python使用百度文字识别功能方法详解
介绍python使用百度智能去的文字识别功能,可以识别截图中的文,登陆路验证码等等。,
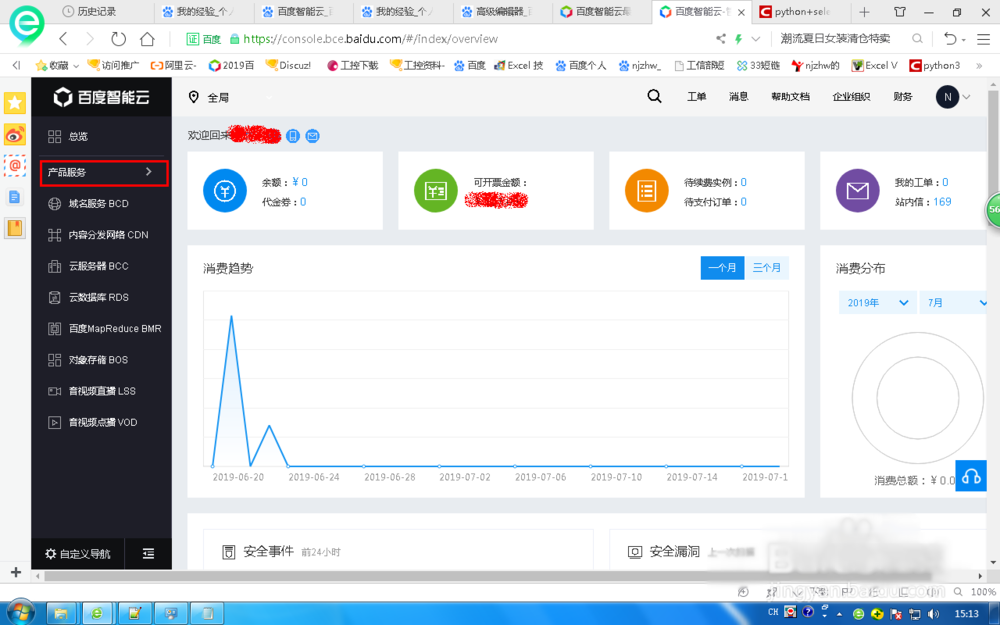
登陆百度智能云,选择产品服务。
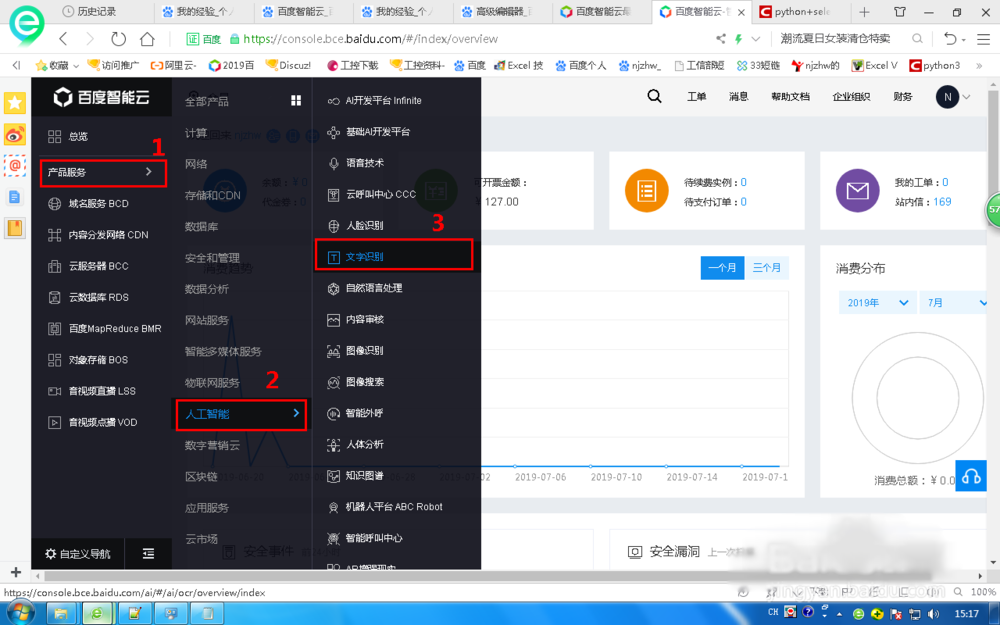
选择“人工智能”---文字识别。
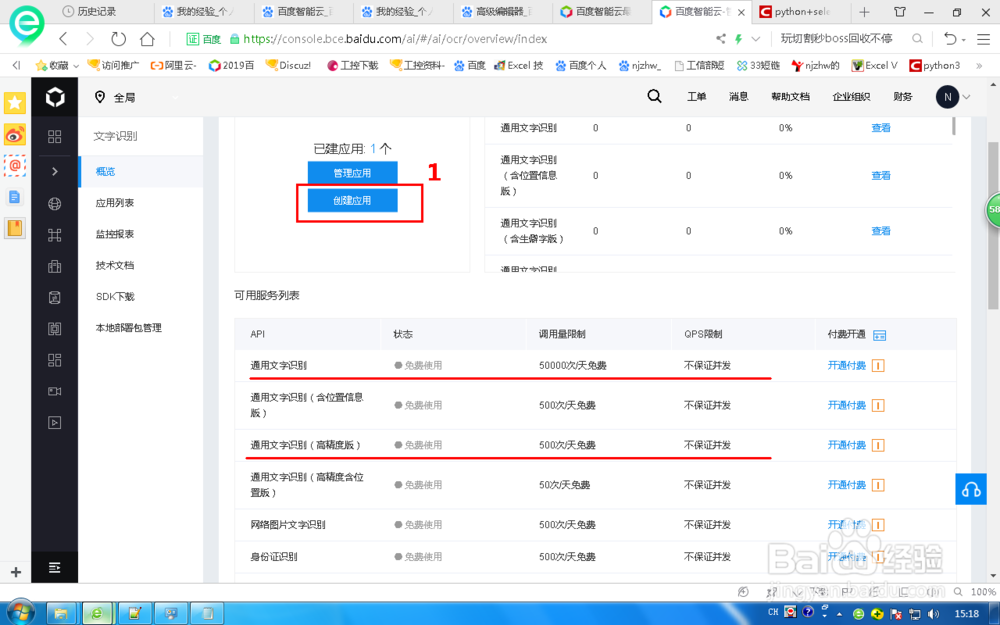
