TensorFlow数据输入的方法示例
读取数据(Reading data)
TensorFlow输入数据的方式有四种:
- tf.data API:可以很容易的构建一个复杂的输入通道(pipeline)(首选数据输入方式)(Eager模式必须使用该API来构建输入通道)
- Feeding:使用Python代码提供数据,然后将数据feeding到计算图中。
- QueueRunner:基于队列的输入通道(在计算图计算前从队列中读取数据)
- Preloaded data:用一个constant常量将数据集加载到计算图中(主要用于小数据集)
1. tf.data API
关于tf.data.Dataset的更详尽解释请看《programmer's guide》。tf.data API能够从不同的输入或文件格式中读取、预处理数据,并且对数据应用一些变换(例如,batching、shuffling、mapping function over the dataset),tf.data API 是旧的 feeding、QueueRunner的升级。
2. Feeding
注意:Feeding是数据输入效率最低的方式,应该只用于小数据集和调试(debugging)
TensorFlow的Feeding机制允许我们将数据输入计算图中的任何一个Tensor。因此可以用Python来处理数据,然后直接将处理好的数据feed到计算图中 。
在run()或eval()中用feed_dict来将数据输入计算图:
with tf.Session():
input = tf.placeholder(tf.float32)
classifier = ...
print(classifier.eval(feed_dict={input: my_python_preprocessing_fn()}))
虽然你可以用feed data替换任何Tensor的值(包括variables和constants),但最好的使用方法是使用一个tf.placeholder节点(专门用于feed数据)。它不用初始化,也不包含数据。一个placeholder没有被feed数据,则会报错。
使用placeholder和feed_dict的一个实例(数据集使用的是MNIST)见tensorflow/examples/tutorials/mnist/fully_connected_feed.py
3. QueueRunner
注意:这一部分介绍了基于队列(Queue)API构建输入通道(pipelines),这一方法完全可以使用 tf.data API来替代。
一个基于queue的从文件中读取records的通道(pipline)一般有以下几个步骤:
- 文件名列表(The list of filenames)
- 文件名打乱(可选)(Optional filename shuffling)
- epoch限制(可选)(Optional epoch limit)
- 文件名队列(Filename queue)
- 与文件格式匹配的Reader(A Reader for the file format)
- decoder(A decoder for a record read by the reader)
- 预处理(可选)(Optional preprocessing)
- Example队列(Example queue)
3.1 Filenames, shuffling, and epoch limits
对于文件名列表,有很多方法:1. 使用一个constant string Tensor(比如:["file0", "file1"])或者 [("file%d" %i) for i in range(2)];2. 使用 tf.train.match_filenames_once 函数;3. 使用 tf.gfile.Glob(path_pattern) 。
将文件名列表传给 tf.train.string_input_producer 函数。string_input_producer 创建一个 FIFO 队列来保存(holding)文件名,以供Reader使用。
string_input_producer 可以对文件名进行shuffle(可选)、设置一个最大迭代 epochs 数。在每个epoch,一个queue runner将整个文件名列表添加到queue,如果shuffle=True,则添加时进行shuffle。This procedure provides a uniform sampling of files, so that examples are not under- or over- sampled relative to each other。
queue runner线程独立于reader线程,所以enqueuing和shuffle不会阻碍reader。
3.2 File formats
要选择与输入文件的格式匹配的reader,并且要将文件名队列传递给reader的 read 方法。read 方法输出一个 key identifying the file and record(在调试过程中非常有用,如果你有一些奇怪的 record)
3.2.1 CSV file
为了读取逗号分隔符分割的text文件(csv),要使用一个 tf.TextLineReader 和一个 tf.decode_csv。例如:
filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"]) reader = tf.TextLineReader() key, value = reader.read(filename_queue) # Default values, in case of empty columns. Also specifies the type of the # decoded result. record_defaults = [[1], [1], [1], [1], [1]] col1, col2, col3, col4, col5 = tf.decode_csv( value, record_defaults=record_defaults) features = tf.stack([col1, col2, col3, col4]) with tf.Session() as sess: # Start populating the filename queue. coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord) for i in range(1200): # Retrieve a single instance: example, label = sess.run([features, col5]) coord.request_stop() coord.join(threads)
