python3.6根据m3u8下载mp4视频
需要下载某网站的视频,chrome浏览器按F12打开开发者模式,发现视频链接是以"blob:http"开头的链接,打开这个链接后找不到网页,网上查了下,找到了下载方法,在这里做个记录,如果有错误,欢迎指出。
程序在Windows 10下运行,不过Linux应该也没问题。
使用到的有re模块,requests模块和Crypto模块,其中requests模块和Crypto模块如果没安装可以使用pip命令安装。(Crypto模块安装感觉比较坑,我是从anaconda里拷贝了一份)
下面开始正题:
注:以下使用的m3u8文件所在的网站是自己搭建用来测试的,链接可能会失效。
首先在chrome的network里找到一个m3u8文件的请求,可以通过它下载视频。

通过Preview可以看到m3u8文件的内容。
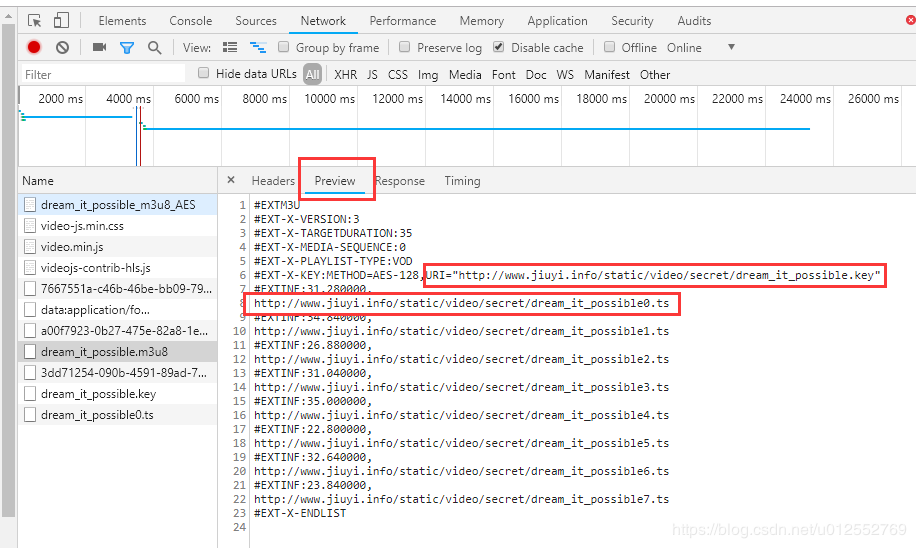
这里m3u8文件比较重要的内容有两个。
一个是URI后面的链接,这个是加密和解密的秘钥,如果m3u8文件里有这个URI,那么这个视频就是经过了加密的,加密的方法可以看URI前面,这里是AES-128加密算法。
另一个是以ts结尾链接,这个是视频片段,如果是没进行加密的,可以直接打开这个链接下载视频片段,下载下来的是后缀为ts的文件,一般可以直接播放,不过时间很短。如果是加密过的,下载后播放会提示视频文件已损坏。
知道这些后,就可以进行下载了,先获取m3u8文件的内容,然后解析出秘钥(key)和ts的链接,然后下载key对每一个ts进行解密,保存到一个mp4文件里。
下载用的是requests模块,解析key和ts的链接是用的re模块,解密用的是Crypto模块。
使用Crypto需要注意三个地方,一个是安装和导入,第二个是Crypto里AES.new的参数,第三个是decrypt方法的参数。下面先看代码。
导入模块:
import re import requests from Crypto.Cipher import AES
初始设置:
# 保存的mp4文件名
name = "dream_it_possible.mp4"
# m3u8文件的url
url = "http://www.jiuyi.info/static/video/secret/dream_it_possible.m3u8"
# 请求头,不一定需要,看网站更改
headers = {
"Referer": "http://www.jiuyi.info/video/dream_it_possible",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36",
}
获取m3u8文件内容,并解析出key和ts文件的url。
# 获取m3u8文件内容 r = requests.get(url) # 通过正值表达式获取key和ts的url k = re.compile(r"http://.*?\.key") # key的正则匹配 t = re.compile(r"http://.*?\.ts") # ts的正则匹配 key_url = k.findall(r.text)[0] # key的url ts_urls = t.findall(r.text) # ts的url列表
下载并解密ts文件,保存为mp4文件。
# 下载key
key = requests.get(key_url).content
# 解密并保存ts
for ts_url in ts_urls:
ts_name = ts_url.split("/")[-1] # ts文件名
# 解密,new有三个参数,
# 第一个是秘钥(key)的二进制数据,
# 第二个使用下面这个就好
# 第三个IV在m3u8文件里URI后面会给出,如果没有,可以尝试把秘钥(key)赋值给IV
sprytor = AES.new(key, AES.MODE_CBC, IV=key)
# 获取ts文件二进制数据
ts = requests.get(ts_url).content
# 密文长度不为16的倍数,则添加二进制"0"直到长度为16的倍数
while len(ts) % 16 != 0:
ts += b"0"
# 写入mp4文件
with open(name, "ab") as file:
# decrypt方法的参数需要为16的倍数,如果不是,需要在后面补二进制"0"
file.write(sprytor.decrypt(ts))
print(name, "下载完成")
到这里就下载完成了。
完整代码:
import re
import requests
from Crypto.Cipher import AES
# 保存的mp4文件名
name = "dream_it_possible.mp4"
# m3u8文件的url
url = "http://www.jiuyi.info/static/video/secret/dream_it_possible.m3u8"
# 请求头,不一定需要,看网站更改
headers = {
"Referer": "http://www.jiuyi.info/video/dream_it_possible",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36",
}
print("正在解析:" + url.split("/")[-1])
# 获取m3u8文件内容
r = requests.get(url)
# 通过正值表达式获取key和ts的链接
k = re.compile(r"http://.*?\.key") # key的正则匹配
t = re.compile(r"http://.*?\.ts") # ts的正则匹配
key_url = k.findall(r.text)[0] # key的url
ts_urls = t.findall(r.text) # ts的url列表
# 下载key的二进制数据
print("正在下载key")
key = requests.get(key_url).content
# 解密并保存ts
for ts_url in ts_urls:
ts_name = ts_url.split("/")[-1] # ts文件名
# 解密,new有三个参数,
# 第一个是秘钥(key)的二进制数据,
# 第二个使用下面这个就好
# 第三个IV在m3u8文件里URI后面会给出,如果没有,可以尝试把秘钥(key)赋值给IV
sprytor = AES.new(key, AES.MODE_CBC, IV=key)
# 获取ts文件二进制数据
print("正在下载:" + ts_name)
ts = requests.get(ts_url).content
# 密文长度不为16的倍数,则添加b"0"直到长度为16的倍数
while len(ts) % 16 != 0:
ts += b"0"
print("正在解密:" + ts_name)
# 写入mp4文件
with open(name, "ab") as file:
# # decrypt方法的参数需要为16的倍数,如果不是,需要在后面补二进制"0"
file.write(sprytor.decrypt(ts))
print("保存成功:" + ts_name)
print(name, "下载完成")
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。