详解分布式任务队列Celery使用说明
起步
Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。它是一个专注于实时处理的任务队列,同时也支持任务调度。
运行模式是生产者消费者模式:
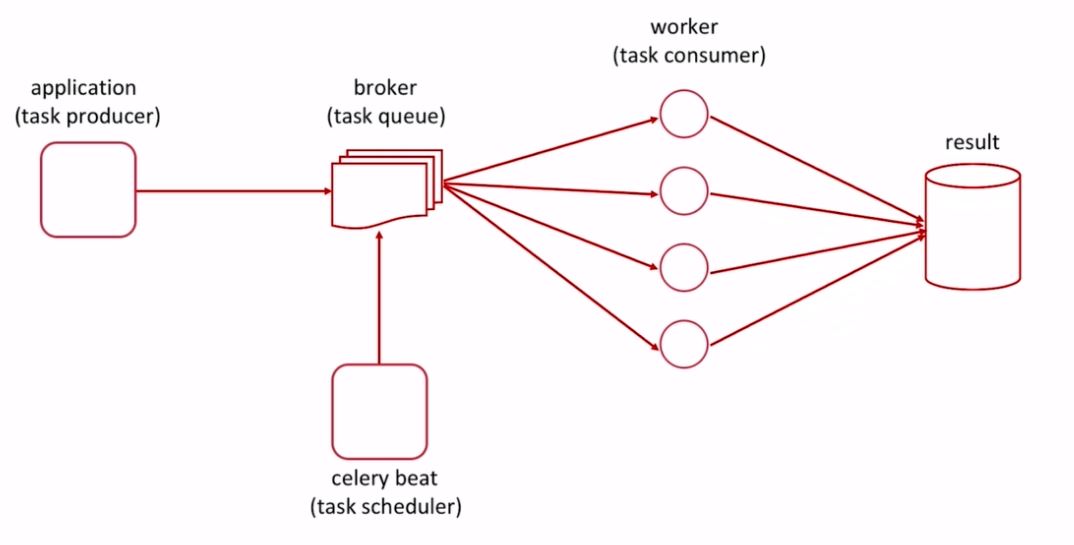
任务队列:任务队列是一种在线程或机器间分发任务的机制。
消息队列:消息队列的输入是工作的一个单元,称为任务,独立的职程(Worker)进程持续监视队列中是否有需要处理的新任务。
Celery 用消息通信,通常使用中间人(Broker)在客户端和职程间斡旋。这个过程从客户端向队列添加消息开始,之后中间人把消息派送给职程,职程对消息进行处理。
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件:Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成,包括,RabbitMQ, Redis, MongoDB等,本文使用 redis 。
任务执行单元:Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中
任务结果存储:Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括Redis,MongoDB,Django ORM,AMQP等,这里我先不去看它是如何存储的,就先选用Redis来存储任务执行结果。
安装
通过 pip 命令即可安装:
pip install celery
本文使用 redis 做消息中间件,所以需要在安装:
pip install redis
redis软件也要安装,官网只提供了 linux 版本的下载:https://redis.io/download,windows 的可以到 https://github.com/MicrosoftArchive/redis 下载 exe 安装包。
简单的demo
为了运行一个简单的任务,从中说明 celery 的使用方式。在项目文件夹内创建 app.py 和 tasks.py 。tasks.py 用来定义任务:
# tasks.py
import time
from celery import Celery
broker = 'redis://127.0.0.1:6379/1'
backend = 'redis://127.0.0.1:6379/2'
app = Celery('my_tasks', broker=broker, backend=backend)
@app.task
def add(x, y):
print('enter task')
time.sleep(3)
return x + y
这些代码做了什么事。 broker 指定任务队列的消息中间件,backend 指定了任务执行结果的存储。app 就是我们创建的 Celery 对象。通过 app.task 修饰器将 add 函数变成一个一部的任务。
# app.py
from tasks import add
if __name__ == '__main__':
print('start task')
result = add.delay(2, 18)
print('end task')
print(result)
add.delay 函数将任务序列化发送到消息中间件。终端执行 python app.py 可以看到输出一个任务的唯一识别:
start task
end task
79ef4736-1ecb-4afd-aa5e-b532657acd43
这个只是将任务推送到 redis,任务还没被消费,任务会在 celery 队列中。
开启 celery woker 可以将任务进行消费:
celery worker -A tasks -l info # -A 后是模块名
A 参数指定了celery 对象的位置,l 参数指定woker的日志级别。
如果此命令在终端报错:
File "e:\workspace\.env\lib\site-packages\celery\app\trace.py", line 537, in _fast_trace_task
tasks, accept, hostname = _loc
ValueError: not enough values to unpack (expected 3, got 0)
这是win 10 在使用 Celery 4.x 的时候会有这个问题,解决方式可以是改用 Celery 3.x 版本,或者按照 Unable to run tasks under Windows 上提供的方式,该issue提供了两种方式解决,一种是安装 eventlet 扩展:
pip install eventlet celery -A <mymodule> worker -l info -P eventlet
另一种方式是添加个 FORKED_BY_MULTIPROCESSING = 1 的环境变量(推荐这种方式):
import os
os.environ.setdefault('FORKED_BY_MULTIPROCESSING', '1')
如果一切顺利,woker 正常启动,就能在终端看到任务被消费了:
[2018-11-27 13:59:27,830: INFO/MainProcess] Received task: tasks.add[745e5be7-4675-4f84-9d57-3f5e91c33a19]
