python实现爬山算法的思路详解
问题
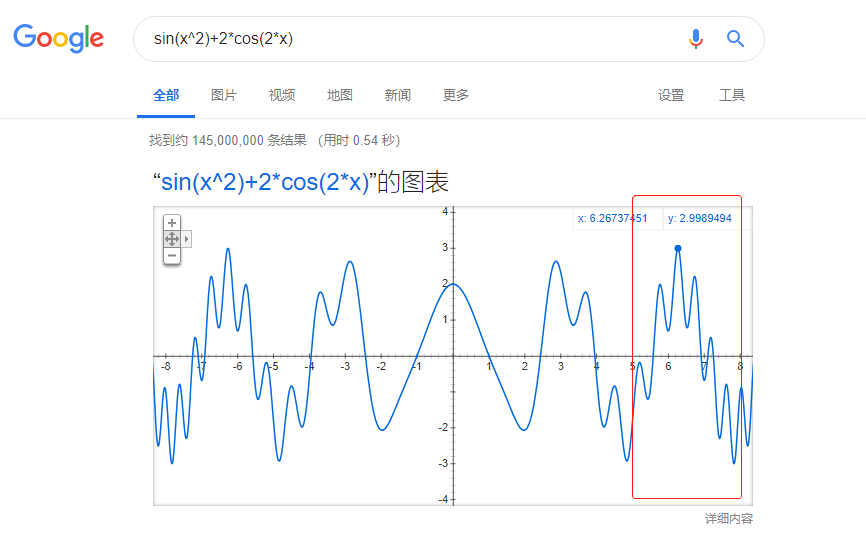
找图中函数在区间[5,8]的最大值
重点思路
爬山算法会收敛到局部最优,解决办法是初始值在定义域上随机取乱数100次,总不可能100次都那么倒霉。
实现
import numpy as np
import matplotlib.pyplot as plt
import math
# 搜索步长
DELTA = 0.01
# 定义域x从5到8闭区间
BOUND = [5,8]
# 随机取乱数100次
GENERATION = 100
def F(x):
return math.sin(x*x)+2.0*math.cos(2.0*x)
def hillClimbing(x):
while F(x+DELTA)>F(x) and x+DELTA<=BOUND[1] and x+DELTA>=BOUND[0]:
x = x+DELTA
while F(x-DELTA)>F(x) and x-DELTA<=BOUND[1] and x-DELTA>=BOUND[0]:
x = x-DELTA
return x,F(x)
def findMax():
highest = [0,-1000]
for i in range(GENERATION):
x = np.random.rand()*(BOUND[1]-BOUND[0])+BOUND[0]
currentValue = hillClimbing(x)
print('current value is :',currentValue)
if currentValue[1] > highest[1]:
highest[:] = currentValue
return highest
[x,y] = findMax()
print('highest point is x :{},y:{}'.format(x,y))
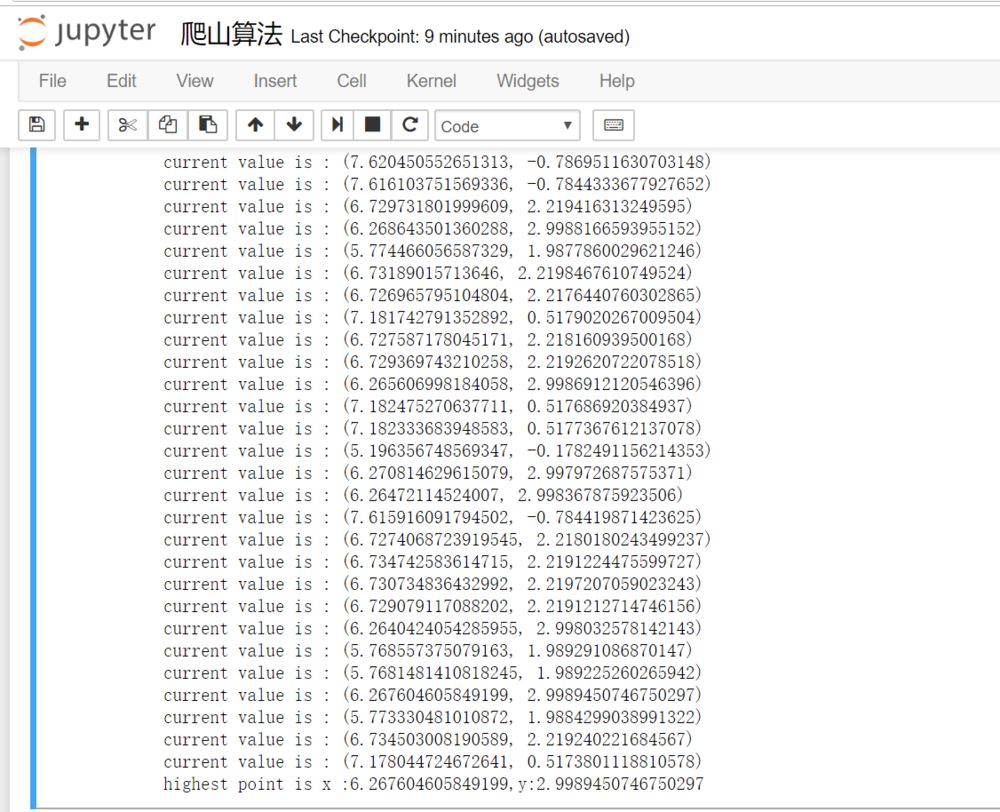
运行结果:
总结
以上所述是小编给大家介绍的python实现爬山算法的思路详解,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