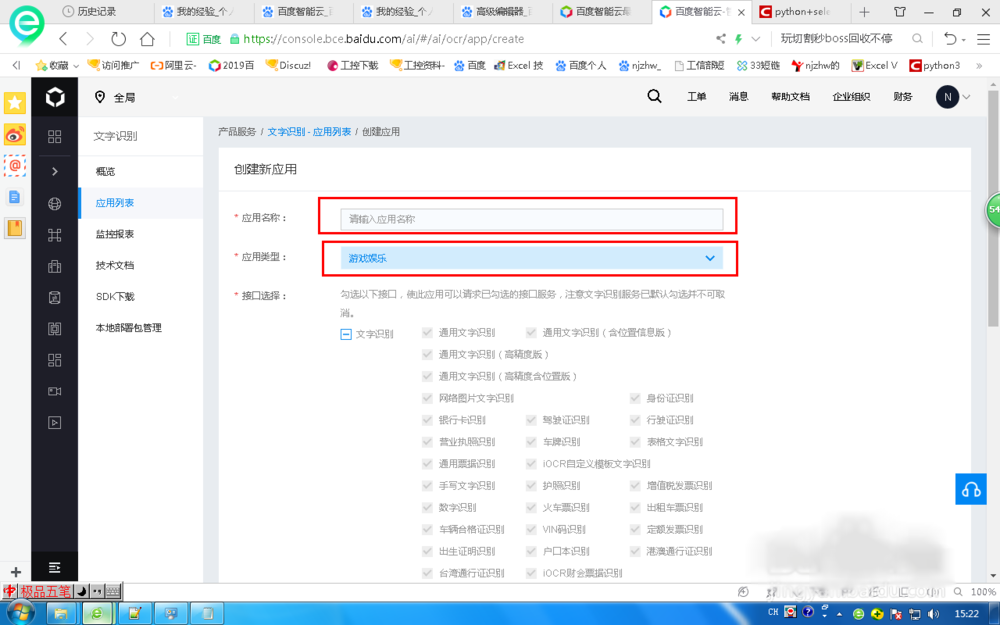
点击创建应用。
如图下面有关于“文字识别”的各类信息,如通用文字识别每天可以名费使用50000次,文字识别高精度版本免费使用500次每天。对于一般应用应该还足够。
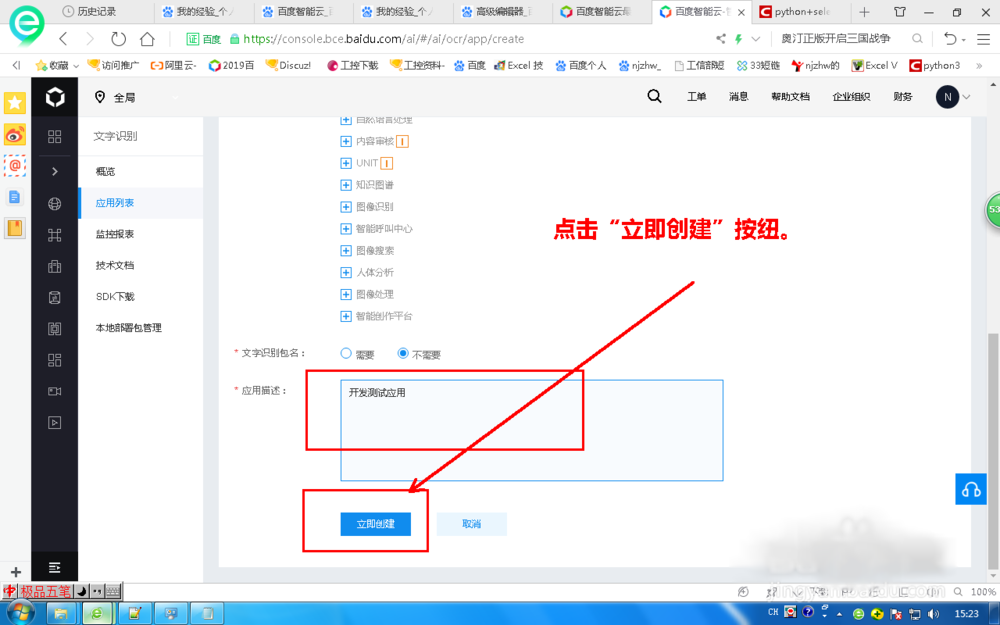
在创建应用界面填入必要的信息,点击“立即创建”按纽。返回后点击“管理应用”按纽。
