influx+grafana自定义python采集数据和一些坑的总结
先上网卡数据采集脚本,这个基本上是最大的坑,因为一些数据的类型不正确会导致no datapoint的错误,真是令人抓狂,注意其中几个key的值必须是int或者float类型,如果你不慎写成了string,那就麻烦了,其他的tag是string类型。
另外数据采集时间间隔一般就是10秒,这是潜规则,大家都懂。
有图有真相
#! /usr/bin/env python
#-*- coding:utf-8 -*-
import os
import arrow
import time
from time import sleep
from influxdb import InfluxDBClient
client = InfluxDBClient('localhost', 8086, 'root', '', 'telegraf')
while True:
if int(time.time())%10 == 0:
cmd = 'cat /proc/net/dev|grep "ens4"'
rawline = os.popen(cmd).read().strip()
rxbytes = int(rawline.split()[1])
txbytes = int(rawline.split()[9])
rxpks = int(rawline.split()[2])
txpks = int(rawline.split()[10])
now = str(arrow.now()).split('.')[0] + 'Z'
print time.time(), rxbytes,txbytes,rxpks,txpks
json_body = [
{
"measurement": "network",
"tags": {
"host": "gc-u16",
"nio": "ens4"
},
#"time": now,
"fields": {
"rxbytes": rxbytes,
"txbytes": txbytes,
"rxpks": rxpks,
"txpks": txpks
}
}
]
client.write_points(json_body)
sleep(1)
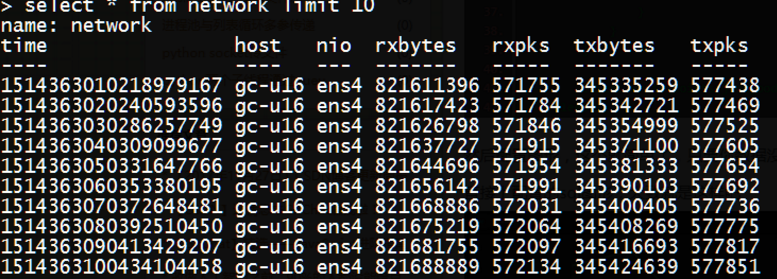
运行脚本,查看influxdb数据,至于后台+独立线程这些东西就见仁见智了
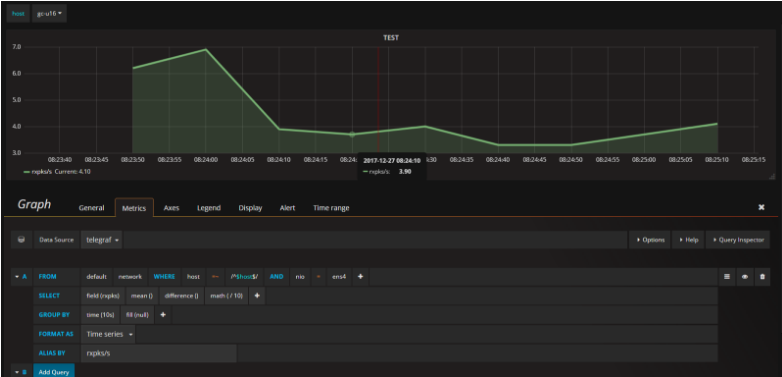
然后配置图形,这个就简单了,只要你数据没写错,基本上grafana都能采集到,这里忽略配置数据源创建dashboard和表格等乱七八糟的,直接上配置的sql图形,大致就是这样吧
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。如果你想了解更多相关内容请查看下面相关链接