read 方法每执行一次,会从文件中读取一行。然后 decode_csv 将读取的内容解析成一个Tensor列表。参数 record_defaults 决定解析产生的Tensor的类型,另外,如果输入中有缺失值,则用record_defaults 指定的默认值来填充。
在使用run或者eval 执行 read 方法前,你必须调用 tf.train.start_queue_runners 去填充 queue。否则,read 方法将会堵塞(等待 filenames queue 中 enqueue 文件名)。
3.2.2 Fixed length records
为了读取二进制文件(二进制文件中,每一个record都占固定bytes),需要使用一个 tf.FixedLengthRecordReader 和 tf.decode_raw。decode_raw 将 reader 读取的 string 解析成一个uint8 tensor。
例如,二进制格式的CIFAR-10数据集中的每一个record都占固定bytes:label占1 bytes,然后后面的image数据占3072 bytes。当你有一个unit8 tensor时,通过切片便可以得到各部分并reformat成需要的格式。对于CIFAR-10数据集的reading和decoding,可以参照:tensorflow_models/tutorials/image/cifar10/cifar10_input.py或这个教程。
3.2.3 Standard TensorFlow format
另一个方法是将数据集转换为一个支持的格式。这个方法使得数据集和网络的混合和匹配变得简单(make it easier to mix and match data sets and network architectures)。TensorFlow中推荐的格式是 TFRecords文件,TFRecords中包含 tf.train.Example protocol buffers (在这个协议下,特征是一个字段).
你写一小段程序来获取数据,然后将数据填入一个Example protocol buffer,并将这个 protocol buffer 序列化(serializes)为一个string,然后用 tf.python_io.TFRcordWriter 将这个string写入到一个TFRecords文件中。例如,tensorflow/examples/how_tos/reading_data/convert_to_records.py 将MNIST数据集转化为TFRecord格式。
读取TFRecord文件的推荐方式是使用 tf.data.TFRecordDataset,像这个例子一样:
dataset = tf.data.TFRecordDataset(filename) dataset = dataset.repeat(num_epochs) # map takes a python function and applies it to every sample dataset = dataset.map(decode)
为了完成相同的任务,基于queue的输入通道需要下面的代码(使用的decode和上一段代码一样):
filename_queue = tf.train.string_input_producer([filename], num_epochs=num_epochs) reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) image,label = decode(serialized_example)
3.3 Preprocessing
然后你可以对examples进行你想要的预处理(preprocessing)。预处理是独立的(不依赖于模型参数)。常见的预处理有:数据的标准化(normalization of your data)、挑选一个随机的切片,添加噪声(noise)或者畸变(distortions)等。具体的例子见:tensorflow_models/tutorials/image/cifar10/cifar10_input.py
3.4 Batching
在pipeline的末端,我们通过调用tf.train.shuffle_batch 来创建两个queue,一个将example batch起来 for training、evaluation、inference;另一个来shuffle examples的顺序。
例子:
def read_my_file_format(filename_queue): reader = tf.SomeReader() key, record_string = reader.read(filename_queue) example, label = tf.some_decoder(record_string) processed_example = some_processing(example) return processed_example, label def input_pipeline(filenames, batch_size, num_epochs=None): filename_queue = tf.train.string_input_producer( filenames, num_epochs=num_epochs, shuffle=True) example, label = read_my_file_format(filename_queue) # min_after_dequeue defines how big a buffer we will randomly sample # from -- bigger means better shuffling but slower start up and more # memory used. # capacity must be larger than min_after_dequeue and the amount larger # determines the maximum we will prefetch. Recommendation: # min_after_dequeue + (num_threads + a small safety margin) * batch_size min_after_dequeue = 10000 capacity = min_after_dequeue + 3 * batch_size example_batch, label_batch = tf.train.shuffle_batch( [example, label], batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue) return example_batch, label_batch