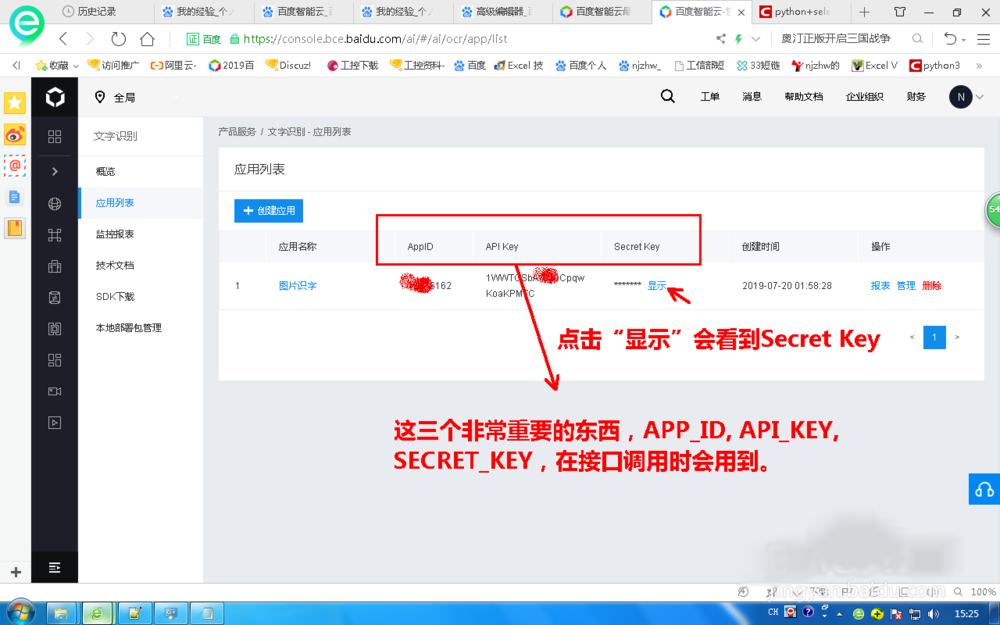
管理应用界面主要是能看到调用接口时需要的APP_ID, API_KEY, SECRET_KEY。
查看技术文档和SDK下载
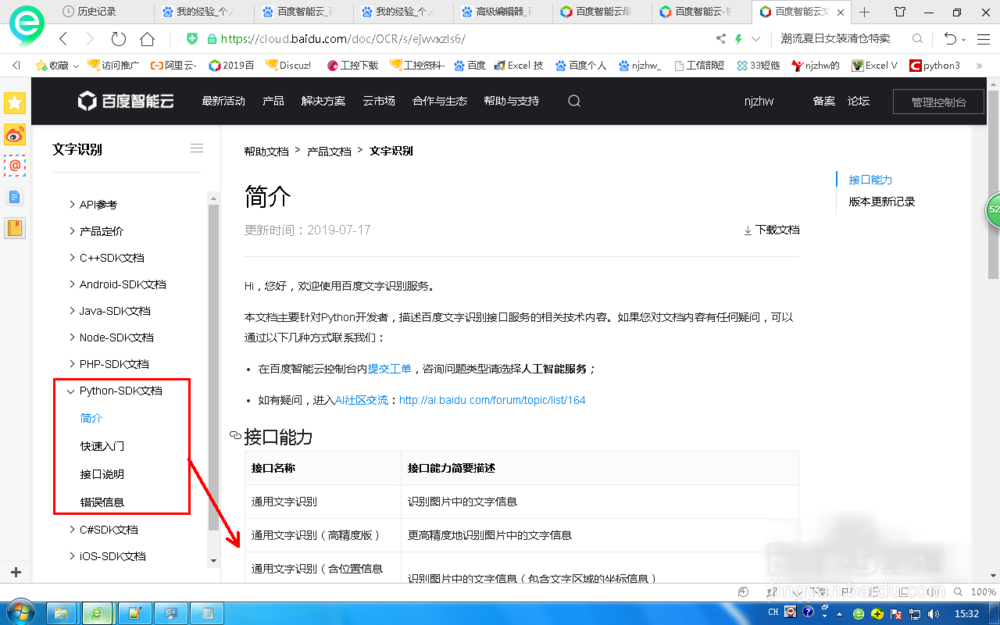
点击文字识别下的技术文档。

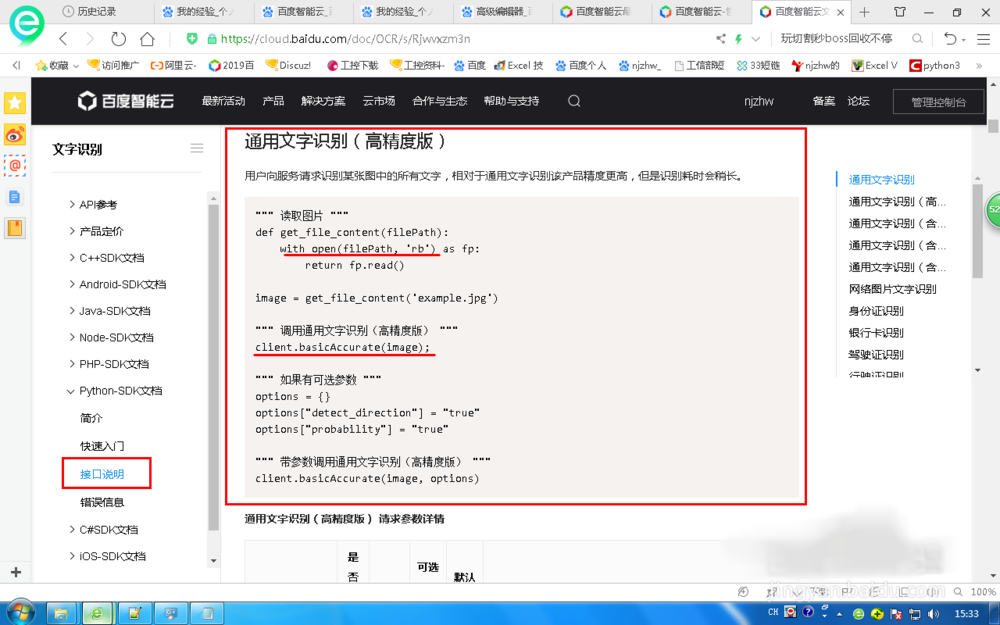
