python爬虫的数据库连接问题【推荐】
1.需要导的包
import pymysql
2.# mysql连接信息(字典形式)
db_config ={
'host': '127.0.0.1',#连接的主机id(107.0.0.1是本机id)
'port': 3306,
'user': '****',
'password': '****',
'db': 'test',#(数据库名)
'charset': 'utf8'
}
3.# 获得数据库连接
connection = pymysql.connect(**db_config)
connection()具体的基础知识详见连接
4.具体连接(以简书为例)
try:
# 获得数据库游标(游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。)
with connection.cursor() as cursor:
sql = 'insert into simplebook(title, url) values(%s, %s)'
for u in urls:
# 执行sql语句
cursor.execute(sql, (u.string, r'http://www.jianshu.com'+u.attrs['href']))
# 事务提交
connection.commit()
finally:
# 关闭数据库连接
connection.close()
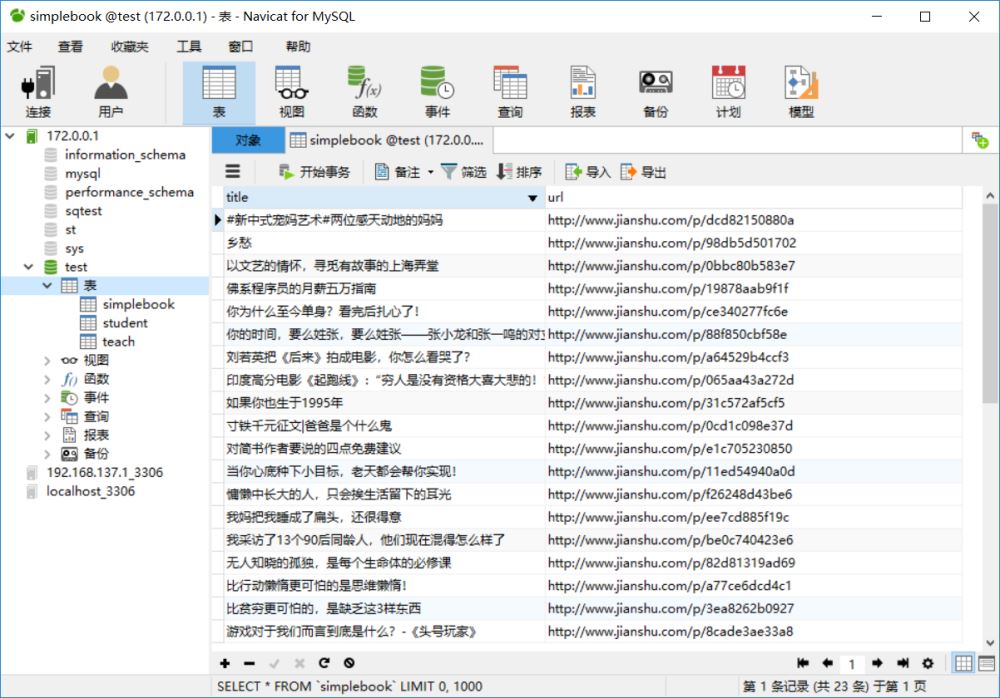
5.连接数据库成功,并得到数据
总结
以上所述是小编给大家介绍的python爬虫的数据库连接问题,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!