Pandas透视表(pivot_table)详解
介绍
也许大多数人都有在Excel中使用数据透视表的经历,其实Pandas也提供了一个类似的功能,名为pivot_table。虽然pivot_table非常有用,但是我发现为了格式化输出我所需要的内容,经常需要记住它的使用语法。所以,本文将重点解释pandas中的函数pivot_table,并教大家如何使用它来进行数据分析。
如果你对这个概念不熟悉,wikipedia上对它做了详细的解释。顺便说一下,你知道微软为PivotTable(透视表)注册了商标吗?其实以前我也不知道。不用说,下面我将讨论的透视表并不是PivotTable。
作为一个额外的福利,我创建了一个总结pivot_table的简单备忘单。你可以在本文的最后找到它,我希望它能够对你有所帮助。如果它帮到了你,请告诉我。
数据
使用pandas中pivot_table的一个挑战是,你需要确保你理解你的数据,并清楚地知道你想通过透视表解决什么问题。其实,虽然pivot_table看起来只是一个简单的函数,但是它能够快速地对数据进行强大的分析。
在本文中,我将会跟踪一个销售渠道(也称为漏斗)。基本的问题是,一些销售周期很长(可以想一下“企业软件”、“资本设备”等),而管理者想更详细地了解它一整年的情况。
典型的问题包括:
- 本渠道收入是多少?
- 渠道的产品是什么?
- 谁在什么阶段有什么产品?
- 我们年底前结束交易的可能性有多大?
很多公司将会使用CRM工具或者其他销售使用的软件来跟踪此过程。虽然他们可能拥有有效的工具对数据进行分析,但肯定有人需要将数据导出到Excel,并使用一个透视表工具来总结这些数据。
使用Pandas透视表将是一个不错的选择,应为它有以下优点:
- 更快(一旦设置之后)
- 自行说明(通过查看代码,你将知道它做了什么)
- 易于生成报告或电子邮件
- 更灵活,因为你可以定义定制的聚合函数
Read in the data
首先,让我们搭建所需的环境。
如果你想跟随我继续下去,那么可以下载这个Excel文件。
import pandas as pd import numpy as np
版本提醒
因为Pivot_table API已经随着时间有所改变,所以为了使本文中示例代码能够正常工作,请确保你安装了最近版本的Pandas(>0.15)。本文示例还用到了category数据类型,而它也需要确保是最近版本。
首先,将我们销售渠道的数据读入到数据帧中。
df = pd.read_excel("../in/sales-funnel.xlsx")
df.head()
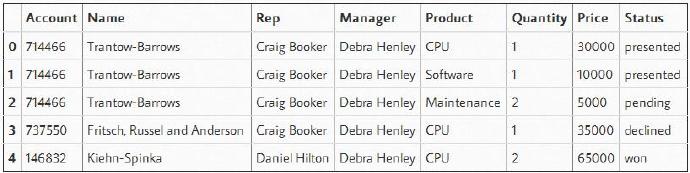
为方便起见,我们将上表中“Status”列定义为category,并按我们想要的查看方式设置顺序。
其实,并不严格要求这样做,但这样做能够在分析数据的整个过程中,帮助我们保持所想要的顺序。
df["Status"] = df["Status"].astype("category")
df["Status"].cat.set_categories(["won","pending","presented","declined"],inplace=True)
处理数据
