Python运维自动化之nginx配置文件对比操作示例
本文实例讲述了Python运维自动化之nginx配置文件对比操作。分享给大家供大家参考,具体如下:
文件差异对比diff.py
#!/usr/bin/env python
#
import difflib
import sys
try:
textfile1=sys.argv[1]
textfile2=sys.argv[2]
except exception,e:
print "Error:"+str(2)
print "Usge: difflib.py file1 file2"
sys.exit()
def readfile(filename):
try:
fileHandle=open(filename,'rb')
text=fileHandle.read().splitlines()
fileHandle.close()
return text
except IOError as error:
print ('read file Error:'+str(error))
sys.exit()
if textfile1=="" or textfile2=="":
print "usege :difflib.py file1 file2"
sys.exit()
text1_lines=readfile(textfile1)
text2_lines=readfile(textfile2)
d = difflib.HtmlDiff()
print d.make_file(text1_lines, text2_lines)
#python diff.py nginx1.conf nginx2.conf > diff.html
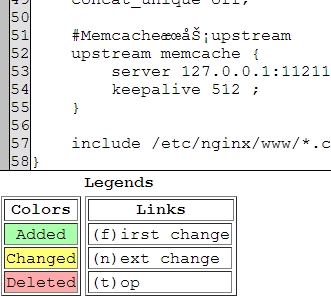
利用的是difflib模块,Python2.3以上版本自带的库
PS:这里再为大家推荐一款相似的在线工具供大家参考:
在线文本比较工具:
http://tools.jb51.net/aideddesign/txt_diff
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python文件与目录操作技巧汇总》、《Python文本文件操作技巧汇总》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。