详解Python 爬取13个旅游城市,告诉你五一大家最爱去哪玩?
今年五一放了四天假,很多人不再只是选择周边游,因为时间充裕,选择了稍微远一点的景区,甚至出国游。各个景点成了人山人海,拥挤的人群,甚至去卫生间都要排队半天,那一刻我突然有点理解灭霸的行为了。
今天通过分析去哪儿网部分城市门票售卖情况,简单的分析一下哪些景点比较受欢迎,等下次假期可以做个参考。
抓取数据
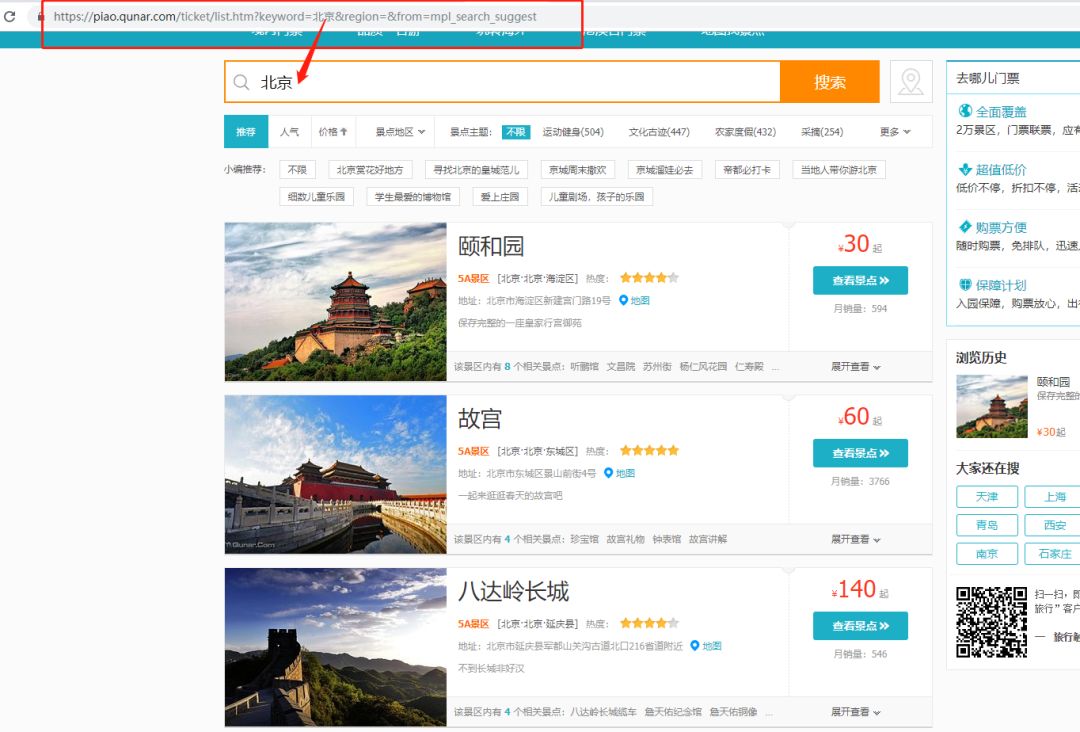
通过请求https://piao.qunar.com/ticket/list.htm?keyword=北京,获取北京地区热门景区信息,再通过BeautifulSoup去分析提取出我们需要的信息。
这里爬取了前4页的景点信息,每页有15个景点。因为去哪儿并没有什么反爬措施,所以直接请求就可以了。
这里随机选择了13个热门城市:北京、上海、成都、三亚、广州、重庆、深圳、西安、杭州、厦门、武汉、大连、苏州。
并将爬取的数据存到了MongoDB数据库 。
爬虫部分完整代码如下:
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
class QuNaEr():
def __init__(self, keyword, page=1):
self.keyword = keyword
self.page = page
def qne_spider(self):
url = 'https://piao.qunar.com/ticket/list.htm?keyword=%s®ion=&from=mpl_search_suggest&page=%s' % (self.keyword, self.page)
response = requests.get(url)
response.encoding = 'utf-8'
text = response.text
bs_obj = BeautifulSoup(text, 'html.parser')
arr = bs_obj.find('div', {'class': 'result_list'}).contents
for i in arr:
info = i.attrs
# 景区名称
name = info.get('data-sight-name')
# 地址
address = info.get('data-address')
# 近期售票数
count = info.get('data-sale-count')
# 经纬度
point = info.get('data-point')
# 起始价格
price = i.find('span', {'class': 'sight_item_price'})
price = price.find_all('em')
price = price[0].text
