Python将json文件写入ES数据库的方法
1、安装Elasticsearch数据库
PS:在此之前需首先安装Java SE环境
下载elasticsearch-6.5.2版本,进入/elasticsearch-6.5.2/bin目录,双击执行elasticsearch.bat 打开浏览器输入http://localhost:9200 显示以下内容则说明安装成功

安装head插件,便于查看管理(还可以用kibana)
首先安装Nodejs(下载地址https://nodejs.org/en/)
再下载elasticsearch-head-master包解压到/elasticsearch-6.5.2/下(链接: https://pan.baidu.com/s/1q3kokFhpuJ2Q3otPgu7ldg
提取码: 1rpp
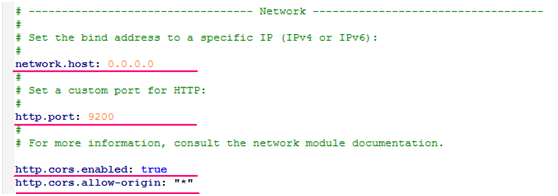
修改配置文件elasticsearch-6.5.2\config\elasticsearch.yml如下:
进入elasticsearch-head-master目录下执行npm install -g grunt-cli,再执行npm install安装依赖
在elasticsearch-head-master目录下找到Gruntfile.js文件修改服务器监听地址如下:

执行grunt server命令启动head服务
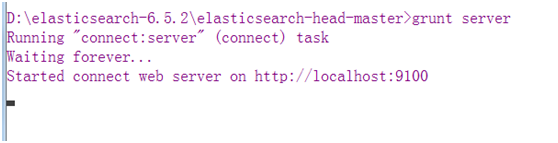
访问地址 http://localhost:9100/ 即可访问head管理页面
2、将json文件写入ES数据库(py脚本如下)
# -*- coding: UTF-8 -*-
from itertools import islice
import json , sys
from elasticsearch import Elasticsearch , helpers
import threading
_index = 'indextest' #修改为索引名
_type = 'string' #修改为类型名
es_url = 'http://192.168.116.1:9200/' #修改为elasticsearch服务器
reload(sys)
sys.setdefaultencoding('utf-8')
es = Elasticsearch(es_url)
es.indices.create(index=_index, ignore=400)
chunk_len = 10
num = 0
def bulk_es(chunk_data):
bulks=[]
try:
for i in xrange(chunk_len):
bulks.append({
"_index": _index,
"_type": _type,
"_source": chunk_data[i]
})
helpers.bulk(es, bulks)
except:
pass
with open(sys.argv[1]) as f:
while True:
lines = list(islice(f, chunk_len))
num =num +chunk_len
sys.stdout.write('\r' + 'num:'+'%d' % num)
sys.stdout.flush()
bulk_es(lines)
if not lines:
print "\n"
print "task has finished"
break
总结
以上所述是小编给大家介绍的Python将json文件写入ES数据库的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!