如果你需要更多的并行或者打乱不同文件中example,使用多个reader,然后使用 tf.train.shuffle_batch_join将多个reader读取的内容整合到一起。(If you need more parallelism or shuffling of examples between files, use multiple reader instances using the tf.train.shuffle_batch_join)
例子:
def read_my_file_format(filename_queue):
reader = tf.SomeReader()
key, record_string = reader.read(filename_queue)
example, label = tf.some_decoder(record_string)
processed_example = some_processing(example)
return processed_example, label
def input_pipeline(filenames, batch_size, read_threads, num_epochs=None):
filename_queue = tf.train.string_input_producer(
filenames, num_epochs=num_epochs, shuffle=True)
example_list = [read_my_file_format(filename_queue)
for _ in range(read_threads)]
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch_join(
example_list, batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch, label_batch
所有的reader共享一个filename queue。这种方式保证了不同的reader在同一个epoch,读取不同的文件,直到所有的文件的已经读取完,然后在下一个epoch,重新从所有的文件读取(You still only use a single filename queue that is shared by all the readers. That way we ensure that the different readers use different files from the same epoch until all the files from the epoch have been started. (It is also usually sufficient to have a single thread filling the filename queue.))。
另一个可选的方法是去通过调用 tf.train.shuffle_batch 使用单个的reader,但是将参数 num_threads 参数设置为大于1的值。这将使得在同一时间只能从一个文件读取内容(但是比 1 线程快),而不是同时从N个文件中读取。这可能很重要:
- 如果你的
num_threads参数值比文件的数量多,那么很有可能:有两个threads会一前一后从同一个文件中读取相同的example。这是不好的,应该避免。 - 或者,如果并行地读取N个文件,可能或导致大量的磁盘搜索(意思是,多个文件存在于磁盘的不同位置,而磁头只能有一个位置,所以会增加磁盘负担)
那么需要多少个线程呢?tf.train.shuffle_batch*函数会给计算图添加一个summary来记录 example queue 的使用情况。如果你有足够的reading threads,这个summary将会总大于0。你可以用TensorBoard来查看训练过程中的summaries
3.5 Creating threads to prefetch using QueueRunner objects
使用QueueRunner对象来创建threads来prefetch数据
说明:tf.train里的很多函数会添加tf.train.QueueRunner对象到你的graph。这些对象需要你在训练或者推理前,调用tf.train.start_queue_runners,否则数据无法读取到图中。调用tf.train.start_queue_runners会运行输入pipeline需要的线程,这些线程将example enqueue到队列中,然后dequeue操作才能成功。这最好和tf.train.Coordinator配合着用,当有错误时,它会完全关闭掉开启的threads。如果你在创建pipline时设置了迭代epoch数限制,将会创建一个epoch counter的局部变量(需要初始化)。下面是推荐的代码使用模板:
# Create the graph, etc.
init_op = tf.global_variables_initializer()
# Create a session for running operations in the Graph.
sess = tf.Session()
# Initialize the variables (like the epoch counter).
sess.run(init_op)
# Start input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
while not coord.should_stop():
# Run training steps or whatever
sess.run(train_op)
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
# When done, ask the threads to stop.
coord.request_stop()
# Wait for threads to finish.
coord.join(threads)
sess.close()
这里的代码是怎么工作的?