conn = MongoClient('localhost', port=27017)
db = conn.QuNaEr # 库
table = db.qunaer_51 # 表
table.insert_one({
'name' : name,
'address' : address,
'count' : int(count),
'point' : point,
'price' : float(price),
'city' : self.keyword
})
if __name__ == '__main__':
citys = ['北京', '上海', '成都', '三亚', '广州', '重庆', '深圳', '西安', '杭州', '厦门', '武汉', '大连', '苏州']
for i in citys:
for page in range(1, 5):
qne = QuNaEr(i, page=page)
qne.qne_spider()
效果图如下:
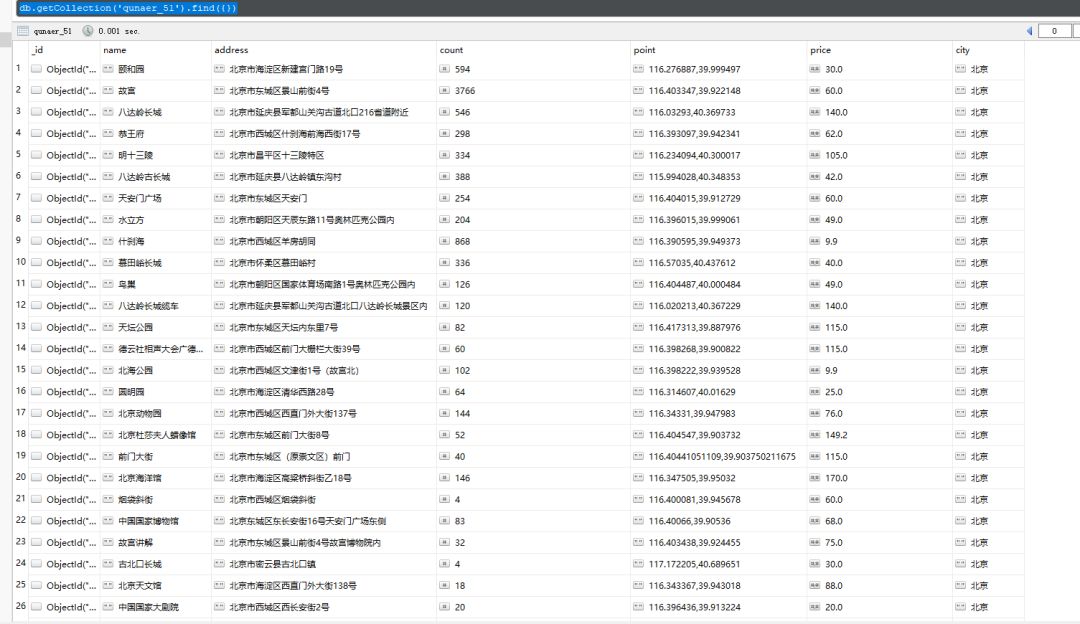
有了数据,我们就可以分析出自己想要的东西了。
分析数据
1、最受欢迎的15个景区
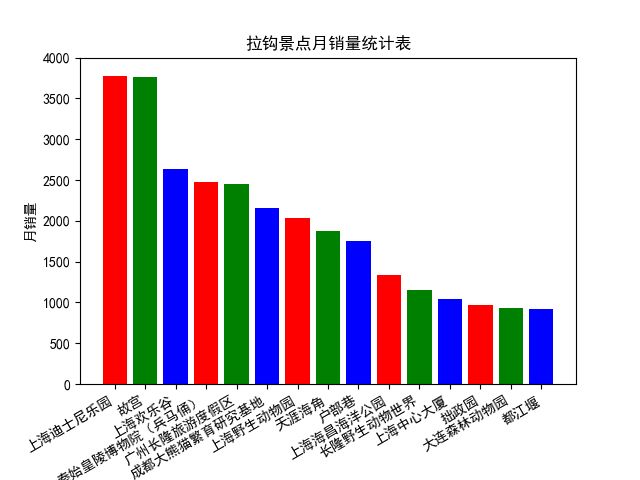
由图可以看出,在选择的13个城市中,最热门的景区为上海的迪士尼乐园。
代码如下:
from pymongo import MongoClient
# 设置字体,不然无法显示中文
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
conn = MongoClient('localhost', port=27017)
db = conn.QuNaEr # 库
table = db.qunaer_51 # 表
result = table.find().sort([('count', -1)]).limit(15)
# x,y轴数据
x_arr = [] # 景区名称
y_arr = [] # 销量
for i in result:
x_arr.append(i['name'])
y_arr.append(i['count'])
"""
去哪儿月销量排行榜
"""
plt.bar(x_arr, y_arr, color='rgb') # 指定color,不然所有的柱体都会是一个颜色
plt.gcf().autofmt_xdate() # 旋转x轴,避免重叠
plt.xlabel(u'景点名称') # x轴描述信息
plt.ylabel(u'月销量') # y轴描述信息
plt.title(u'拉钩景点月销量统计表') # 指定图表描述信息
plt.ylim(0, 4000) # 指定Y轴的高度
plt.savefig('去哪儿月销售量排行榜') # 保存为图片
