用python给自己做一款小说阅读器过程详解
前言
前一段时间书荒的时候,在喜马拉雅APP发现一个主播播讲的小说-大王饶命。听起来感觉很好笑,挺有意思的,但是只有前200张是免费的,后面就要收费。一章两毛钱,本来是想要买一下,发现说的进度比较慢而且整本书要1300多张,算了一下,需要200大洋才行,而且等他说完,还不知道要到什么时候去。
所以就找文字版的来读,文字版又有它的缺点,你必须手眼联动才行。如果要忙别的事情,但是又抑制不住想看的冲动,就很纠结了。在网上找了一圈,没有其他的音频。而且以前用的那些有阅读功能的软件,比如微信阅读、追书神器也都开始收费了。
那怎么办呢?这能难倒一个学Python的程序员吗?必须滴、坚决滴不能。我用的可是世界上最好的编程语言-Python,很多伙伴也学了不少Python编程学习教程,不妨这里一起操练一下?

自己动手丰衣足食,接下来就用我们学过的Python编程学习教程实现自己的小说阅读器吧。
语音合成选择
要想读文字,就必须要用到语音合成。现在这种语音合成的软件有很多,其中讯飞和百度是比较好的两种,我们这里就使用百度语音合成API来实现。
创建语音合成应用
首先注册百度账号,然后登录到百度AI开放平台,创建一个应用

