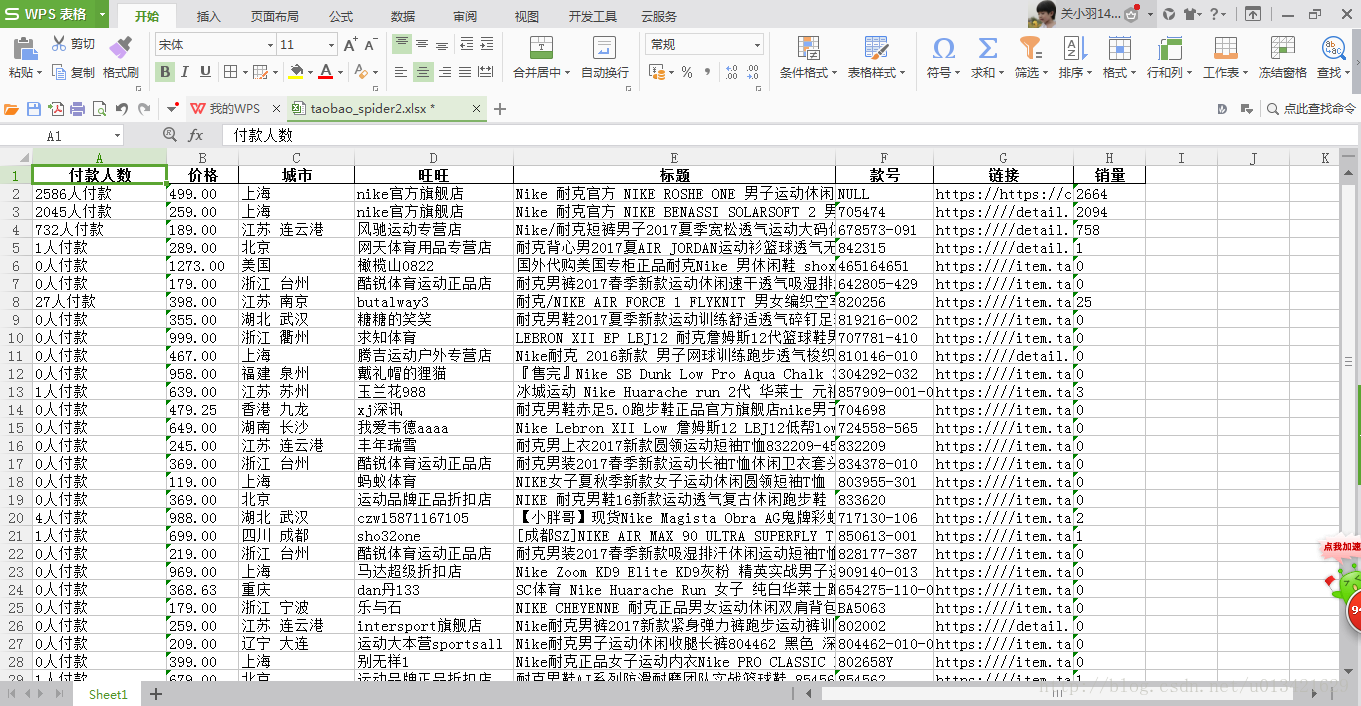
3、源代码
# encoding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
import pandas as pd
time1=time.time()
from lxml import etree
from selenium import webdriver
#########自动模拟
driver=webdriver.PhantomJS(executable_path='D:/Python27/Scripts/phantomjs.exe')
import re
#################定义列表存储#############
title=[]
price=[]
city=[]
shop_name=[]
num=[]
link=[]
sale=[]
number=[]
#####输入关键词耐克(这里必须用unicode)
keyword="%E8%80%90%E5%85%8B"
for i in range(0,1):
try:
print "...............正在抓取第"+str(i)+"页..........................."
url="https://s.taobao.com/search?q=%E8%80%90%E5%85%8B&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20170710&ie=utf8&bcoffset=4&ntoffset=4&p4ppushleft=1%2C48&s="+str(i*44)
driver.get(url)
time.sleep(5)
html=driver.page_source
selector=etree.HTML(html)
title1=selector.xpath('//div[@class="row row-2 title"]/a')
for each in title1:
print each.xpath('string(.)').strip()
title.append(each.xpath('string(.)').strip())
price1=selector.xpath('//div[@class="price g_price g_price-highlight"]/strong/text()')
for each in price1:
print each
price.append(each)
city1=selector.xpath('//div[@class="location"]/text()')
for each in city1:
print each
city.append(each)
num1=selector.xpath('//div[@class="deal-cnt"]/text()')
for each in num1:
print each
num.append(each)
shop_name1=selector.xpath('//div[@class="shop"]/a/span[2]/text()')
for each in shop_name1:
print each
shop_name.append(each)
link1=selector.xpath('//div[@class="row row-2 title"]/a/@href')
for each in link1:
kk="https://" + each
link.append("https://" + each)
if "https" in each:
print each
driver.get(each)
else:
print "https://" + each
driver.get("https://" + each)
time.sleep(3)
html2=driver.page_source
selector2=etree.HTML(html2)
sale1=selector2.xpath('//*[@id="J_DetailMeta"]/div[1]/div[1]/div/ul/li[1]/div/span[2]/text()')
for each in sale1:
print each
sale.append(each)
sale2=selector2.xpath('//strong[@id="J_SellCounter"]/text()')
for each in sale2:
print each
sale.append(each)
if "tmall" in kk:
number1 = re.findall('<ul id="J_AttrUL">(.*?)</ul>', html2, re.S)
for each in number1:
m = re.findall('>*号: (.*?)</li>', str(each).strip(), re.S)
if len(m) > 0:
for each1 in m:
print each1
number.append(each1)
else:
number.append("NULL")
if "taobao" in kk:
number2=re.findall('<ul class="attributes-list">(.*?)</ul>',html2,re.S)
for each in number2:
h=re.findall('>*号: (.*?)</li>', str(each).strip(), re.S)
if len(m) > 0:
for each2 in h:
print each2
number.append(each2)
else:
number.append("NULL")
if "click" in kk:
number.append("NULL")
except:
pass
print len(title),len(city),len(price),len(num),len(shop_name),len(link),len(sale),len(number)
# #
# ######数据框
data1=pd.DataFrame({"标题":title,"价格":price,"旺旺":shop_name,"城市":city,"付款人数":num,"链接":link,"销量":sale,"款号":number})
print data1
# 写出excel
writer = pd.ExcelWriter(r'C:\\taobao_spider2.xlsx', engine='xlsxwriter', options={'strings_to_urls': False})
data1.to_excel(writer, index=False)
writer.close()
time2 = time.time()
print u'ok,爬虫结束!'
print u'总共耗时:' + str(time2 - time1) + 's'
####关闭浏览器
driver.close()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。