Pandas库之DataFrame使用的学习笔记
1 简介
DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。
或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matlab也可以用cell存放多类型数据),DataFrame的单元格可以存放数值、字符串等,这和excel表很像。
同时DataFrame可以设置列名columns与行名index,可以通过像matlab一样通过位置获取数据也可以通过列名和行名定位,具体方法在后面细说。
2 创建DataFrame
首先声明一下,以下都是使用的Python 3.6.5版本为例,Python2应该也差不多吧(大概
在所有操作之前当然要先import必要的pandas库,因为pandas常与numpy一起配合使用,所以也一起import吧。
import pandas as pd import numpy as np
如果还没安装直接在cmd里pip安装吧,如果有版本选择问题,参看之前的帖子。
pip install pandas pip install numpy
2.1 直接创建
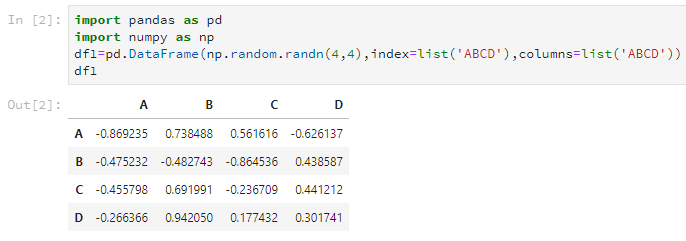
可以直接使用pandas的DataFrame函数创建,比如接下来我们随机创建一个4*4的DataFrame。
df1=pd.DataFrame(np.random.randn(4,4),index=list('ABCD'),columns=list('ABCD'))
其中第一个参数是存放在DataFrame里的数据,第二个参数index就是之前说的行名(或者应该叫索引?),第三个参数columns是之前说的列名。
后两个参数可以使用list输入,但是注意,这个list的长度要和DataFrame的大小匹配,不然会报错。当然,这两个参数是可选的,你可以选择不设置。
而且发现,这两个list是可以一样的,但是每行每列的名字在index或columns里要是唯一的。
使用python自己的shell展示创建的结果是这样的:

或者在jupyter里面更酷点的样子,接下来都使用jupyter输出展示吧。
当然,如果你的数据量贼小,也可以自己输入创建,类似这样。
df2=pd.DataFrame([[1,2,3,4],[2,3,4,5],
[3,4,5,6],[4,5,6,7]],
index=list('ABCD'),columns=list('ABCD'))
这样也可以得到这样子的DataFrame:

2.2 使用字典创建
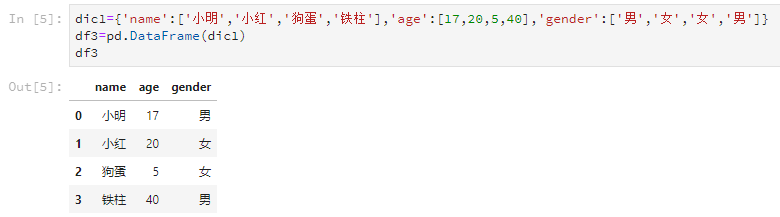
仍然是使用DataFrame这个函数,但是字典的每个key的value代表一列,而key是这一列的列名。比如这样。
dic1={'name':['小明','小红','狗蛋','铁柱'],'age':[17,20,5,40],'gender':['男','女','女','男']}
df3=pd.DataFrame(dic1)
输出结果是这样的
3 查看与筛选数据
python没有matlab的工作区直接查看变量与内容,这大概是python科学计算的一个缺点。所以需要格外的代码来查看,最基本的直接写变量名与print就不说了。
3.1 查看列的数据类型
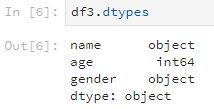
使用dtypes方法可以查看各列的数据类型,比如说刚刚的df3。
df3.dtypes
输出的结果是这样:
3.2 查看DataFrame的头尾
使用head可以查看前几行的数据,默认的是前5行,不过也可以自己设置。
使用tail可以查看后几行的数据,默认也是5行,参数可以自己设置。
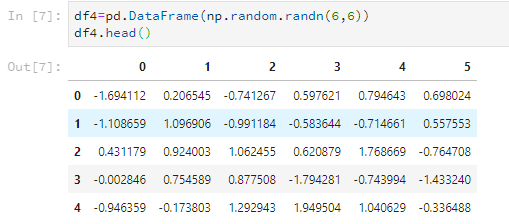
比如随意设置一个6*6的数据,只看前5行。
df4=pd.DataFrame(np.random.randn(6,6)) df4.head()
比如只看前3行。
df4.head(3)