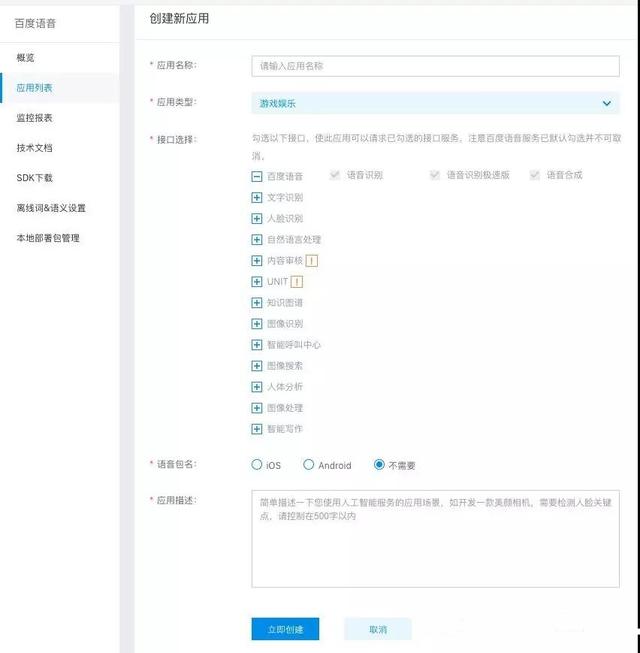
填写应用名和描述信息提交

记住AppID、API Key、Secret Key,在使用API的时候会用到,查看一下技术文档
),使用pip install baidu-aip安装完API,文档内有详细的示例代码,很容易就上手了。里面有各种参数解释,比如音量、语调、语速、发声人等。现在语音合成已经有了,已经有了阅读的前提,下面就是获取小说内容了。
获取小说内容
小说内容的获取我们从笔趣阁网站上获取,一方面免费,另一方面没有反爬,找到网站首页
https://www.biquge.info/40_40289/,使用requests大法就可以了。简单分析一下页面
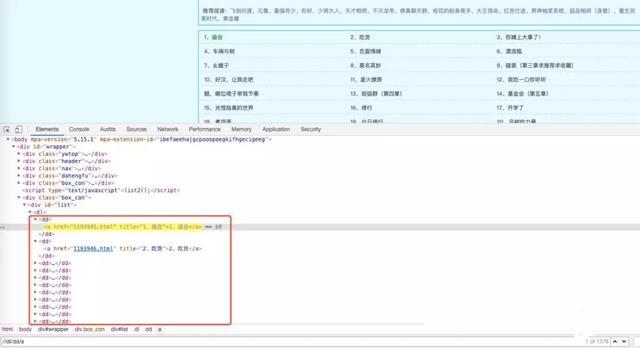
所有章节信息都在dd元素下,而且链接也是很有规律的,直接用xpath获取所有章节列表信息。
def get_chapters(self):
url = "https://www.biquge.info/40_40289/"
r = self.session.get(url)
r.encoding = chardet.detect(r.content).get("encoding", "utf-8")
html = etree.HTML(r.text)
for item in html.xpath("//dl/dd/a"):
yield item.attrib["title"], url + item.attrib["href"]
章节内容获取也非常简单,就不分析了
def get_content(self, url):
r = self.session.get(url)
r.encoding = chardet.detect(r.content).get("encoding", "utf-8")
html = etree.HTML(r.text)
title = html.xpath(r'//*[@class="bookname"]/h1')[0].text
for info in html.xpath("//div[@id='content']"):
text = info.xpath("string(.)")
这里有一点要注意的,获取的章节内容中有html元素,xpath为我们提供了string(.),提取多个子节点的文本,非常好用。
合成存储
小说内容获取成功了,与语音合成结合一下,小说阅读器的雏形就有了。简单实现如下:
import chardet
import requests
from lxml import etree
from aip import AipSpeech
class CollectNovels:
def __init__(self):
self.session = requests.session()
self.session.headers["user-agent"] = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
""" 你的 APPID AK SK """
APP_ID = '16416498'
API_KEY = 'oEWGafQkaUGqmsmPbfkE5OMx'
SECRET_KEY = '6jdsUcH0PXz5TYoELU47u58W5vPV9lwf'
self.client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def get_chapters(self, url):
r = self.session.get(url)
r.encoding = chardet.detect(r.content).get("encoding", "utf-8")
html = etree.HTML(r.text)
for item in html.xpath("//dl/dd/a"):
yield item.attrib["title"], url + item.attrib["href"]
def get_content(self, url):
r = self.session.get(url)
r.encoding = chardet.detect(r.content).get("encoding", "utf-8")
html = etree.HTML(r.text)
for info in html.xpath("//div[@id='content']"):
text = info.xpath("string(.)")
for line in text.split("。"):
content = self.client.synthesis(line, 'zh', 1, {"per": 0})
with open("auido.mp3", "rb") as fp:
fp.write(content)
if __name__ == '__main__':
novel = CollectNovels()
home_url = "https://www.biquge.info/40_40289/"
for title, url in novel.get_chapters(home_url):
novel.get_content(url)
这里是生成了mp3文件,按行生成以后,再使用合成软件合成后,我们就可以放在任意地方去听了。但是这样也有缺陷,必须提前生成,然后才能使用播放器听,这样不是很方便。如果可以边生成边播放是不是更好呢?
播放合成语音
我们可以使用python的pygame库,其他的好几个库都不太好用,有些已经年久失修了,所以就不用了。
import time import pygame from io import BytesIO pygame_mixer = pygame.mixer pygame_mixer.init(frequency=frequency) byte_obj = BytesIO() byte_obj.write(content) byte_obj.seek(0, 0) pygame_mixer.music.load(byte_obj) pygame_mixer.music.play() while pygame_mixer.music.get_busy(): time.sleep(0.1) pygame_mixer.stop()
这里使用BytesIO将语音合成的二进制文件存储在内存中,就不需要再保存成本地mp3了。
有一个需要注意的地方pygame_mixer.init(frequency=frequency),这个frequency参数是音频频率,如果不设置的话默认是22050,播放出来的声音和mp3播放相差太大了,一直以为是这个库有问题,换了好几个,有的是用不了,有的有问题,后来我才发现需要设置这个参数,那么这个参数从哪里来呢?查看之前生成的mp3文件属性
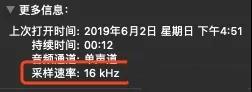
然后将频率设置为16000就可以了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。