解决Python requests库编码 socks5代理的问题
编码问题
response = requests.get(URL, params=params,
headers=headers, timeout=10)
print 'self.encoding',response.encoding
output:
self.encoding ISO-8859-1
查了一些相关的资料,看了下requests的源码,只有在服务器响应的头部包含有Content-Type,且里面有charset信息,requests能够正确识别,否则就会使用默认的 ISO-8859-1编码。github中也有讨论这个问题,但requests的作者们说是根据rfc来的.
在上述代码中,response.text 是requests库返回响应的Unicode编码内容
这样,当我们去获取一些中文网页的响应内容时,且其响应头部没有charset信息,则response.text的编码就会有问题(requests的json()方法也受这个编码影响)
比如,我爬取百度的网页的时候,其中文是utf-8编码的
如下python2.7代码
In [14]: a = '约' #utf-8编码
In [15]: a
Out[15]: '\xe7\xba\xa6'
In [22]: b=a.decode('ISO-8859-1')#response.text 认为响应内容是ISO-8859-1编码,将其decode为Unicode
In [23]: b
Out[23]: u'\xe7\xba\xa6'
In [26]: c=b.encode('utf8')#如果我们没有注意ISO-8859-1,直接以utf8对其进行编码
In [27]: c
Out[27]: '\xc3\xa7\xc2\xba\xc2\xa6'#那么encode得到的utf-8,在显示器上显示的就是乱码,因为'约'的utf-8编码是'\xe7\xba\xa6'
解决方法1: 用response.content ,response.content in bytes,所以用content可以自己决定对其的编码
解决方法2: 获得请求后使用 response.encoding = ‘utf-8'
解决方法3: 利用requests库里根据获得响应内容来判断编码的函数,参考文献里有讲到
python2的编码还是很乱的 str可以是各种编码,python3统一str为Unicode, byte可以是各种编码
python2中encode后是str类型,decode后是Unicode类型,python3中encode后是byte类型,decode后是str类型(Unicode编码)
用python3吧,下面是python3的代码
In [13]: a = '约' #Unicode
In [14]: type(a)
Out[14]: str
In [15]: b=a.encode('utf8')
In [16]: b
Out[16]: b'\xe7\xba\xa6'
In [17]: type(b)
Out[17]: bytes
In [27]: b'\xe7\xba\xa623,000'.decode('ISO-8859-1')
Out[27]: '约23,000'
In [28]: type(b'\xe7\xba\xa623,000'.decode('ISO-8859-1'))
Out[28]: str
In [29]: b'\xe7\xba\xa623,000'.decode('utf8')
Out[29]: '约23,000'
socks5代理问题
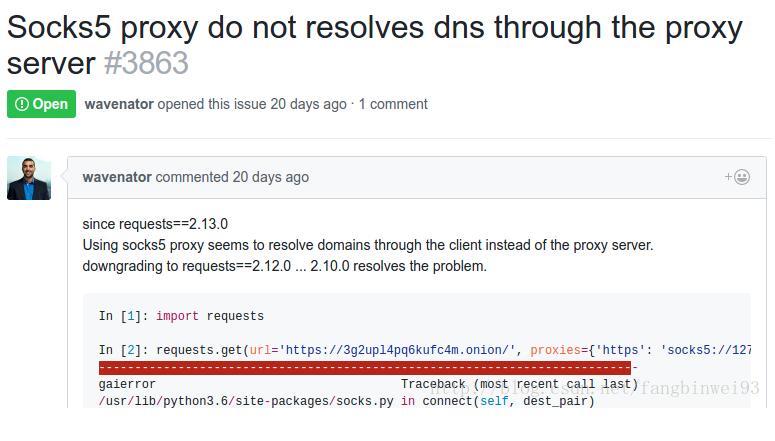
现在的requests2.13.0的socks5代理我在使用的时候会出现问题,
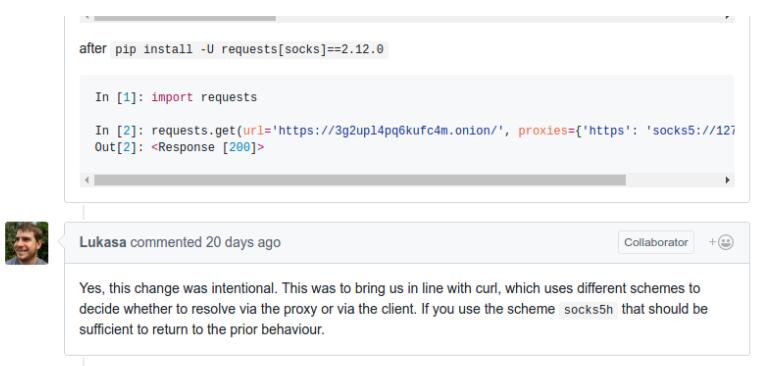
我用的代理是shadowsocks,比如我想要访问https://www.facebook.com 在向本地127.0.0.1:1080端口发送socks5请求时,我发现shadowsocks在向一个IP地址连接,连接不上,我用chrome连接Facebook的时候,我发现shadowsocks是在向www.facebook.com连接,能够成功连接,应该是DNS解析问题,出现了重复解析的问题,使用requests2.12不会有这个问题,在github上也找到了相关的issue
import requests
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/56.0.2924.87 Safari/537.36'}
proxies = {'http': 'socks5://127.0.0.1:1080','https':'socks5://127.0.0.1:1080'}
url = 'https://www.facebook.com'
response = requests.get(url, proxies=proxies)
print(response.content)
以上这篇解决Python requests库编码 socks5代理的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。