零基础使用Python读写处理Excel表格的方法
引
由于需要解决大批量Excel处理的事情,与其手工操作还不如写个简单的代码来处理,大致选了一下感觉还是Python最容易操作。
安装库Python环境
首先当然是配环境,不过选Python的一个重要原因就是Mac内是自带Python环境的,不需要额外的配置环境,省下了一笔工作,如果你用的是Windows系统,那就还需要配置一下Python的环境了,我Mac的Python版本是2.7。
第三方库
Python自己是不支持直接操作Excel的,但是Python强大之处就在于有大量好用的第三方库,这里我们选用读Excel的xlrd库和写Excel的xlwt库来操作。
关于第三方库的安装很简单,首先,去专门下载Python库的网站下载两个库的源码:
* 下载xlrd
* 下载xlwt
注意对于新手来说最简单的安装方式就是源码安装,不需要去折腾第三方库的管理器,直接点击这个先下载两个库的源码:


你看他后面也描述了类型是源码嘛。
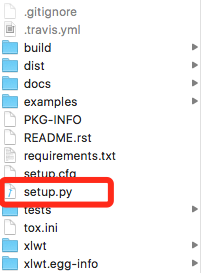
下载好之后在mac中解压,得到文件夹,可以看到里面都是有一个 setup.py 文件的:
这里当然不是直接双击安装了,py类型表示它是一个Python代码文件,双击只会打开文件看代码。我们要使用终端,输入命令号进入当前所在的文件夹,比如我把文件放在了“下载”中,那么做法是:
$ cd Downloads/
$ cd xlwt-1.1.2
$ sudo python setup.py install
这里 cd 的意思是进入该文件夹,sudo 的意思是使用管理员权限安装,不使用的话会告诉你没有权限的,回车后会要你输入电脑密码,输入后回车即可,python 是执行 python代码文件的命令,install 就是安装了。
然后会看到刷刷刷一堆文字过去,最后告诉你 finished 了,就是安装完成了。
xlrd 也是同样的安装方式。
写代码
读写Excel的第三方库都安装好了,就可以开始写代码了。
我们在一个文件夹下创建一个 hello.py 文件,然后用sublime之类的文档编辑器打开它,开始编写代码。(PS:Python中 # 号开头表示注释)
读Excel
# -*- coding: utf-8 -*-
import xdrlib ,sys
import xlrd
#打开excel文件
def open_excel(file= 'test.xlsx'):
try:
data = xlrd.open_workbook(file)
return data
except Exception,e:
print str(e)
#根据名称获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的索引 ,by_name:Sheet1名称
def excel_table_byname(file= 'test.xlsx', colnameindex=0, by_name=u'Sheet1'):
data = open_excel(file) #打开excel文件
table = data.sheet_by_name(by_name) #根据sheet名字来获取excel中的sheet
nrows = table.nrows #行数
colnames = table.row_values(colnameindex) #某一行数据
list =[] #装读取结果的序列
for rownum in range(0, nrows): #遍历每一行的内容
row = table.row_values(rownum) #根据行号获取行
if row: #如果行存在
app = [] #一行的内容
for i in range(len(colnames)): #一列列地读取行的内容
app.append(row[i])
list.append(app) #装载数据
return list
#主函数
def main():
tables = excel_table_byname()
for row in tables:
print row
if __name__=="__main__":
main()
这个代码很多我都注释了,只讲几个要注意的地方,首先最开始我们设置了utp8编码,然后一定要记得导入xlrd包,这样才能使用它的函数去读取excel。里面的 main() 是主函数,python 会运行这个函数,这个函数调用了其余的函数来读取数据。这个代码实现的是将excel文件 test.xlsx 中的 Sheet1 表中的数据一行行读取出来并打印。
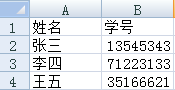
Excel中内容如下:

有两行内容。
要运行这个代码,需要用终端使用命令行,首先 cd 进入到代码所在的文件夹,代码和Excel文件都要放在这个文件夹里。然后使用 python hello.py 命令来运行这个代码文件:

以上就是 Python 读取并打印出来的内容,u 表示使用的是unicode编码,可以看到与Excel中是一致的。
创建Excel
使用xlwt库我们可以创建一个Excel:
# -*- coding: utf-8 -*-
import xlwt
def testXlwt(file = 'new.xls'):
book = xlwt.Workbook() #创建一个Excel
sheet1 = book.add_sheet('hello') #在其中创建一个名为hello的sheet
sheet1.write(0,0,'cloudox') #往sheet里第一行第一列写一个数据
sheet1.write(1,0,'ox') #往sheet里第二行第一列写一个数据
book.save(file) #创建保存文件
#主函数
def main():
testXlwt()
if __name__=="__main__":
main()
这个代码更简单,同样记得要在开头导入库。
代码中我们创建了一个excel,在其中添加一个sheet,写入两个数据,最后按照我们的命名保存了文件。
按照上面同样的方法运行代码后,终端中不会有打印的内容,但是我们去文件夹中看会得到一个名为 new.xls 的新excel文件,打开可以看到:

按照我们的方法写了数据,同时sheet名字也是hello。
值得注意的是,在xlwt库的说明中有这么一句话:
Library to create spreadsheet files compatible with MS Excel 97/2000/XP/2003 XLS files, on any platform, with Python 2.6, 2.6, 3.3+
也就是说,它只能创建 xls 的文件格式,不能创建现在的 xlsx 格式,其实有点老了,如果你把文件名写了 xlsx 格式,将会无法打开。
处理Excel内容
其实单独的读和写只是基本功,我们最终是想要处理Excel中的内容的。
这里我们假设一个使用场景,我们希望将Excel中所有第一列和第二列相同的行数据筛选出来保存到一个新的Excel中去。
那么我们的流程是:
打开目标Excel读取内容读取每一行的同时筛选第一列和第二列相等的行保留下来创建一个新Excel将筛选出来的内容写进去保存新Excel
那么我们看代码:
# -*- coding: utf-8 -*-
import xdrlib ,sys
import xlrd
import xlwt
#打开excel文件
def open_excel(file= 'test.xlsx'):
try:
data = xlrd.open_workbook(file)
return data
except Exception,e:
print str(e)
#根据索引获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的索引 ,by_index:表的索引
def excel_table_byindex(file= 'test.xlsx',colnameindex=0,by_index=0):
data = open_excel(file) #打开excel文件
table = data.sheets()[by_index] #根据sheet序号来获取excel中的sheet
nrows = table.nrows #行数
ncols = table.ncols #列数
colnames = table.row_values(colnameindex) #某一行数据
list =[] #装读取结果的序列
for rownum in range(0,nrows): #遍历每一行的内容
row = table.row_values(rownum) #根据行号获取行
if row: #如果行存在
app = [] #一行的内容
for i in range(len(colnames)): #一列列地读取行的内容
app.append(row[i])
if app[0] == app[1] : #如果这一行的第一个和第二个数据相同才将其装载到最终的list中
list.append(app)
testXlwt('new.xls', list) #调用写函数,讲list内容写到一个新文件中
return list
#将list中的内容写入一个新的file文件
def testXlwt(file = 'new.xls', list = []):
book = xlwt.Workbook() #创建一个Excel
sheet1 = book.add_sheet('hello') #在其中创建一个名为hello的sheet
i = 0 #行序号
for app in list : #遍历list每一行
j = 0 #列序号
for x in app : #遍历该行中的每个内容(也就是每一列的)
sheet1.write(i, j, x) #在新sheet中的第i行第j列写入读取到的x值
j = j+1 #列号递增
i = i+1 #行号递增
# sheet1.write(0,0,'cloudox') #往sheet里第一行第一列写一个数据
# sheet1.write(1,0,'ox') #往sheet里第二行第一列写一个数据
book.save(file) #创建保存文件
#主函数
def main():
tables = excel_table_byindex()
for row in tables:
print row
if __name__=="__main__":
main()
这次我们开头要导入xlrd和xlwt两个库,因为既要读也要写。
代码内容基本与上面两个差不多,有一点点加深,在读取的时候我们判断了第一列和第二列数据相同的行才加到list中去。在写的时候我们用了两个for循环来对新excel中的一个个单元格写数据,使用了i和j两个变量来记录位置。此外在获取sheet的时候,与上面的不同,这里是通过sheet的序号(这里是0)来获取的,上面的是通过sheet名称来获取。
我们要处理的Excel中的内容是这样的:
按道理我们筛选后只应该保留第一行的内容,运行完后我们得到了一个新的Excel文件,里面的内容如下:

可以看到和预期是相符的。
结
这里只是简单的例子,两个库的操作还有很多,能够进行的处理也有很多,如果要处理大量数据,可能还要考虑内存,分批次来处理,总之,本文只是一个入门,尽量追求零基础也能学着使用来解放劳动力,更多的用法,就看自己琢磨了。
可以下载我的示例工程:https://github.com/Cloudox/PYReadWriteExcelDemo
以上所述是小编给大家介绍的Python读写处理Excel表格详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!