比如看后5行。
df4.tail()
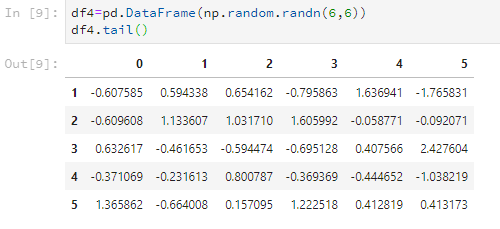
比如只看后2行。
df4.tail(2)
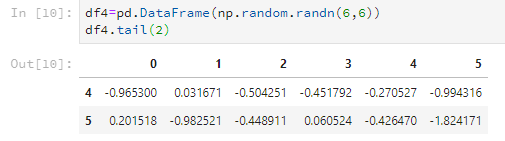
3.3 查看行名与列名
使用index查看行名,columns查看列名。具体由例子感受吧。
查看行名。
df1.index

查看列名。
df3.columns

3.4 查看数据值
使用values可以查看DataFrame里的数据值,返回的是一个数组。
比如说查看所有的数据值。
df3.values
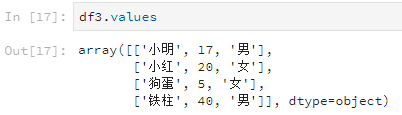
比如说查看某一列所有的数据值。
df3['name'].values

还有另一种操作,使用loc或者iloc查看数据值(但是好像只能根据行来查看?)。区别是loc是根据行名,iloc是根据数字索引(也就是行号)。
比如说这样。
df1.loc['A']
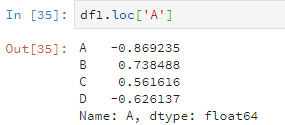
或者这样。
df1.iloc[0]

按列进行索引查看数据还能直接使用列名,但这种方法对行索引不适用。
df3['name']
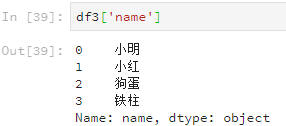
3.5 查看行列数
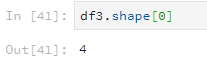
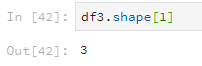
使用shape查看行列数,参数为0表示查看行数,参数为1表示查看列数。
df3.shape[0]
df3.shape[1]
4 基本操作
DataFrame有些方法可以直接进行数据统计,矩阵计算之类的基本操作。
4.1 转置
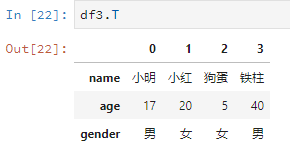
直接字母T,线性代数上线。
比如说把之前的df2转置一下。
df3.T
4.2 描述性统计
使用describe可以对数据根据列进行描述性统计。
比如说对df1进行描述性统计。
df1.describe()
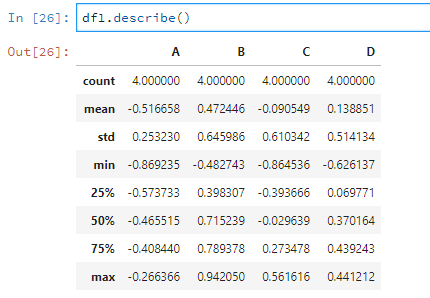
如果有的列是非数值型的,那么就不会进行统计。
如果想对行进行描述性统计,请参看4.1(转置后进行describe呀!)
4.3 计算
使用sum默认对每列求和,sum(1)为对每行求和。比如
df3.sum()
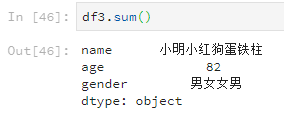
可以发现就算元素是字符串,使用sum也会加起来。
df3.sum(1)
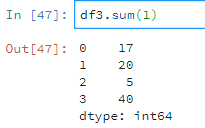
而一行中,有字符串有数值则只计算数值。
数乘运算使用apply,比如。
df2.apply(lambda x:x*2)