首先,我们创建整个图。它的input pipeline将有几个阶段,这些阶段通过Queue连在一起。第一个阶段将会产生要读取的文件的文件名,并将文件名enqueue到filename queue。第二个阶段使用一个Reader来dequeue文件名并读取,产生example,并将example enqueue到一个example queue。根据你的设置,你可能有很多第二阶段(并行),所以你可以从并行地读取多个文件。最后一个阶段是一个enqueue操作,将example enqueue成一个queue,然后等待下一步操作。我们想要开启多个线程运行着些enqueue操作,所以我们的训练loop能够从example queue中dequeue examples。
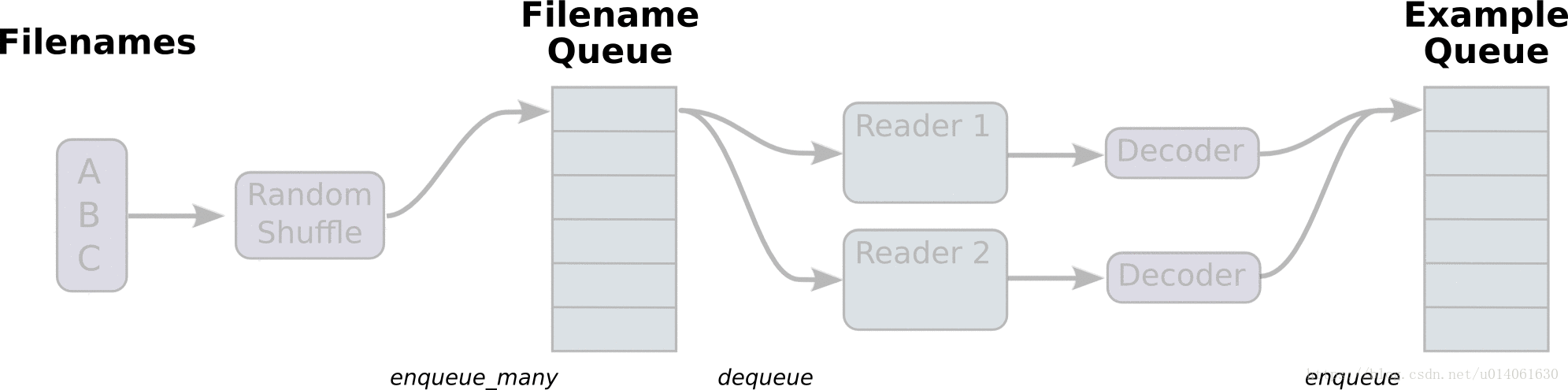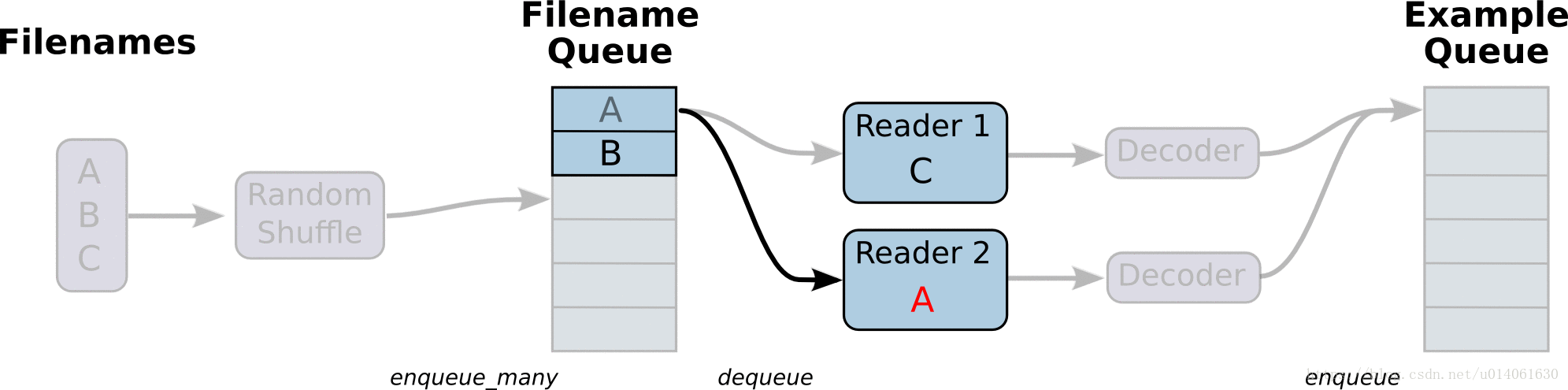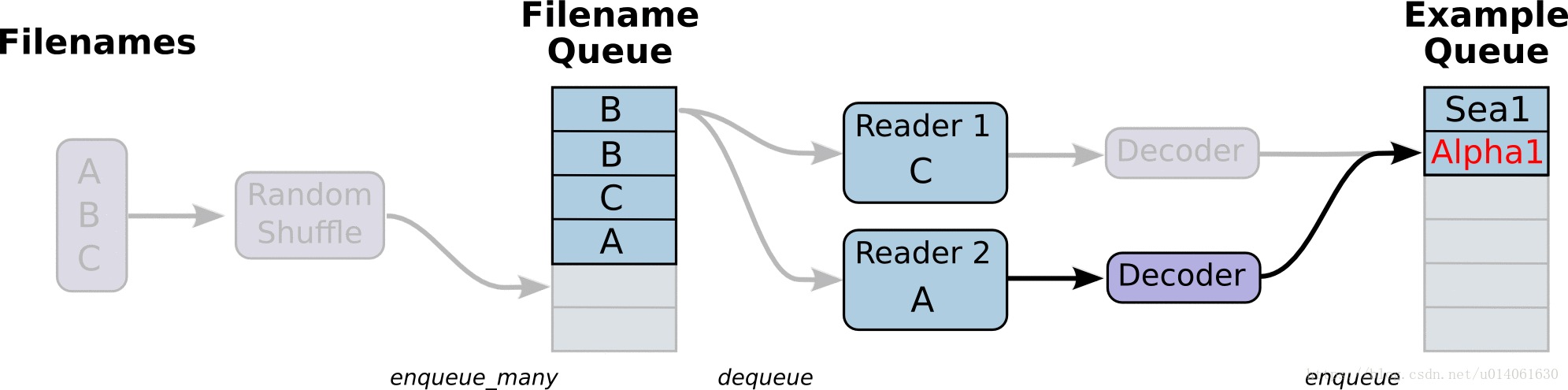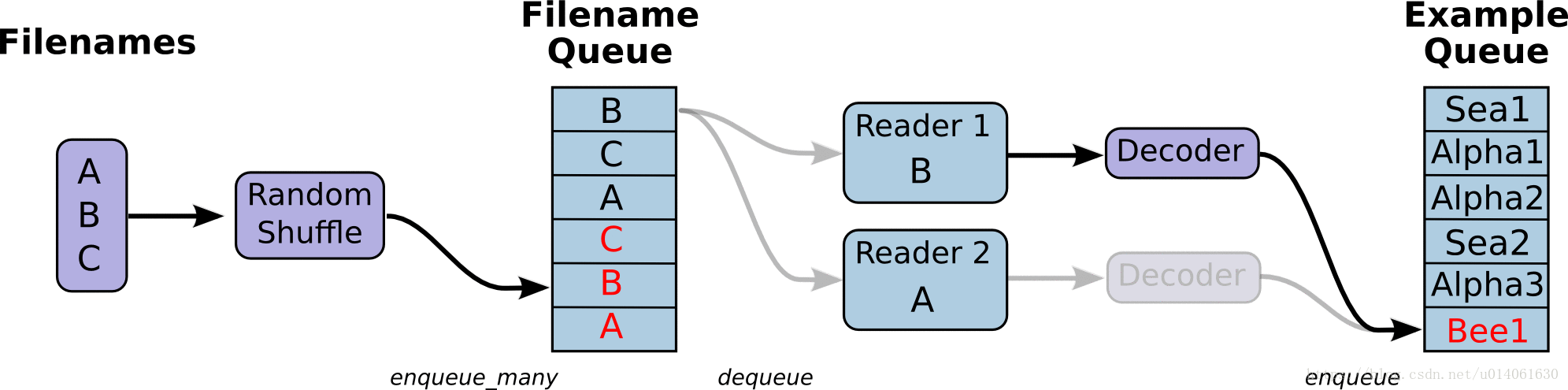
tf.train里的辅助函数(创建了这些queue、enqueuing操作)会调用tf.train.add_queue——runner添加一个tf.train.QueueRunner到图中。每一个QueueRunner负责一个阶段。一旦图构建好,tf.train.start_queue_runners函数会开始图中每一个QueueRunner的入队操作。
如果一切进行顺利,你现在可以运行训练step(后台线程会填满queue)。如果你设置了epoch限制,在达到固定的epoch时,在进行dequeuing会得到tf.errors.OutOfRangeError。这个错误等价于EOF(end of file),意味着已经达到了固定的epochs。
最后一部分是tf.train.Coordinator。它主要负责通知所有的线程是否应该停止。在大多数情况下,这通常是因为遇到了一个异常(exception)。例如,某一个线程在运行某些操作时出错了(或者python的异常)。
关于threading、queues、QueueRunners、Coordinators的更多细节见这里
3.6 Filtering records or producing multiple examples per record
一个example的shape是 [x,y,z],一个batch的example的shape为 [batch, x, y, z]。如果你想去过滤掉这个record,你可以把 batch size 设置为 0;如果你想让每一个record产生多个example,你可以把batch size设置为大于1。然后,在调用调用batching函数(shuffle_batch或shuffle_batch_join)时,设置enqueue_many=True。
