Pandas读取并修改excel的示例代码
一、前言
最近总是和excel打交道,由于数据量较大,人工来修改某些数据可能会有点浪费时间,这时候就使用到了Python数据处理的神器—–Pandas库,话不多说,直接上Pandas。
二、安装
这次使用的python版本是python2.7,安装python可以去python的官网进行下载,这里不多说了。
安装完成后使用Python自带的包管理工具pip可以很快的安装pandas。
pip install pandas
如果使用的是Anaconda安装的Python,会自带pandas。
三、read_excel()介绍
首先可以先创建一个excel文件当作实验数据,名称为example.xlsx,内容如下:
| name | age | gender |
|---|---|---|
| John | 30 | male |
| Mary | 22 | female |
| Smith | 32 | male |
这里是很简单的几行数据,我们来用pandas实际操作一下这个excel表。
# coding:utf-8
import pandas as pd
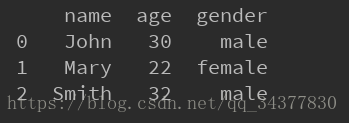
data = pd.read_excel('example.xlsx', sheet_name='Sheet1')
print data
结果如下:
这里使用了read_excel()方法来读取excel,来看一个read_excel()这个方法的API,这里只截选一部分经常使用的参数:
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None)
这里主要参数为io,sheet_name,header,usecols和names
- io:excel文件,如果命名为中文,在python2.7中,需要使用decode()来解码成unicode字符串,例如: pd.read_excel('示例'.decode('utf-8))
- sheet_name:返回指定的sheet,如果将sheet_name指定为None,则返回全表,如果需要返回多个表,可以将sheet_name指定为一个列表,例如['sheet1', 'sheet2']
- header:指定数据表的表头,默认值为0,即将第一行作为表头。
- usecols:读取指定的列,例如想要读取第一列和第二列数据:
pd.read_excel("example.xlsx", sheet_name=None, usecols=[0, 1])
四、使用
这里先来一个在机器学习中经常使用的:将所有gender为male的值改为0,female改为1。
# coding:utf-8
import pandas as pd
from pandas import DataFrame
# 读取文件
data = pd.read_excel("example.xlsx", sheet_name="Sheet1")
# 找到gender这一列,再在这一列中进行比较
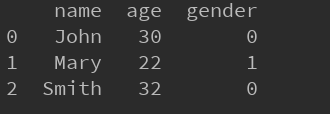
data['gender'][data['gender'] == 'male'] = 0
data['gender'][data['gender'] == 'female'] = 1
print data
结果如下:
需要注意的是,这里的data为excel数据的一份拷贝,对data进行修改并不会直接影响到我们原来的excel,必须在修改后保存才能够修改excel。保存的代码如下:
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)
这时候我们再打开example.xlsx文件看看是否更改了:
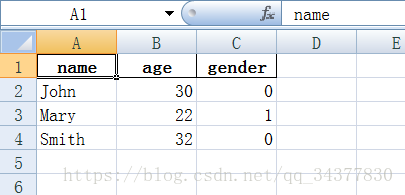
如果我们想要新增加一列或者一行数据怎么办呢?这里给出参考:
新增列数据:
data['列名称'] = None
新增行数据,这里行的num为excel中自动给行加的id数值
data.loc[行的num] = [值1, 值2, ...]
以上面的数据为例:
# coding:utf-8
import pandas as pd
from pandas import DataFrame
data = pd.read_excel("example.xlsx", sheet_name='Sheet1')
# 增加行数据,在第5行新增
data.loc[5] = ['James', 32, 'male']
# 增加列数据,给定默认值None
data['profession'] = None
# 保存数据
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)
打开excel看到的结果如下:
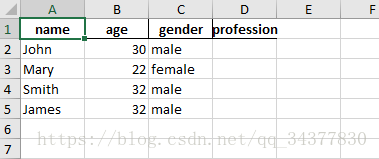
说完了增加一行或一列,那怎样删除一行或一列呢?
import pandas as pd
from pandas import DataFrame
data = pd.read_excel("example.xlsx", sheet_name='Sheet1')
# 删除gender列,需要指定axis为1,当删除行时,axis为0
data = data.drop('gender', axis=1)
# 删除第3,4行,这里下表以0开始,并且标题行不算在类
data = data.drop([2, 3], axis=0)
# 保存
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)
这时候打开excel可以看见gender列和除标题行的第3,4行被删除了。
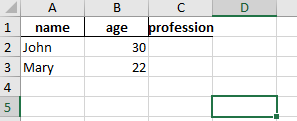
总结
pandas除了上述的基本功能以外,还有其它更高级的操作,想要进一步学习的小伙伴们可以去pandas网站进行学习。