详解PyCharm配置Anaconda的艰难心路历程
在安装好pycharm后,想着anaconda中的类库会比较全,就想着将anaconda配置到pycharm中,这样可以避免以后下载各种类库。
第一步就是要下载并安装anaconda,在安装的过程中历经困难,每次都在最后一步安装失败,报错信息为failed to create anacoda menue?网上也给出了各种解决方案,但是上天好像没有那么眷顾我,每种解决方案都不适用于我,方法如下:
(1)使用默认安装路径,不适用自定义路径
(2)安装路径中不能包含中文字符
(3)系统相对路径过长,修改路径放在盘的根目录下
(4)安装时选择all users,而不是推荐的当前用户
(5)重装操作系统
其中一篇博客提到一句在安装过程中到勾选系统注册系统变量时,勾选第一个按钮会报红色,可能是环境变量中Path的长度过高,会导致anaconda无法自动配置环境变量,
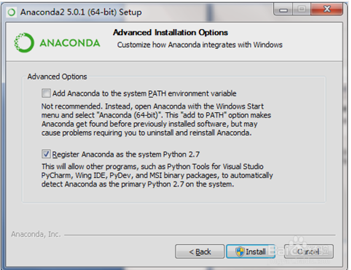
于是我尝试了下将环境变量中Path直接删掉(我这边出现了两个Path,我都删掉了,记住之前要备份,后面好还原),然后再重新安装,成功解决该问题。

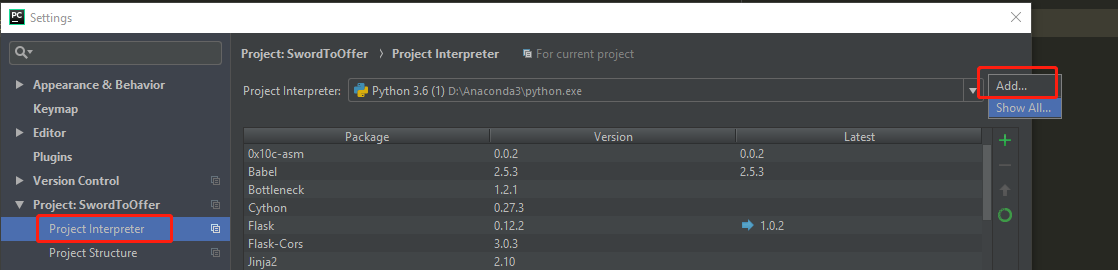
接着是在pycharm中配置anaconda,很多博客写的比较模糊,我自己尝试了下,重新整理了下配置流程。打开File-->Settings-->Project Interpreter,勾选图中圈中按钮。
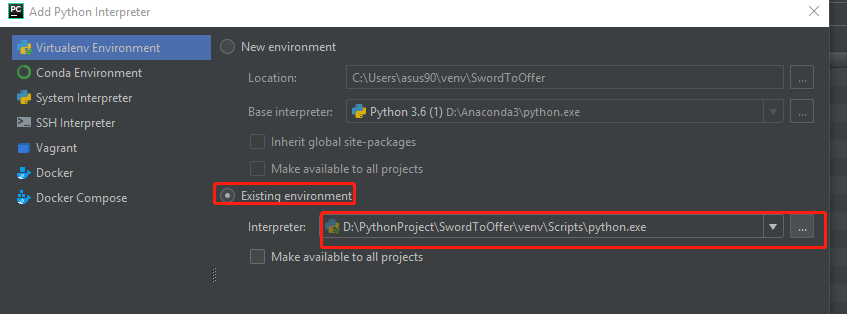
在下图中圈中区域,选择anaconda安装目录下的的python.exe文件,配置即可完成。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