3.7 Sparse input data
queues在SparseTensors的情况下不能很好的工作。如果你使用SparseTensors,你必须在batching后用tf.sparse_example来decode string records(而不是在batching前使用tf.parse_single_example来decode)
4. Preloaded data
这仅仅适用于小数据集,小数据集可以被整体加载到内存。预加载数据集主要有两种方法:
- 将数据集存储成一个constant
- 将数据集存储在一个variable中,一旦初始化或者assign to后,便不再改变。
使用一个constant更简单,但是需要更多的内存(因为所有的常量都储存在计算图中,而计算图可能需要进行多次复制)。
training_data = ... training_labels = ... with tf.Session(): input_data = tf.constant(training_data) input_labels = tf.constant(training_labels) ...
为了使用一个varibale,在图构建好后,你需要去初始化它。
training_data = ...
training_labels = ...
with tf.Session() as sess:
data_initializer = tf.placeholder(dtype=training_data.dtype,
shape=training_data.shape)
label_initializer = tf.placeholder(dtype=training_labels.dtype,
shape=training_labels.shape)
input_data = tf.Variable(data_initializer, trainable=False, collections=[])
input_labels = tf.Variable(label_initializer, trainable=False, collections=[])
...
sess.run(input_data.initializer,
feed_dict={data_initializer: training_data})
sess.run(input_labels.initializer,
feed_dict={label_initializer: training_labels})
