python版百度语音识别功能
本文实例为大家分享了python版百度语音识别功能的具体代码,供大家参考,具体内容如下
环境:使用的IDE是Pycharm
1.新建工程
2.配置百度语音识别环境
“File”——“Settings”打开设置面板,“Project”标签下添加Project Interpreter,点击右侧“+”
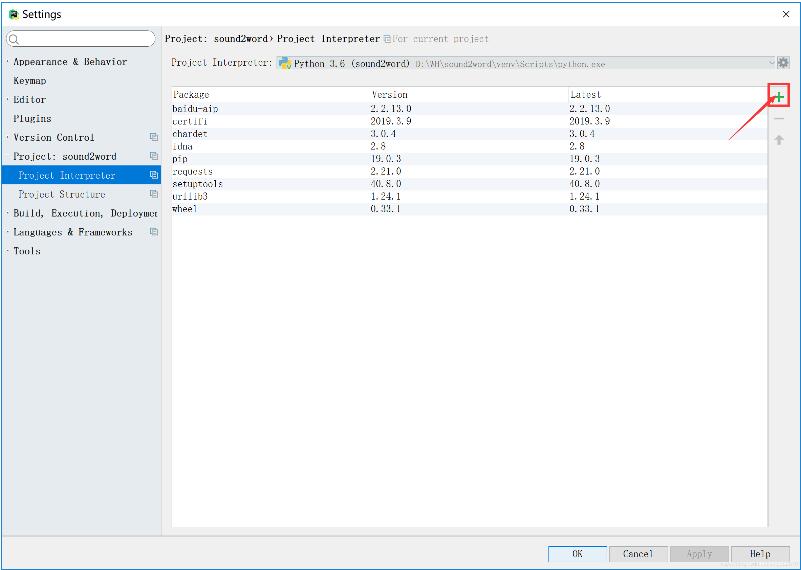
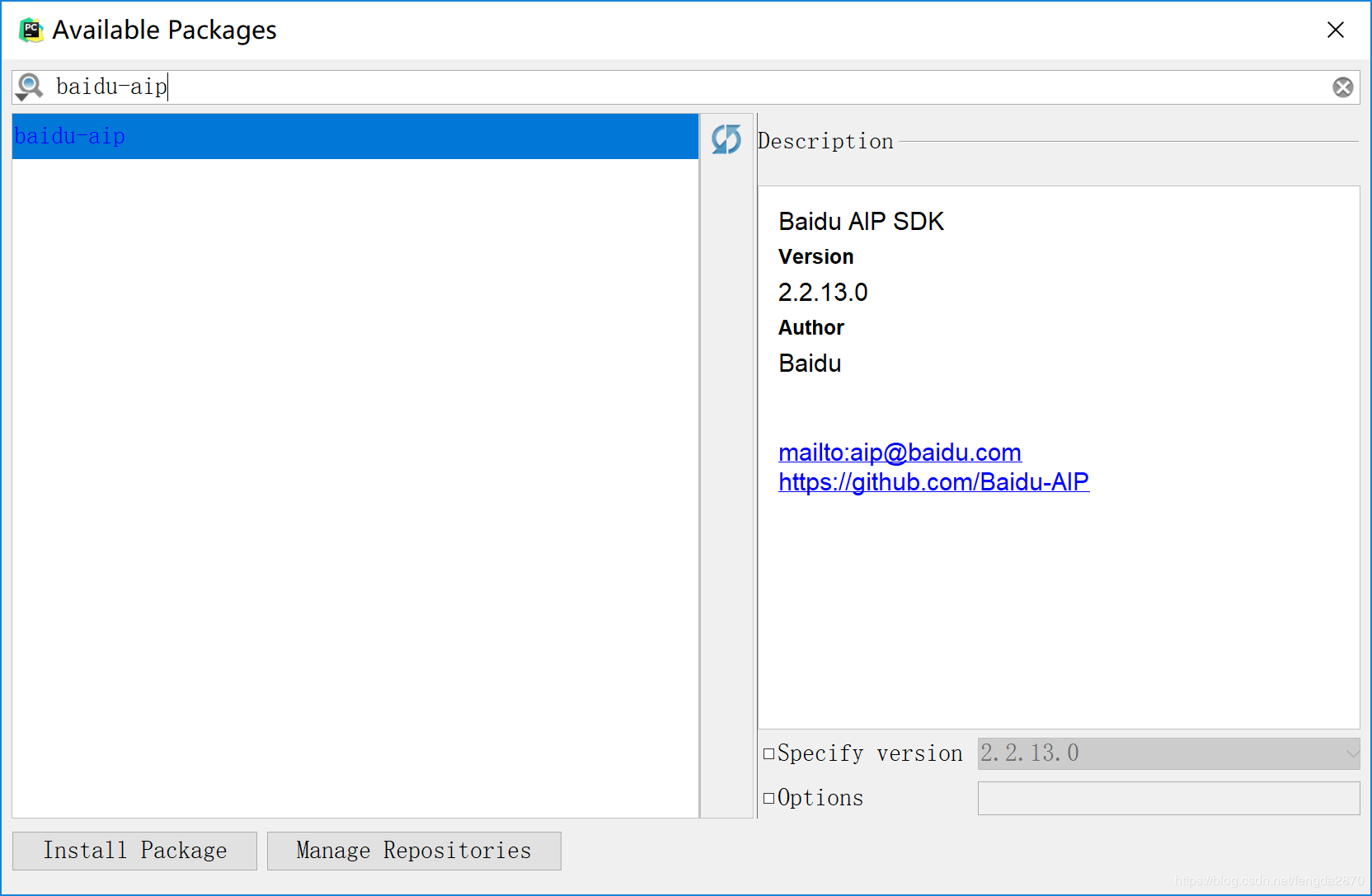
输入“baidu-aip”,进行安装
新建测试文件
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '******'
API_KEY = '******'
SECRET_KEY = '******'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别本地文件
test1 = client.asr(get_file_content('test.pcm'), 'pcm', 16000, {'dev_pid': 1536,})
print(test1)
注意:提交的音频文件格式推荐是PCM,采样率16K,16位,单声道。
转换的文字准确率还是可以的,但是没有标点符号,这一点比较不满意:
{'corpus_no': '6670746770877419029', 'err_msg': 'success.', 'err_no': 0, 'result': ['这里是语音转换的结果看不到标点符号'], 'sn': '29336209551553154264'}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
