python+unittest+requests实现接口自动化的方法
前言:
Requests简介
Requests 是使用Apache2 Licensed 许可证的 HTTP 库。用 Python 编写,真正的为人类着想。
Python 标准库中的 urllib2 模块提供了你所需要的大多数 HTTP 功能,但是它的 API 有点落后了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务。
总之,大家建议大家用Requests吧。
Requests的官方文档:http://cn.python-requests.org/zh_CN/latest/
通过下面方法安装requests
pip install requests
实例实现步骤:
1.采用unittest把每个接口写成一个个测试脚本
2.一个测试脚本中包含一个接口,但是可以包含多个测试用例(即每个接口需要进行多种情况的验证,接口测试用例名称已test开头)
3.使用discover(),该方法会自动根据测试目录匹配查找测试用例文件,并且将查找到的测试组装到测试套件中,因此可以直接通过run()方法执行discover,大大简化了测试用例的查找和执行
4.利用HTMLTestRunner生成测试报告
文档结构:project项目文件下有以下三个文件
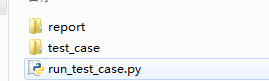
1.report存放测试结果
2.test_case存放测试用例
3.run_test_case.py执行测试用例文件
案例:
1.get接口测试用例源码
# coding:utf-8
import requests
import unittest
class get_request(unittest.TestCase):
def setUp(self):
self.get_url = 'https://www.baidu.com/'
def test_post_01(self):
url=self.get_url
r = requests.get(url)
print r.text
def tearDown(self):
pass
if __name__ == "__main__":
unittest.main()
2.post接口测试用例源码
# coding:utf-8
import requests
import json
import unittest
class post_request(unittest.TestCase):
def setUp(self):
self.post_url = '..........' #根据实际接口,自己填写
self.header = {'.......'} #根据实际内容,自己填写
def test_post_01(self):
"""正常数据"""
url=self.post_url
header = self.header
data = {""}#根据实际内容,自己填写
#将data序列化为json格式数据,传递给data参数
r = requests.post(url, data=json.dumps(data), headers=header)
print r.text
def test_post_02(self):
"""异常数据"""
url=self.post_url
header = self.header
data = {""}#根据实际内容,自己填写
r = requests.post(url, data=json.dumps(data), headers=header)
print r.text
def tearDown(self):
pass
if __name__ == "__main__":
unittest.main()
3.执行测试用例源码
# coding=utf-8
import unittest
import HTMLTestRunner
import time
# 相对路径
test_dir ='./test_case'
test_dir1 ='./report'
discover = unittest.defaultTestLoader.discover(test_dir, pattern='test*.py')
# 定义带有当前测试时间的报告,防止前一次报告被覆盖
now = time.strftime("%Y-%m-%d %H_%M_%S")
filename = test_dir1 + '/' + now + 'result.html'
# 二进制打开,准备写入文件
fp = file(filename, 'wb')
# 定义测试报告
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u'测试报告', description=u'用例执行情况')
runner.run(discover)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。