Python一行代码实现快速排序的方法
今天将单独为大家介绍一下快速排序!
一、算法介绍
排序算法(Sorting algorithm)是计算机科学最古老、最基本的课题之一。要想成为合格的程序员,就必须理解和掌握各种排序算法。其中"快速排序"(Quicksort)使用得最广泛,速度也较快。它是图灵奖得主C. A. R. Hoare(托尼·霍尔)于1960时提出来的。

二、算法原理
快排的实现方式多种多样,猪哥给大家写一种容易理解的:分治+迭代,只需要三步:
在数列之中,选择一个元素作为"基准"(pivot),或者叫比较值。数列中所有元素都和这个基准值进行比较,如果比基准值小就移到基准值的左边,如果比基准值大就移到基准值的右边以基准值左右两边的子列作为新数列,不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
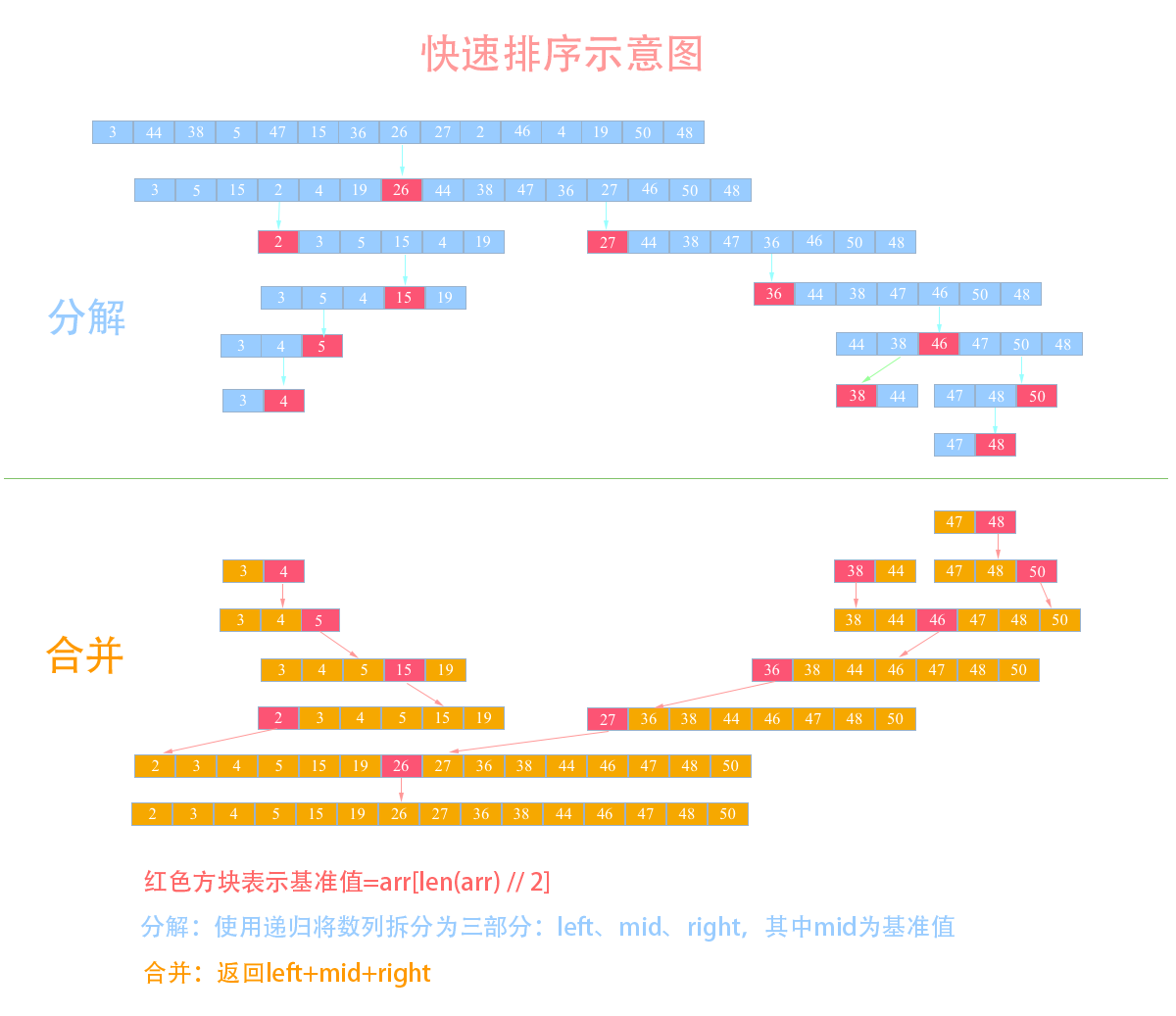
举个例子,假设我现在有一个数列需要使用快排来排序:{3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48},我们来看看使用快排的详细步骤:
选取中间的26作为基准值(基准值可以随便选)数列从第一个元素3开始和基准值26进行比较,小于基准值,那么将它放入左边的分区中,第二个元素44比基准值26大,把它放入右边的分区中,依次类推就得到下图中的第二列。然后依次对左右两个分区进行再分区,得到下图中的第三列,依次往下,直到最后只有一个元素分解完成再一层一层返回,返回规则是:左边分区+基准值+右边分区
三、代码实现
是不是很简洁很秀,如果再有面试官让你手写一个快排,你就把这行写上去吧,面试官见了都要喊你秀儿,哈哈。
在你感叹python吊炸天的同时,你因该考虑到代码的可读性问题,lambda函数设计是为了代码的简洁性,但是滥用的话会导致可读性变得极差,而且现在pep8代码规范中也不建议使用lambda函数了,建议使用关键字def去定义一个函数,所以下面猪哥给大家写一段符合pythonic风格的快排代码
四、算法分析稳定性:
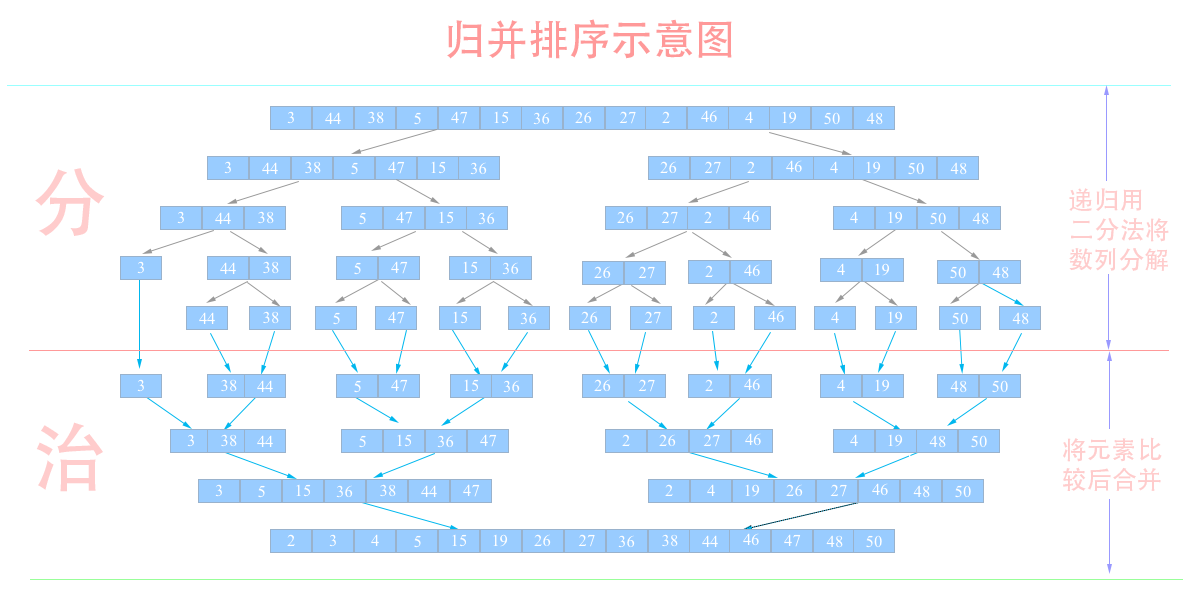
