python正则表达式之对号入座篇
一、定义
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。如果找到了符合这样一种规则的字符串,我们就说匹配上了,否则匹配失败。
二、匹配规则
1.语法规则

2.相关注解
a.反斜杠问题
假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。其匹配过程如下:
| 字符 | 匹配过程 |
| \\\\abc | 为字符串实值取消反斜杠转义 |
| \\abc | 为re.compile()取消反斜杠转义 |
| \abc | 欲匹配的目标字符串 |
为了解决输入四个“\”的麻烦,我们可以使用python里的原生字符串(raw string),即在字符串前面加上r。如下:
import re print(re.search(r"\\abc","123\\abc"))
从上面可知,使用原生字符串就省去了从字符串实值到re编译器的字符串转义过程,而编译器编译的时候仍然要转义。
b.贪婪匹配与非贪婪匹配
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。如:
import re
print(re.match("ab.*c","abcdfghc"))
匹配的结果为整个字符串。而非贪婪匹配就是匹配到结果就好,最少地匹配字符。python默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
import re
print(re.match("ab.*?c","abcdfghc"))
这样匹配的结果就是“abc”。
三、模块和函数
re模块
compile()编译语法规则
match() 从字符串开头位置开始匹配
search() 从字符串任意位置匹配到第一个符合规则的字符串
findall 以列表形式返回所有匹配到的字符串
finditer 以迭代器形式返回所有匹配到的字符串
split() 拆分字符串
group() 获取匹配到的字符串的分组信息
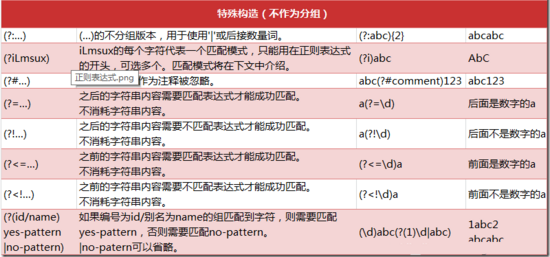
四、特殊构造的规则
总结
以上所述是小编给大家介绍的python正则表达式之对号入座篇,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!