浅谈python下含中文字符串正则表达式的编码问题
前言
Python文件默认的编码格式是ascii ,无法识别汉字,因为ascii码中没有中文。
所以py文件中要写中文字符时,一般在开头加 # -*- coding: utf-8 -*- 或者 #coding=utf-8。
这是指定一种编码格式,意味着用该编码存储中文字符(也可以是gbk、gb2312等)。
关于测试的几点注意 --------------------------------------------
注1:代码中有中文,就要在头部指定编码方式,如果用编辑器写代码,还要注意IDE的文件存储编码格式(一般在setting)
注2:python3.x的源码文件默认使用utf-8编码,可以解析中文,开头不指定也行,但为了规范和避免一些意想不到的问题,都指定一下为好
注3:linux交互式命令(左)和py文件(右)的运行结果会有不同:
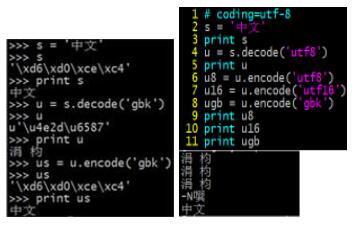
左图,因为我cmd设置了gbk编码格式,所以u是s用gbk解码后的unicode对象,配套的解编码才能使原中文字符在print下正常显示,所以再用gbk编码;右图,py文件指定了utf8编码,所以u是s用utf8解码后的unicode对象(其他方式会运行错误),而且想要在屏幕上打印出中文,还须encode成cmd设置的编码(其他方式显示乱码)。
注4:测试中文字符的显示和匹配时,最好用py文件写,否则遇到两边不一样的情况就会感到十分坑爹
----------------------------------------------------------------
下面实验是基于python2.7和linux系统,不测试windows控制台和windows下的IDE;
下面实验是关于为了正常显示中文和正则匹配中文的转码测试。
(一)python的str和中文字符串
简单理解,编码意味着 unicode -> ch-str,解码意味着 ch-str -> unicode,
关于print显示中文。举个例子,用gb18030和utf-8编码的内容相同的两份文档测试:
#coding=utf-8
import sys
with open('ch_input_gbk', 'r') as f1, open('ch_input_utf', 'r') as f2:
for l1 in f1:
lines = l1.strip().split('\t') # lines是list, 通过打印它可以看看str不同编码的内容
sent = lines[0] # sent是ch-str
print lines, sent
for l2 in f2:
lines = l2.strip().split('\t')
sent = lines[0]
print lines, sent
print sent.decode('utf8').encode('gbk')
#print str(sent).decode('string_escape').decode('utf8').encode('gbk')
输出:
['\xd3\xc4\xc8\xcb\xd6\xf1\xc9\xa3\xd4\xb0'] 幽人竹桑园 ['\xb9\xe9\xce\xd4\xbc\xc5\xce\xde\xd0\xfa'] 归卧寂无喧 ['\xce\xef\xc7\xe9\xbd\xf1\xd2\xd1\xbc\xfb'] 物情今已见 ['\xb4\xd3\xb4\xcb\xd3\xfb\xce\xde\xd1\xd4'] 从此欲无言 ['\xe5\xb9\xbd\xe4\xba\xba\xe7\xab\xb9\xe6\xa1\x91\xe5\x9b\xad'] 骞戒汉绔规鍥 幽人竹桑园 ['\xe5\xbd\x92\xe5\x8d\xa7\xe5\xaf\x82\xe6\x97\xa0\xe5\x96\xa7'] 褰掑崸瀵傛棤鍠 归卧寂无喧 ['\xe7\x89\xa9\xe6\x83\x85\xe4\xbb\x8a\xe5\xb7\xb2\xe8\xa7\x81'] 鐗╂儏浠婂凡瑙 物情今已见 ['\xe4\xbb\x8e\xe6\xad\xa4\xe6\xac\xb2\xe6\x97\xa0\xe8\xa8\x80'] 浠庢娆叉棤瑷 从此欲无言
line7,f1的sent正常显示是因为,txt是gb18030编码,读入后仍为此(这与首行的#coding可不一样),我的cmd同样也是gb18030
line11,f2的sent乱码显示是因为,txt是utf8编码,读入后仍为此,但是print对str是按cmd设置的编码格式解读的
line12,sent又能正常显示是因为,utf8解码 -> unicode -> 编码为gb18030,所以print可以正常解读了
line13,有时读入或抓取的中文不是\xd3\xc4而是这个样子的\\xd3\\xc4,这是\被转义了,对它无法做decode转换编码,先用str(sent).decode('string_escape'),把反斜杠的转义去掉,然后就和第12行一样了
附,12行如果直接写 sent.encode('gbk') 会报错:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0
是说,当前位置这个str不能被py默认的ascii解码,因为它是中文str;要用它的实际编码来解码而不是ascii:
1 修改py默认编码,由ascii改为当前str实际编码(utf8或gb18030等)
reload(sys)
sys.setdefaultencoding('utf8')
2 但是读入多个文档含有多个编码方式时,1的方法就不方便,还是对不同的ch-str都采用unicode转换编码较好 (上面例子中的方式)
(二)中文字符串的正则匹配
只有一项标准,匹配字符串和原字符串编码统一,
还是举例子,
# -*- coding: utf-8 -*-
import re
def findPart(regex, text, name):
res = re.findall(regex, text)
print "There are %d %s parts:" % (len(res), name)
for r in res:
print r.encode('gbk')
sample = '''en: Regular expression is a powerful tool for manipulating text.