快排是一种不稳定排序,比如基准值的前后都存在与基准值相同的元素,那么相同值就会被放在一边,这样就打乱了之前的相对顺序比较性:因为排序时元素之间需要比较,所以是比较排序时间复杂度:快排的时间复杂度为O(nlogn)空间复杂度:排序时需要另外申请空间,并且随着数列规模增大而增大,其复杂度为:O(nlogn)归并排序与快排 :归并排序与快排两种排序思想都是分而治之,但是它们分解和合并的策略不一样:归并是从中间直接将数列分成两个,而快排是比较后将小的放左边大的放右边,所以在合并的时候归并排序还是需要将两个数列重新再次排序,而快排则是直接合并不再需要排序,所以快排比归并排序更高效一些,可以从示意图中比较二者之间的区别。
五、快排优化
快速排序有一个缺点就是对于小规模的数据集性能不是很好。可能有人认为可以忽略这个缺点不计,因为大多数排序都只要考虑大规模的适应性就行了。但是快速排序算法使用了分治技术,最终来说大的数据集都要分为小的数据集来进行处理,所以快排分解到最后几层性能不是很好,所以我们就可以使用扬长避短的策略去优化快排:
先使用快排对数据集进行排序,此时的数据集已经达到了基本有序的状态然后当分区的规模达到一定小时,便停止快速排序算法,而是改用插入排序,因为我们之前讲过插入排序在对基本有序的数据集排序有着接近线性的复杂度,性能比较好。
这一改进被证明比持续使用快速排序算法要有效的多。
六、模拟面试面试官:
你了解快排吗?你:略知一二面试官:那你讲讲快排的算法思想吧你:快排基本思想是:从数据集中选取一个基准,然后让数据集的每个元素和基准值比较,小于基准值的元素放入左边分区大于基准值的元素放入右边分区,最后以左右两边分区为新的数据集进行递归分区,直到只剩一个元素。面试官:快排有什么优点,有什么缺点?你:分治思想的排序在处理大数据集量时效果比较好,小数据集性能差些。面试官:那该如何优化?你:对大规模数据集进行快排,当分区的规模达到一定小时改用插入排序,插入排序在小数据规模时排序性能较好。面试官:那你能手写一个快排吗?你:
七、总结
以上所述是小编给大家介绍的Python一行代码实现快速排序的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!