python读取文本中数据并转化为DataFrame的实例
在技术问答中看到一个这样的问题,感觉相对比较常见,就单开一篇文章写下来。
从纯文本格式文件 “file_in”中读取数据,格式如下:

需要输出成“file_out”,格式如下:
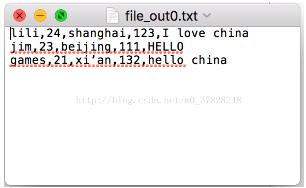
数据的原格式是“类别:内容”,以空行“\n”为分条目,转换后变成一个条目一行,按照类别顺序依次写出内容。
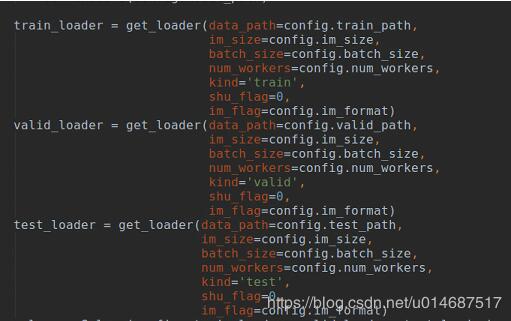
建议读取后,使用pandas,把数据建立称DataFrame的表格。这样方便以后处理数据。但是原格式并不是通常的表格格式,所以要先做一些简单的处理。
#coding:utf8
import sys
from pandas import DataFrame #DataFrame通常来装二维的表格
import pandas as pd #pandas是流行的做数据分析的包
#建立字典,键和值都从文件里读出来。键是nam,age……,值是lili,jim……
dict_data={}
#打开文件
with open('file_in.txt','r')as df:
#读每一行
for line in df:
#如果这行是换行符就跳过,这里用'\n'的长度来找空行
if line.count('\n') == len(line):
continue
#对每行清除前后空格(如果有的话),然后用":"分割
for kv in [line.strip().split(':')]:
#按照键,把值写进去
dict_data.setdefault(kv[0],[]).append(kv[1])
#print(dict_data)看看效果
#这是把键读出来成为一个列表
columnsname=list(dict_data.keys())
#建立一个DataFrame,列名即为键名,也就是nam,age……
frame = DataFrame(dict_data,columns=columnsname)
#把DataFrame输出到一个表,不要行名字和列名字
frame.to_csv('file_out0.txt',index=False,header=False)
以上这篇python读取文本中数据并转化为DataFrame的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。