使用Python如何测试InnoDB与MyISAM的读写性能
前言
由于近期有个项目对系统性能要求很高,技术选型上由于种种原因已经确定使用Mysql数据库,接下来就是要确定到底使用哪种存储引擎。我们的应用是典型的写多读少,写入内容为也很短,对系统的稳定性要求很高。所以存储引擎肯定就定在广泛使用的Innodb和MyISAM之中了。
至于两者的比较网上也有很多,但是毕竟这个事情也不复杂,决定还是自己来做,去验证一下在我们的场景下谁更优。
本文测试所用工具版本如下:
| Tools | Version |
|---|---|
| MySQL | 5.7.18 |
| Python | 3.6 |
| Pandas | 0.23 |
① 创建数据表
首先我们需要把两张使用了不同引擎的表创建出来,使用为了方便起见,我们直接使用Navicat创建了两张 员工信息表,具体字段如下:

使用InnoDB引擎的表,设计表名为innodb,选项如下:
使用InnoDB引擎的表,设计表名为myisam,选项如下:
因为是简单操作,创建的具体细节就不详述了,至此,我们的数据库就把使用 InnoDB 和 MyISAM 两种引擎的表创建好了。
② 单线程写入性能对比
1. InnoDB 引擎
执行以下代码,往使用了InnoDB引擎的表格插入1000条数据
import pandas as pd
from sqlalchemy import create_engine
import time
db = create_engine('mysql+pymysql://mysql:123456@127.0.0.1:3306/test')
start = time.time()
for i in range(1000):
data = {'index': i,
'name': 'name_' + str(i),
'age': i,
'salary': i,
'level': i}
df = pd.DataFrame(data, index=[0])
df.to_sql('innodb', db, if_exists='append', index=False)
end = time.time()
print(end - start)
执行3次上面的代码,得到程序写入1000条数据的时间分别为:12.58s、14.10s、12.71s,平均写入时间为 13.13s。
2. MyISAM 引擎
执行以下代码,往使用了MyISAM引擎的表格插入1000条数据
import pandas as pd
from sqlalchemy import create_engine
import time
db = create_engine('mysql+pymysql://mysql:123456@127.0.0.1:3306/test')
start = time.time()
for i in range(1000):
data = {'index': i,
'name': 'name_' + str(i),
'age': i,
'salary': i,
'level': i}
df = pd.DataFrame(data, index=[0])
df.to_sql('myisam', db, if_exists='append', index=False)
end = time.time()
print(end - start)
执行3次上面的代码,得到程序写入1000条数据的时间分别为:6.64s、6.99s、7.29s,平均写入时间为 6.97s。
两种引擎的单线程写入速度对比如下:

结论:单线程的情况下,MyISAM引擎的写入速度比InnoDB引擎的写入速度快88%
③ 多线程写入性能对比
1. InnoDB 引擎
执行以下代码,往使用了InnoDB引擎的表格插入1000条数据
import pandas as pd
from sqlalchemy import create_engine
import time
from concurrent.futures import ThreadPoolExecutor
db = create_engine('mysql+pymysql://mysql:123456@127.0.0.1:3306/test')
start = time.time()
data_lst = [{'index': i,
'name': 'name_' + str(i),
'age': i,
'salary': i,
'level': i} for i in range(1000)]
def write(data):
df = pd.DataFrame(data, index=[0])