[2018-11-27 13:59:27,831: WARNING/SpawnPoolWorker-2] enter task
[2018-11-27 13:59:30,835: INFO/SpawnPoolWorker-2] Task tasks.add[745e5be7-4675-4f84-9d57-3f5e91c33a19] succeeded in 3.0s: 20
说明我们的demo已经成功了。
使用配置文件
在上面的demo中,是将broker和backend直接写在代码中的,而 Celery 还有其他配置,最好是写出配置文件的形式,基本配置项有:
- CELERY_DEFAULT_QUEUE:默认队列
- BROKER_URL : 代理人的网址
- CELERY_RESULT_BACKEND:结果存储地址
- CELERY_TASK_SERIALIZER:任务序列化方式
- CELERY_RESULT_SERIALIZER:任务执行结果序列化方式
- CELERY_TASK_RESULT_EXPIRES:任务过期时间
- CELERY_ACCEPT_CONTENT:指定任务接受的内容序列化类型(序列化),一个列表;
整理一下目录结构,将我们的任务封装成包:
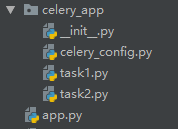
内容如下:
# __init__.py
import os
from celery import Celery
os.environ.setdefault('FORKED_BY_MULTIPROCESSING', '1')
app = Celery('demo')
# 通过 Celery 实例加载配置模块
app.config_from_object('celery_app.celery_config')
# celery_config.py
BROKER_URL = 'redis://127.0.0.1:6379/1'
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/2'
# UTC
CELERY_ENABLE_UTC = True
CELERY_TIMEZONE = 'Asia/Shanghai'
# 导入指定的任务模块
CELERY_IMPORTS = (
'celery_app.task1',
'celery_app.task2',
)
# task1.py
import time
from celery_app import app
@app.task
def add(x, y):
print('enter task')
time.sleep(3)
return x + y
# task2.py
import time
from celery_app import app
@app.task
def mul(x, y):
print('enter task')
time.sleep(4)
return x * y
# app.py
from celery_app import task1
if __name__ == '__main__':
pass
print('start task')
result = task1.add.delay(2, 18)
print('end task')
print(result)
提交任务与启动worker:
$ python app.py $ celery worker -A celery_app -l info
result = task1.add.delay(2, 18) 返回的是一个任务对象,通过 delay 函数的方式可以发现这个过程是非阻塞的,这个任务对象有一个方法:
r.ready() # 查看任务状态,返回布尔值, 任务执行完成, 返回 True, 否则返回 False. r.wait() # 等待任务完成, 返回任务执行结果,很少使用; r.get(timeout=1) # 获取任务执行结果,可以设置等待时间 r.result # 任务执行结果. r.state # PENDING, START, SUCCESS,任务当前的状态 r.status # PENDING, START, SUCCESS,任务当前的状态 r.successful # 任务成功返回true r.traceback # 如果任务抛出了一个异常,你也可以获取原始的回溯信息
定时任务
定时任务的功能类似 crontab,可以完成每日统计任务等。首先我们需要配置一下 schedule,通过改造上面的配置文件,添加 CELERYBEAT_SCHEDULE 配置:
import datetime
from celery.schedules import crontab
CELERYBEAT_SCHEDULE = {
'task1-every-1-min': {
'task': 'celery_app.task1.add',
'schedule': datetime.timedelta(seconds=60),
'args': (2, 15),
},
'task2-once-a-day': {
'task': 'celery_app.task2.mul',
'schedule': crontab(hour=15, minute=23),
'args': (3, 6),
}
}
task 指定要执行的任务;schedule 表示计划的时间,datetime.timedelta(seconds=60) 表示间隔一分钟,这里其实也可以是 crontab(minute='*/1') 来替换;args 表示要传递的参数。