zh: 正则表达式是一种很有用的处理文本的工具。
jp: 正規表現は非常に役に立つツールテキストを操作することです。
jp-char: あアいイうウえエおオ
kr:정규 표현식은 매우 유용한 도구 텍스트를 조작하는 것입니다.
puc: ,。?!:,.?!:《》%&*#<>%&*#
'''
#convert the utf8 to unicode
usample = unicode(sample,'utf8') #相当于usample = sample.decode('utf8')
#get each language parts:
findPart(u"[\u4e00-\u9fa5]+", usample, "unicode chinese")
findPart(u"[\uac00-\ud7ff]+", usample, "unicode korean")
findPart(u"[\u30a0-\u30ff]+", usample, "unicode japanese katakana")
findPart(u"[\u3040-\u309f]+", usample, "unicode japanese hiragana")
findPart(u"[\u3000-\u303f\ufb00-\ufffd]+", usample, "unicode cjk Punctuation")
line20,目标字符串usample是unicode类型,故匹配字符串regex也要同(如u"[\u4e00-\u9fa5]+"),u就是转成unicode;
line7,usample是unicode,要想print正确显示,则需要r.encode('gbk'),根据cmd的编码格式;
正则匹配规则不多述,[\u????-\u????] 是不同语言的unicode编码段,该例输出是,
中文6个part:正则表达式是一种很有用的处理文本的工具、正規表現、非常、役、立、操作
韩文8个part:정규、표현식은、매우、유용한、도구、텍스트를、조작하는、것입니다
日文片假名6个part:ツールテキスト、ア、イ、ウ、エ、オ
日文平假名11个part:は、に、に、つ、を、することです、あ、い、う、え、お
非英文标点4个part:。、。、,。?!:、《》%&*#
另外,简单的正则匹配,举几个例子,
s1 = '天天天向上天天向上'
print (re.sub(ur'[\u4e00-\u9fa5]{1,}', u'1', s1.decode('utf8'))).encode('gbk') # 1
print (re.sub(ur'([\u4e00-\u9fa5])\1{1,}', u'1', s1.decode('utf8'))).encode('gbk') # 1向上1向上
print (re.sub(ur'([\u4e00-\u9fa5])\1{2,}', u'1', s1.decode('utf8'))).encode('gbk') # 1向上天天向上
s2 = '【aa】天天bb@cc'
print (re.sub(ur'【.*】', u'1', s2.decode('utf8'))).encode('gbk') # 1天天bb@cc
print (re.sub(ur'@', u'1', s2.decode('utf8'))).encode('gbk') # 【aa】天天bb1cc
line2,{1,}匹配1~n个前面表达式,故6个汉字全部匹配
line3,()内为一个group,\1指第一个group,{1,}要再匹配1~n个前面group内容(若group内是1个字, {1,}要匹配第2个及往后的字),故匹配了3个天和2个天
line6和7,中英文标点符号匹配,regex没有转义符的话可以不写r,若text全是英文也可以不写u
以上这篇浅谈python下含中文字符串正则表达式的编码问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。