python实现验证码识别功能
本文实例为大家分享了python实现验证码识别的具体代码,供大家参考,具体内容如下
1.通过二值化处理去掉干扰线
2.对黑白图片进行降噪,去掉那些单独的黑色像素点
3.消除边框上附着的黑色像素点
4.识别图像中的文字,去掉空格与'.'
python代码:
from PIL import Image
from aip import AipOcr
file='1-1-7'
# 二值化处理,转化为黑白图片
def two_value():
for i in range(1, 5):
# 打开文件夹中的图片
image = Image.open(file+'.jpg')
# 灰度图
lim = image.convert('L')
# 灰度阈值设为165,低于这个值的点全部填白色
threshold = 165
table = []
for j in range(256):
if j < threshold:
table.append(0)
else:
table.append(1)
bim = lim.point(table, '1')
bim.save(file+'.1.jpg')
two_value()
# 去除干扰线
im = Image.open(file+'.1.jpg')
# 图像二值化
data = im.getdata()
w, h = im.size
black_point = 0
for x in range(1, w - 1):
for y in range(1, h - 1):
mid_pixel = data[w * y + x] # 中央像素点像素值
if mid_pixel < 50: # 找出上下左右四个方向像素点像素值
top_pixel = data[w * (y - 1) + x]
left_pixel = data[w * y + (x - 1)]
down_pixel = data[w * (y + 1) + x]
right_pixel = data[w * y + (x + 1)]
# 判断上下左右的黑色像素点总个数
if top_pixel < 5: #小于5比小于10更精确
black_point += 1
if left_pixel < 5:
black_point += 1
if down_pixel < 5:
black_point += 1
if right_pixel < 5:
black_point += 1
if black_point < 1:
im.putpixel((x, y), 255)
# print(black_point)
black_point = 0
im.save(file+'.2.jpg')
# 去除干扰线
im = Image.open(file+'.2.jpg')
# 图像二值化
data = im.getdata()
w, h = im.size
black_point = 0
for x in range(1, w - 1):
for y in range(1, h - 1):
if x < 2 or y < 2:
im.putpixel((x - 1, y - 1), 255)
if x > w - 3 or y > h - 3:
im.putpixel((x + 1, y + 1), 255)
im.save(file+'.3.jpg')
# 定义常量
APP_ID = '11352343'
API_KEY = 'Nd5Z1NkGoLDvHwBnD2bFLpCE'
SECRET_KEY = 'A9FsnnPj1Ys2Gof70SNgYo23hKOIK8Os'
# 初始化AipFace对象
aipOcr = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 读取图片
filePath=file+'.3.jpg'
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 定义参数变量
options = {
'detect_direction': 'true',
'language_type': 'CHN_ENG',
}
# 调用通用文字识别接口
result = aipOcr.basicGeneral(get_file_content(filePath), options)
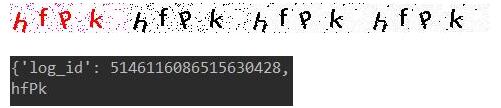
print(result)
words_result=result['words_result']
for i in range(len(words_result)):
print(words_result[i]['words'].replace(' ','').replace('.','')) #去掉可能被识别的空格与.
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。