python和flask中返回JSON数据的方法
在python中可以使用json将数据格式化为JSON格式:
1.将字典转换成JSON数据格式:
s=['张三','年龄','姓名']
t={}
t['data']=s
return json.dumps(t,ensure_ascii=False)

2.将列表转换成JSON数据格式:
s=['张三','年龄','姓名'] return json.dumps(s,ensure_ascii=False)

使用json转换的在前端显示的数据为JSON字符串。
使用flask的jsonify转换后,在前台显示的为JSON对象:
s=['张三','年龄','姓名'] return jsonify(s)

s=['张三','年龄','姓名']
t={}
t['data']=s
return jsonify(t)
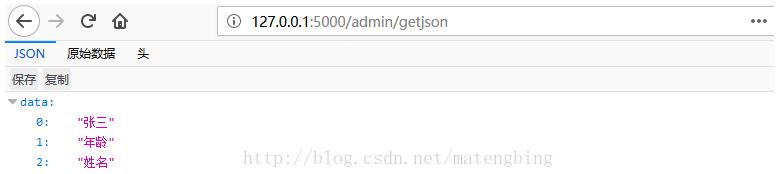
需要返回多条记录时:
s=['张三','年龄','姓名']
t={}
for num in range(1,5):
t[str(num)]=s
return jsonify(t)

或者:
s=['张三','年龄','姓名']
t={}
for num in range(1,5):
t[str(num)]=s
data={}
data['SUCCESS']='SUCCESS'
data['data']=t
return jsonify(data)

json也可以:
s=['张三','年龄','姓名']
t={}
for num in range(1,5):
t[str(num)]=s
data={}
data['SUCCESS']='SUCCESS'
data['data']=t
return json.dumps(data,ensure_ascii=False)

对于python的类转JSON,首先在模型文件中导入:
from sqlalchemy.orm import class_mapper
在模型类中加入一个方法:
def as_dict(obj):
# return {c.name: getattr(self, c.name) for c in self.__table__.columns}
#上面的有缺陷,表字段和属性不一致会有问题
return dict((col.name, getattr(obj, col.name)) \
for col in class_mapper(obj.__class__).mapped_table.c)
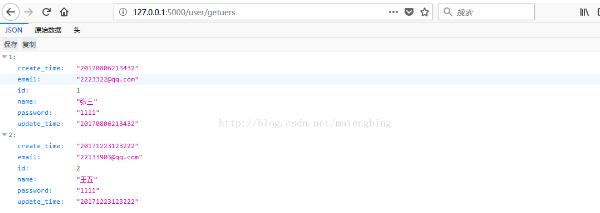
调用:
users=User.query.all();
dict={}
for i in users:
dict[repr(i.id)]=i.as_dict()
前端显示:
使用flask+SQLAchemy这个ORM时,定义的模型类不能使用
json.dumps(user, default=lambda o: o.__dict__, sort_keys=True, indent=4)
这种方式格式化。
使用
user.__dict__.keys()获取的属性会多出一个属性。
在python中定义的一般类,如:
class Test(object):
def __init__(self,name,age):
self.name=name
self.age=age
python中的普通类可以直接格式化:
test=Test('张三',21)
print(json.dumps(test,default=lambda o: o.__dict__,sort_keys=True, indent=4,ensure_ascii=False))

以上这篇python和flask中返回JSON数据的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。