本例讲解python,所以选择python章节,查看快速入门,接品说明部分,主要关注python模块安装,AipOcr建立等等。
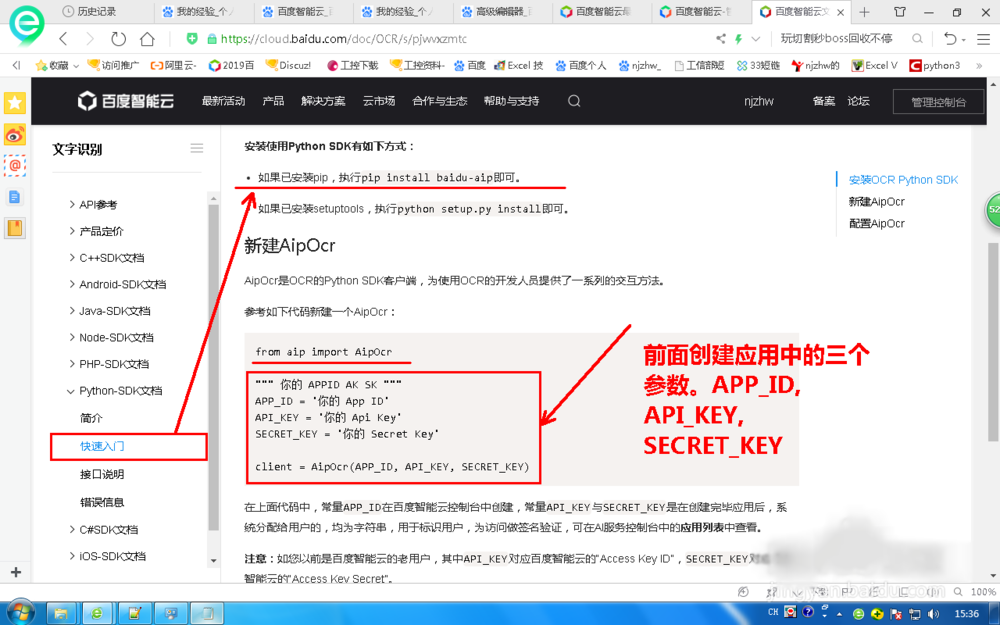
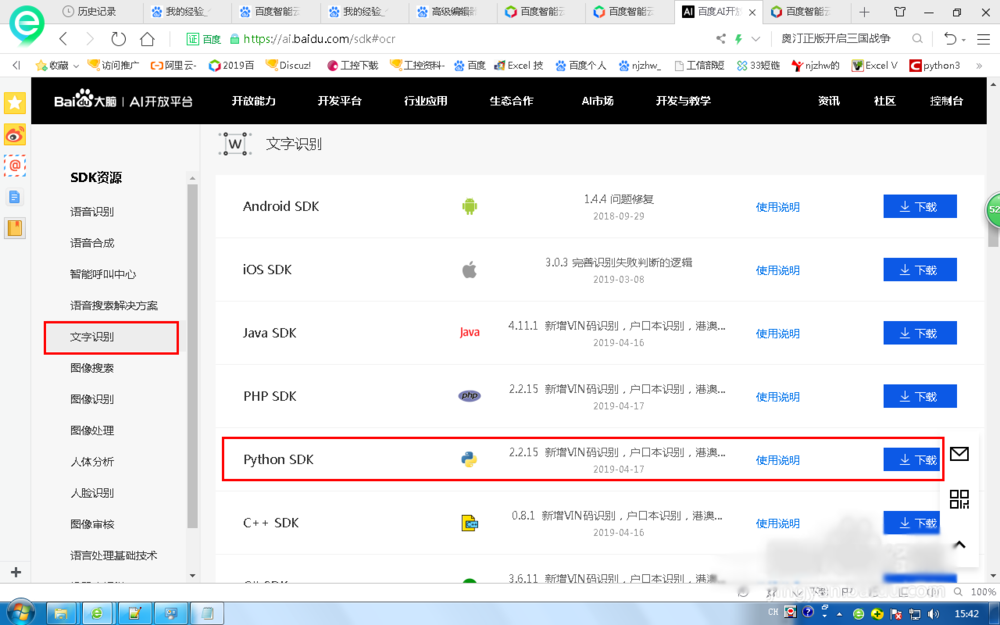
点击文字识别中SDK下载,关于python可以在python安装目录下输入
pip install baidu-aip指令进行安装。
实例