如果元素是字符串,则会把字符串再重复一遍。
乘方运算跟matlab类似,直接使用两个*,比如。
df2**2
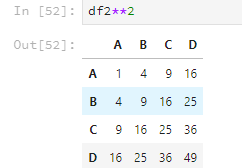
乘方运算如果有元素是字符串的话,就会报错。
4.4 新增
扩充列可以直接像字典一样,列名对应一个list,但是注意list的长度要跟index的长度一致。
df2['E']=['999','999','999','999']df2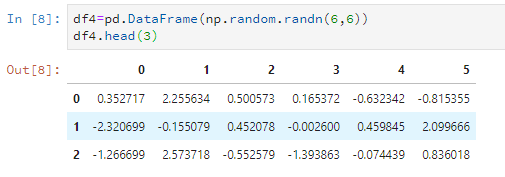
还可以使用insert,使用这个方法可以指定把列插入到第几列,其他的列顺延。
df2['E']=['999','999','999','999'] df2
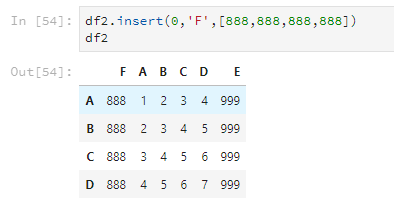
4.5 合并
使用join可以将两个DataFrame合并,但只根据行列名合并,并且以作用的那个DataFrame的为基准。如下所示,新的df7是以df2的行号index为基准的。
df6=pd.DataFrame(['my','name','is','a'],index=list('ACDH'),columns=list('G'))
df6
df7=df2.join(df6)
df7
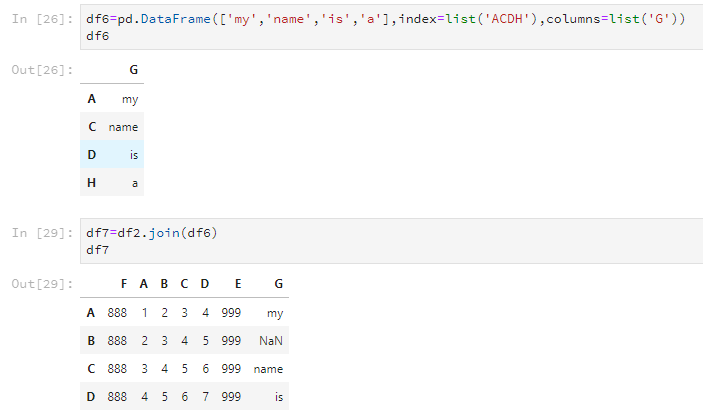
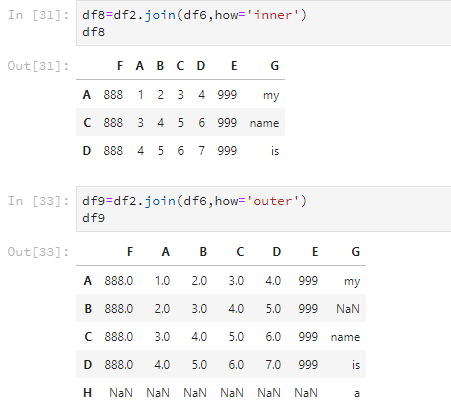
但是,join这个方法还有how这个参数可以设置,合并两个DataFrame的交集或并集。参数为'inner'表示交集,'outer'表示并集。
df6=pd.DataFrame(['my','name','is','a'],index=list('ACDH'),columns=list('G'))
df6
df7=df2.join(df6)
df7
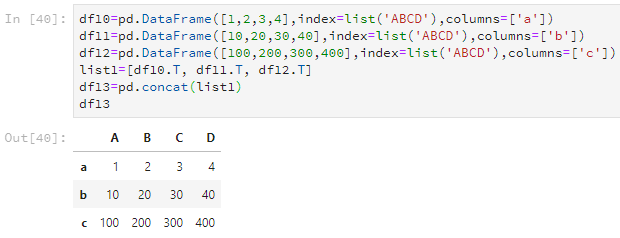
如果要合并多个Dataframe,可以用list把几个Dataframe装起来,然后使用concat转化为一个新的Dataframe。
df6=pd.DataFrame(['my','name','is','a'],index=list('ACDH'),columns=list('G'))
df6
df7=df2.join(df6)
df7
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。