plt.show()
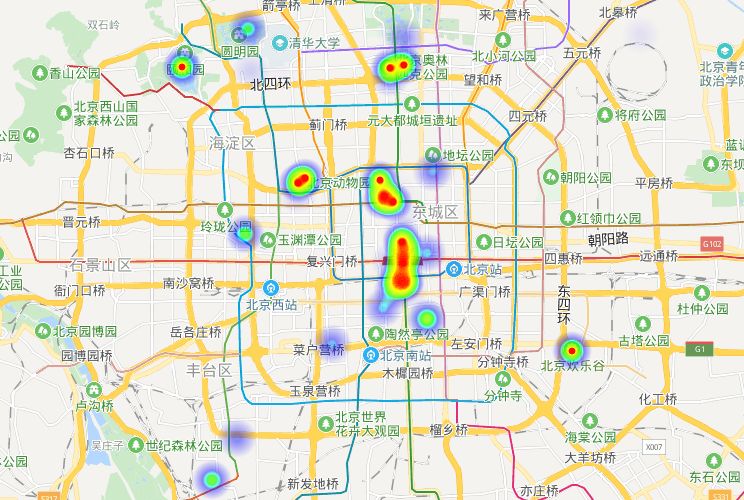
2、景区热力图
这里为了方便,只展示一下北京地区的景区热力图。用到了百度地图的开放平台。首先需要先注册开发者信息,首页底部有个申请秘钥的按钮,点击进行创建就可以了。我的应用类型选择的是浏览器端,因此只需要组装数据替换掉相应html代码即可。另外还需要将自己访问应用的AK替换掉。效果图如下:
3、景区价格
价格是出游第一个要考虑的,一开始想统计一下各城市的平均价格,但是后来发现效果不是很好,比如北京的刘老根大舞台价格在580元,这样拉高了平均价格。就好比姚明和潘长江的平均身高在190cm,并没有什么说服力。所以索性展示一下景区的价格分布。
根据价格设置了六个区间:
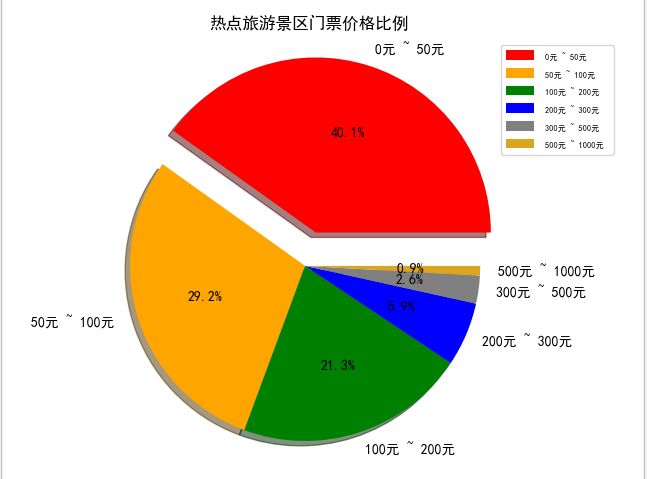
通过上图得知,大部分的景区门票价格都在200元以下。每次旅游花费基本都在交通、住宿、吃吃喝喝上了。门票占比还是比较少的。
实现代码如下:
arr = [[0, 50], [50,100], [100, 200], [200,300], [300,500], [500,1000]]
name_arr = []
total_arr = []
for i in arr:
result = table.count({'price': {'$gte': i[0], '$lt': i[1]}})
name = '%s元 ~ %s元 ' % (i[0], i[1])
name_arr.append(name)
total_arr.append(result)
color = 'red', 'orange', 'green', 'blue', 'gray', 'goldenrod' # 各类别颜色
explode = (0.2, 0, 0, 0, 0, 0) # 各类别的偏移半径
# 绘制饼状图
pie = plt.pie(total_arr, colors=color, explode=explode, labels=name_arr, shadow=True, autopct='%1.1f%%')
plt.axis('equal')
plt.title(u'热点旅游景区门票价格比例', fontsize=12)
plt.legend(loc=0, bbox_to_anchor=(0.82, 1)) # 图例
# 设置legend的字体大小
leg = plt.gca().get_legend()
ltext = leg.get_texts()
plt.setp(ltext, fontsize=6)
# 显示图
plt.show()
以上所述是小编给大家介绍的Python 爬取13个旅游城市详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!