启动 celery beat:
$ celery worker -A celery_app -l info
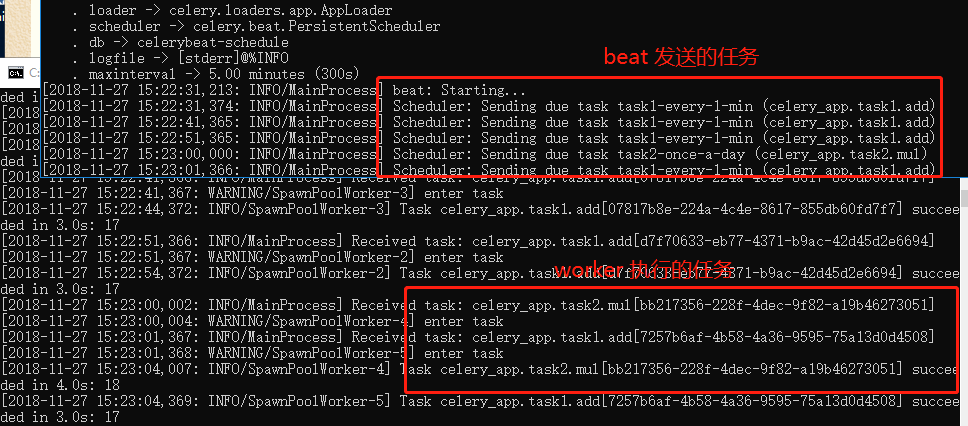
我们目前是用两个窗口来执行 woker 和 beat 。当然也可以只使用一个窗口来运行(仅限linux系统):
$ celery -B -A celery_app worker -l info
celery.task 装饰器
@celery.task() def name(): pass
task() 方法将任务修饰成异步, name 可以显示指定的任务名字;serializer 指定序列化的方式;bind 一个bool值,若为True,则task实例会作为第一个参数传递到任务方法中,可以访问task实例的所有的属性,即前面反序列化中那些属性。
@task(bind=True) # 第一个参数是self,使用self.request访问相关的属性 def add(self, x, y): logger.info(self.request.id)
base 可以指定任务积累,可以用来定义回调函数:
import celery
class MyTask(celery.Task):
# 任务失败时执行
def on_failure(self, exc, task_id, args, kwargs, einfo):
print('{0!r} failed: {1!r}'.format(task_id, exc))
# 任务成功时执行
def on_success(self, retval, task_id, args, kwargs):
pass
# 任务重试时执行
def on_retry(self, exc, task_id, args, kwargs, einfo):
pass
@task(base=MyTask)
def add(x, y):
raise KeyError()
exc:失败时的错误的类型;
task_id:任务的id;
args:任务函数的参数;
kwargs:参数;
einfo:失败时的异常详细信息;
retval:任务成功执行的返回值;
总结
网上找了一份比较常用的配置文件,需要的时候可以参考下:
# 注意,celery4版本后,CELERY_BROKER_URL改为BROKER_URL
BROKER_URL = 'amqp://username:passwd@host:port/虚拟主机名'
# 指定结果的接受地址
CELERY_RESULT_BACKEND = 'redis://username:passwd@host:port/db'
# 指定任务序列化方式
CELERY_TASK_SERIALIZER = 'msgpack'
# 指定结果序列化方式
CELERY_RESULT_SERIALIZER = 'msgpack'
# 任务过期时间,celery任务执行结果的超时时间
CELERY_TASK_RESULT_EXPIRES = 60 * 20
# 指定任务接受的序列化类型.
CELERY_ACCEPT_CONTENT = ["msgpack"]
# 任务发送完成是否需要确认,这一项对性能有一点影响
CELERY_ACKS_LATE = True
# 压缩方案选择,可以是zlib, bzip2,默认是发送没有压缩的数据
CELERY_MESSAGE_COMPRESSION = 'zlib'
# 规定完成任务的时间
CELERYD_TASK_TIME_LIMIT = 5 # 在5s内完成任务,否则执行该任务的worker将被杀死,任务移交给父进程
# celery worker的并发数,默认是服务器的内核数目,也是命令行-c参数指定的数目
CELERYD_CONCURRENCY = 4
# celery worker 每次去rabbitmq预取任务的数量
CELERYD_PREFETCH_MULTIPLIER = 4
# 每个worker执行了多少任务就会死掉,默认是无限的
CELERYD_MAX_TASKS_PER_CHILD = 40
# 这是使用了django-celery默认的数据库调度模型,任务执行周期都被存在你指定的orm数据库中
# CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler'
# 设置默认的队列名称,如果一个消息不符合其他的队列就会放在默认队列里面,如果什么都不设置的话,数据都会发送到默认的队列中
CELERY_DEFAULT_QUEUE = "default"
# 设置详细的队列
CELERY_QUEUES = {
"default": { # 这是上面指定的默认队列
"exchange": "default",
"exchange_type": "direct",
"routing_key": "default"
},
"topicqueue": { # 这是一个topic队列 凡是topictest开头的routing key都会被放到这个队列
"routing_key": "topic.#",
"exchange": "topic_exchange",
"exchange_type": "topic",
},
"task_eeg": { # 设置扇形交换机
"exchange": "tasks",
"exchange_type": "fanout",
"binding_key": "tasks",
},
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。