在python中导入api模块,初始化好百度智能云文字识别的应用,从电脑中读出一张图片,调用文字高精度识别方法进行识别,最后打印出来。
代码如下:
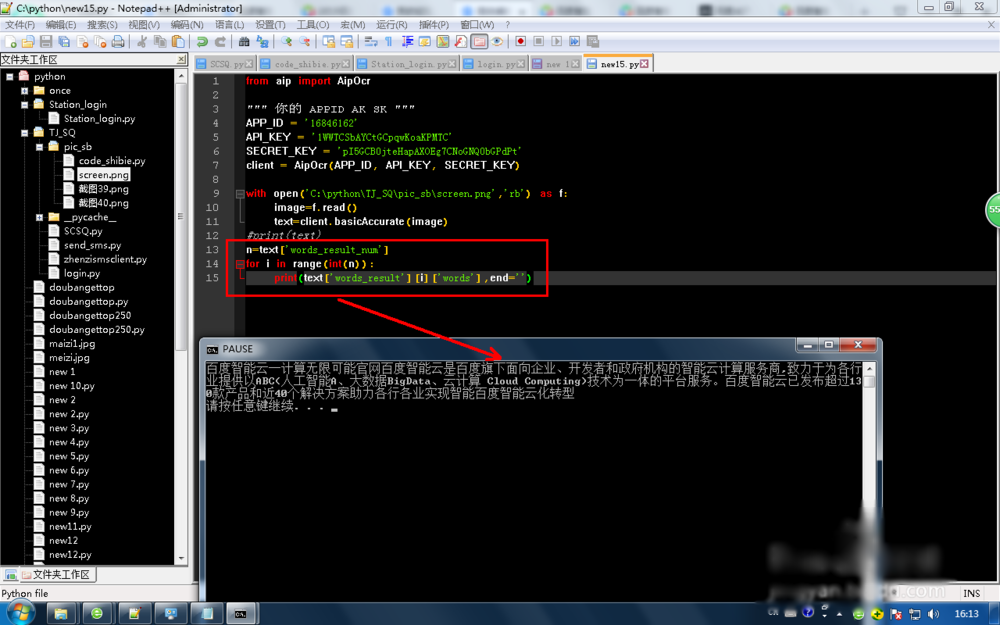
from aip import AipOcr
APP_ID = 'XXXXXXX'
API_KEY = 'XXXXXXX'
SECRET_KEY = 