Python操作MySQL数据库的方法
pymsql
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同。
下载安装
pip3 install pymysql
使用操作
1、执行SQL
import pymysql
# 创建连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回收影响行数
effect_row = cursor.execute("update hosts set host = '1.1.1.2'")
# 执行SQL,并返回受影响行数
#effect_row = cursor.execute("update hosts set host = '1.1.1.2' where nid > %s", (1,))
# 执行SQL,并返回受影响行数
#effect_row = cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
2、获取新创建数据自增ID
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
cursor = conn.cursor()
cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
conn.commit()
cursor.close()
conn.close()
# 获取最新自增ID
new_id = cursor.lastrowid
3、获取查询数据
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
cursor = conn.cursor()
cursor.execute("select * from hosts")
# 获取第一行数据
row_1 = cursor.fetchone()
# 获取前n行数据
# row_2 = cursor.fetchmany(3)
# 获取所有数据
# row_3 = cursor.fetchall()
conn.commit()
cursor.close()
conn.close()
注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如:
cursor.scroll(1,mode='relative') # 相对当前位置移动 cursor.scroll(2,mode='absolute') # 相对绝对位置移动
4、fetch数据类型
关于默认获取的数据是元祖类型,如果想要或者字典类型的数据,即:
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
# 游标设置为字典类型
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
r = cursor.execute("call p1()")
result = cursor.fetchone()
conn.commit()
cursor.close()
conn.close()
数据库补充
导出现有数据库数据:
mysqldump -u用户名 -p密码 数据库名称 >导出文件路径 # 结构+数据
mysqldump -u用户名 -p密码 -d 数据库名称 >导出文件路径 # 结构
导入现有数据库数据:
mysqldump -uroot -p密码 数据库名称 < 文件路径
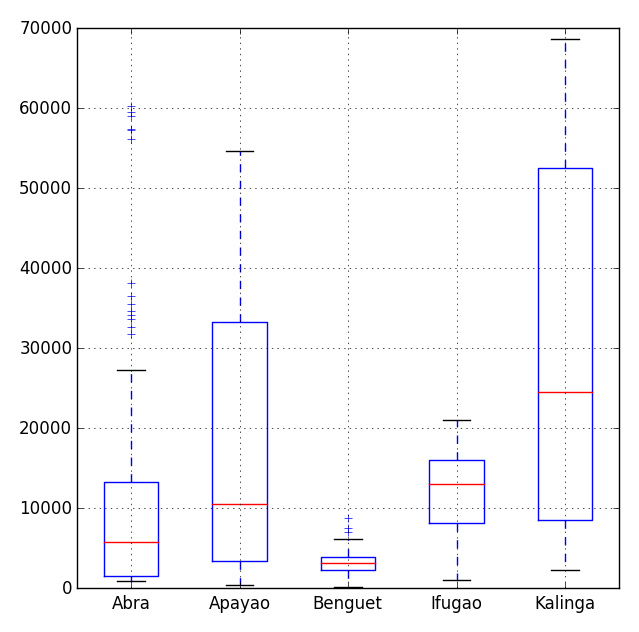
MySQL中四种常用存储引擎的介绍
(1):MyISAM存储引擎:不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有 要求或者以select,insert为主的应用基本上可以用这个引擎来创建表
支持3种不同的存储格式,分别是:静态表;动态表;压缩表
静态表:表中的字段都是非变长字段,这样每个记录都是固定长度的,优点存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多(因为存储时会按照列的宽度定义补足空格)ps:在取数据的时候,默认会把字段后面的空格去掉,如果不注意会把数据本身带的空格也会忽略。
动态表:记录不是固定长度的,这样存储的优点是占用的空间相对较少;缺点:频繁的更新、删除数据容易产生碎片,需要定期执行OPTIMIZE TABLE或者myisamchk-r命令来改善性能
压缩表:因为每个记录是被单独压缩的,所以只有非常小的访问开支
(2)InnoDB存储引擎*
该存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM引擎,写的处理效率会差一些,并且会占用更多的磁盘空间以保留数据和索引。
InnoDB存储引擎的特点:支持自动增长列,支持外键约束
(3):MEMORY存储引擎
Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引,两种不同类型的索引有其不同的使用范围
Hash索引优点:
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
Hash索引缺点: 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
Memory类型的存储引擎主要用于哪些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果,。对存储引擎为memory的表进行更新操作要谨慎,因为数据并没有实际写入到磁盘中,所以一定要对下次重新启动服务后如何获得这些修改后的数据有所考虑。
(4)MERGE存储引擎
Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
总结
以上所述是小编给大家介绍的Python操作MySQL数据库的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!