设置trainable=False将使variable不加入GraphKeys.TRAINABLE_VARIABLES容器,所以我们不用在训练过程中更新它。设置collections=[]将会使variable不加入GraphKeys.GLOBAL_VARIABLES容器(这个容器主要用于保存和恢复checkpoints)。
无论哪种方式,tf.train.slice_input_producer都能够用来产生一个slice。这在整个epoch上shuffle了example,所以batching时,进一步的shuffling不再需要。所以不再使用shuffle_batch函数,而使用tf.train.batch函数。为了使用多个预处理线程,设置num_threads参数大于1。
MNIST数据集上使用constant来preload数据的实例见tensorflow/examples/how_tos/reading_data/fully_connected_preloaded.py;使用variable来preload数据的例子见tensorflow/examples/how_tos/reading_data/fully_connected_preloaded_var.py,你可以通过 fully_connected_feed和 fully_connected_feed版本来对比两种方式。
4. Multiple input pipelines
一般,你想要去在一个数据集上训练,而在另一个数据集上评估模型。实现这个想法的一种方式是:以两个进程,建两个独立的图和session:
- 训练进程读取训练数据,并且周期性地将模型的所有训练好的变量保存到checkpoint文件中。
- 评估进程从checkpoint文件中恢复得到一个inference模型,这个模型读取评估数据。
在estimators里和CIFAR-10模型示例里,采用就是上面的方法。该方法主要有两个好处:
- 你的评估是在一个训练好的模型的快照上进行的。
- 在训练完成或中断后,你也可以进行评估。
你可以在同一个进程中同一个图中进行训练和评估,并且训练和评估共享训练好的参数和层。关于共享变量,详见这里。
为了支持单个图方法(single-graph approach),tf.data也提供了高级的iterator类型,它将允许用户去在不重新构建graph和session的情况下,改变输入pipeline。
注意:尽管上面的实现很好,但很多op(比如tf.layers.batch_normalization和tf.layers.dropout)与模型模式有关(训练和评估时,计算不一致),你必须很小心地去设置这些,如果你更改数据源。
英文版:https://tensorflow.google.cn/api_guides/python/reading_data
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。