Python基于Flask框架配置依赖包信息的项目迁移部署
一般在本机上完成基于Flask框架的代码编写后,如果有接口或者数据操作方面需求需要把代码部署到指定服务器上。
一般情况下,使用Flask框架开发者大多数都是选择Python虚拟环境来运行项目,不同的虚拟环境中配置依赖包信息不同。如果重新迁移到一个新的虚拟环境后,又重新来一个一个的配置依赖包,那将会很浪费时间。
下面介绍一个简单易用的技巧,也是我自己在书本上看到的,以防每次配置需要翻阅书籍的麻烦,所以单自写一篇文章作记录,方便自己以后查看,也希望给其他学习的同学有点帮助。
完成项目相关代码编写后,打开本机CMD,进入项目虚拟环境Scripts目录下,具体操作如下:
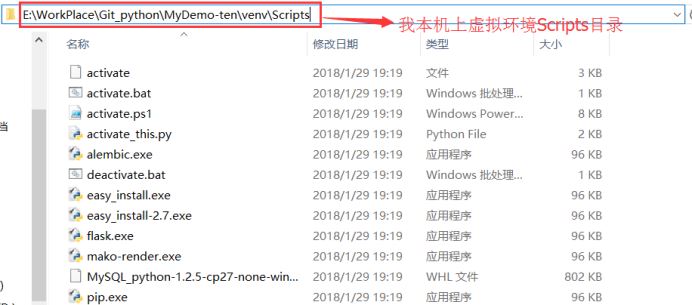
输入
cd E:\WorkPlace\Git_python\MyDemo-ten\venv\Scripts
进入到上面命令指定目录。
然后输入命令
activate
(PS:此命令会在路径前显示虚拟环境名称,比如我的虚拟环境名称是venv,则会显示(venv))。
然后输入命令cd ..
再次输入命令cd .. (PS:cd ..表示返回上一级目录,进行两次操作表示进入项目根目录)。
最后输入命令
pip freeze >requirements.txt
即可在项目根目录下看见一个requirements.txt文件,文件中显示出本项目所有配置依赖包信息。具体见下图:
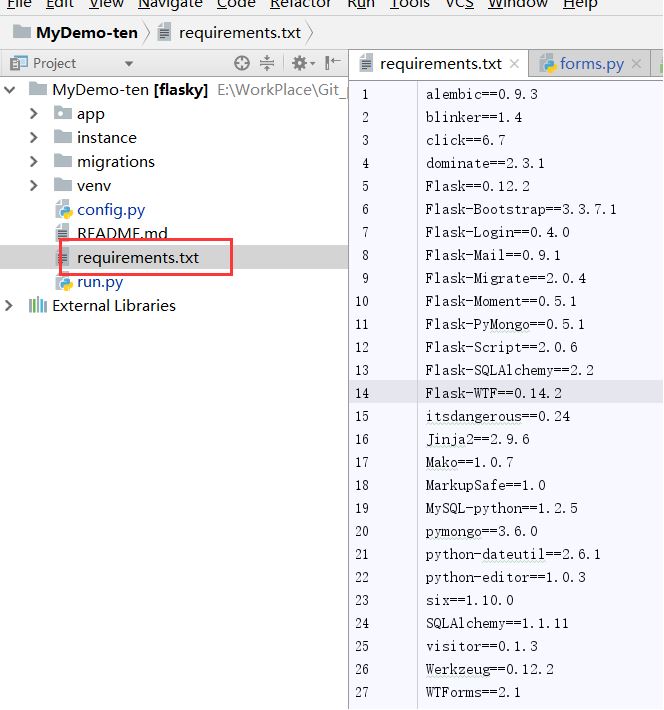
打开ID E查看requirements.txt信息见下图:
迁移到一个新的环境后,如果使用ID E打开,ID E自己会有配置安装requirements.txt信息中指定的依赖包信息提示,安装提示点击安装即可。如果未有提示或者不使用ID E来配置,自己从CMD中进入迁移的新环境新建的虚拟环境中,操作步骤和上面配置创建requirements.txt文件类似,然后输入命令:
pip install -r requirements.txt
即可完成依赖包配置。
总结
以上所述是小编给大家介绍的Python基于Flask框架配置依赖包信息的项目迁移部署小技巧,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!