'XXXXXXXXXX'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
with open('C:\python\TJ_SQ\pic_sb\screen.png','rb') as f:
image=f.read()
text=client.basicAccurate(image)
print(text)
上面的APP_ID,API_KEY,SECRET_KEY要填你所创建的应用的信息。
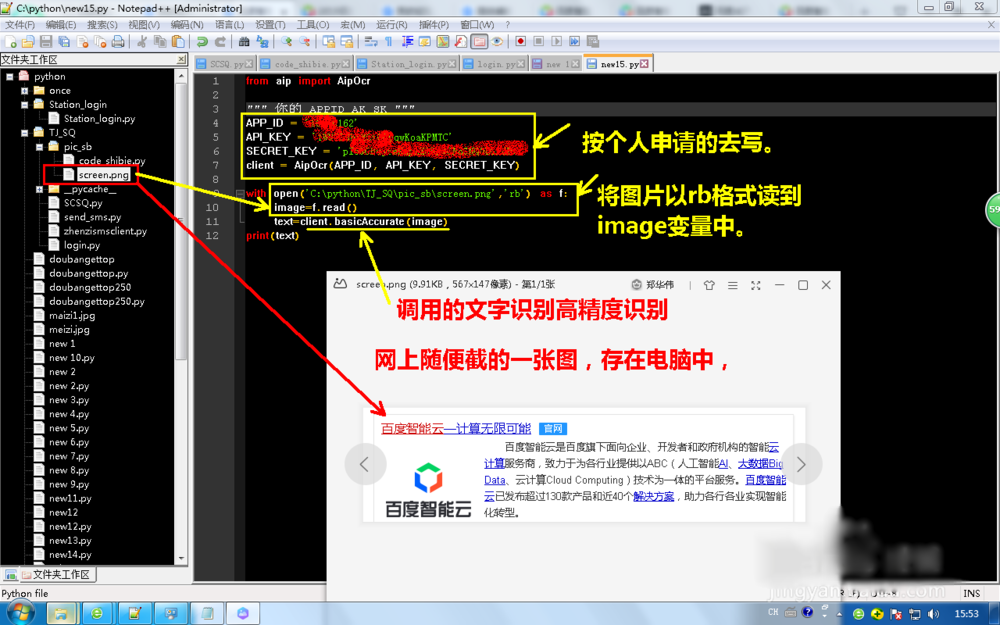
运行可以看出还是识别得非常好。输出为python字典数据,可以查字典打印。
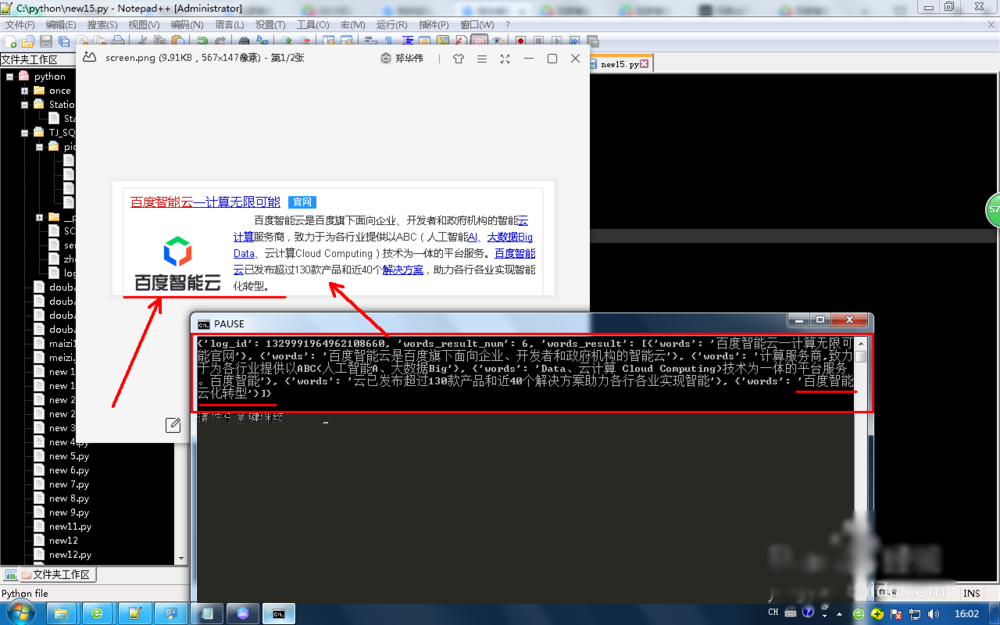
按字典方式进行打印结果,本方法只是一个初级使用,结合网上截屏再传入百度文字识别可以对网站登陆识别码进行自动识别。
以上就是本次介绍的全部内容,感谢大家的阅读和对【听图阁-专注于Python设计】的支持。