df.to_sql('innodb', db, if_exists='append', index=False)
def execute():
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(write, data_lst)
execute()
end = time.time()
print(end - start)
执行3次上面的代码,得到程序写入1000条数据的时间分别为:4.98s、4.84s、4.88s,平均写入时间为 4.9s。
2. MyISAM 引擎
执行以下代码,往使用了MyISAM引擎的表格插入1000条数据
import pandas as pd
from sqlalchemy import create_engine
import time
from concurrent.futures import ThreadPoolExecutor
db = create_engine('mysql+pymysql://mysql:123456@127.0.0.1:3306/test')
start = time.time()
data_lst = [{'index': i,
'name': 'name_' + str(i),
'age': i,
'salary': i,
'level': i} for i in range(1000)]
def write(data):
df = pd.DataFrame(data, index=[0])
df.to_sql('myisam', db, if_exists='append', index=False)
def execute():
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(write, data_lst)
execute()
end = time.time()
print(end - start)
执行3次上面的代码,得到程序写入1000条数据的时间分别为:3.29s、3.62s、3.47s,平均写入时间为 3.46s。
两种引擎的多线程写入速度对比如下:
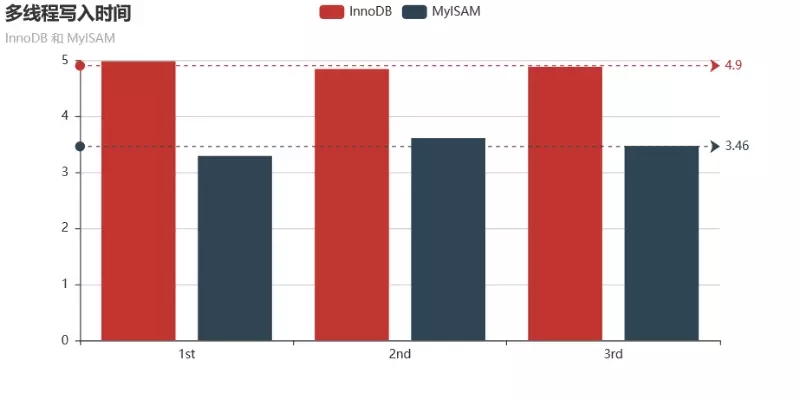
结论:多线程的情况下,MyISAM引擎的写入速度比InnoDB引擎的写入速度快42%
④ 读取性能对比
为了获得数据量较大的表用于测试数据库的读取性能,我们循环执行10遍上面多线程写入数据的操作,得到两张数据量为10000条数据的表格,然后读取10遍该表格,获取读取时间
1. InnoDB 引擎
执行以下代码,读取10遍使用了InnoDB引擎的表格
import pandas as pd
from sqlalchemy import create_engine
import time
db = create_engine('mysql+pymysql://mysql:123456@127.0.0.1:3306/test')
start = time.time()
for _ in range(10):
df = pd.read_sql('innodb', db)
end = time.time()
print(end - start)
执行3次上面的代码,得到程序10次读取10000条数据的时间分别为:28.94s、28.88s、28.48s,平均写入时间为 28.77s。
2. MyISAM 引擎
执行以下代码,读取10遍使用了MyISAM引擎的表格
import pandas as pd
from sqlalchemy import create_engine
import time
db = create_engine('mysql+pymysql://mysql:123456@127.0.0.1:3306/test')
start = time.time()
for _ in range(10):
df = pd.read_sql('innodb', db)
end = time.time()
print(end - start)
执行3次上面的代码,得到程序10次读取10000条数据的时间分别为:28.51s、29.12s、28.76s,平均写入时间为 28.8s。
两种引擎的读取速度对比如下:
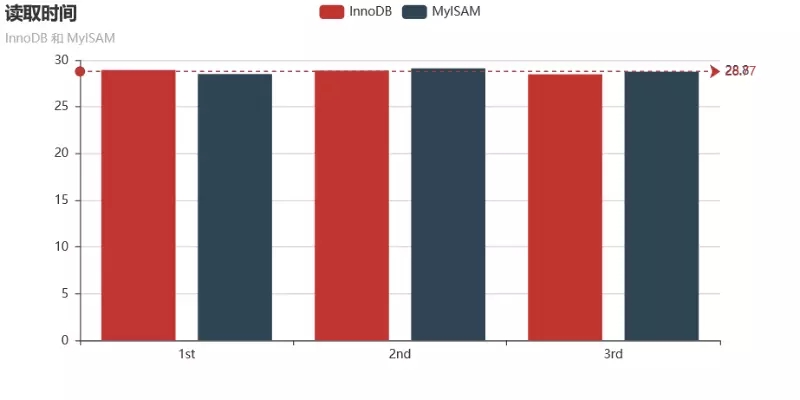
结论:MyISAM引擎和InnoDB引擎的读取速度无明显差异
⑤ 总结
1. 写入速度,MyISAM比InnoDB快,单线程的情况下,两者差异尤为明显
2. 读取速度,InnoDB和MyISAM无明显差异
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对【听图阁-专注于Python设计】的支持。