既然我们建立数据透视表,我觉得最容易的方法就是一步一个脚印地进行。添加项目和检查每一步来验证你正一步一步得到期望的结果。为了查看什么样的外观最能满足你的需要,就不要害怕处理顺序和变量的繁琐。
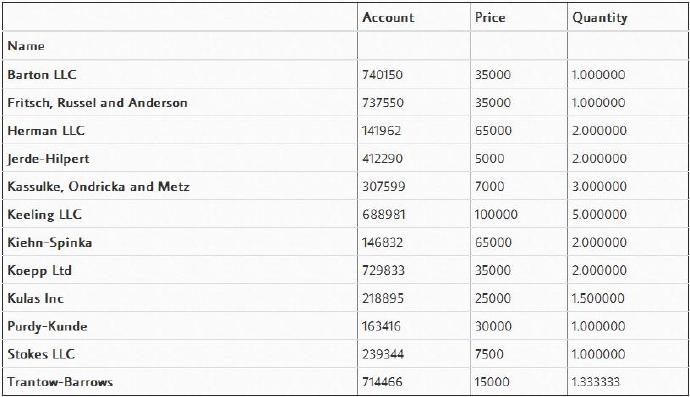
最简单的透视表必须有一个数据帧和一个索引。在本例中,我们将使用“Name(名字)”列作为我们的索引。
pd.pivot_table(df,index=["Name"])
此外,你也可以有多个索引。实际上,大多数的pivot_table参数可以通过列表获取多个值。
pd.pivot_table(df,index=["Name","Rep","Manager"])
这样很有趣但并不是特别有用。我们可能想做的是通过将“Manager”和“Rep”设置为索引来查看结果。要实现它其实很简单,只需要改变索引就可以。
pd.pivot_table(df,index=["Manager","Rep"])
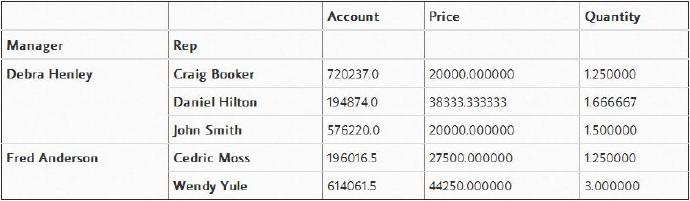
可以看到,透视表比较智能,它已经开始通过将“Rep”列和“Manager”列进行对应分组,来实现数据聚合和总结。那么现在,就让我们共同看一下数据透视表可以为我们做些什么吧。
为此,“Account”和“Quantity”列对于我们来说并没什么用。所以,通过利用“values”域显式地定义我们关心的列,就可以实现移除那些不关心的列。
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"])
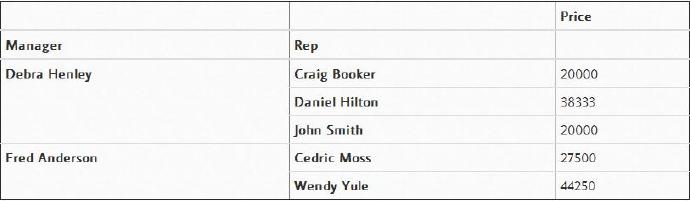
“Price”列会自动计算数据的平均值,但是我们也可以对该列元素进行计数或求和。要添加这些功能,使用aggfunc和np.sum就很容易实现。
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"],aggfunc=np.sum)
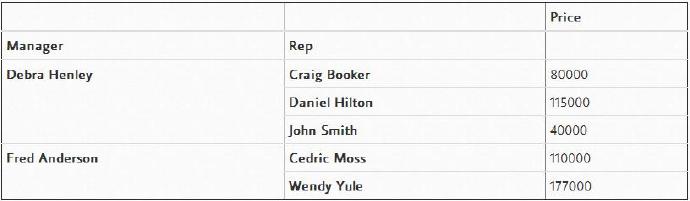
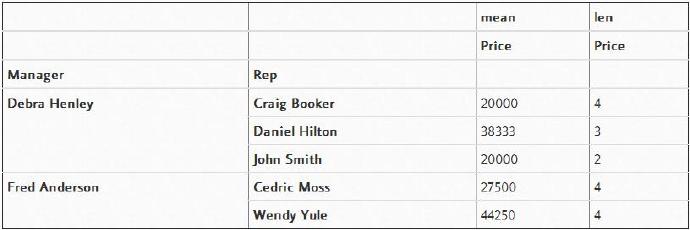
aggfunc可以包含很多函数,下面就让我们尝试一种方法,即使用numpy中的函数mean和len来进行计数。
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"],aggfunc=[np.mean,len])
如果我们想通过不同产品来分析销售情况,那么变量“columns”将允许我们定义一个或多个列。
列vs.值
我认为pivot_table中一个令人困惑的地方是“columns(列)”和“values(值)”的使用。记住,变量“columns(列)”是可选的,它提供一种额外的方法来分割你所关心的实际值。然而,聚合函数aggfunc最后是被应用到了变量“values”中你所列举的项目上。
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"],
columns=["Product"],aggfunc=[np.sum])
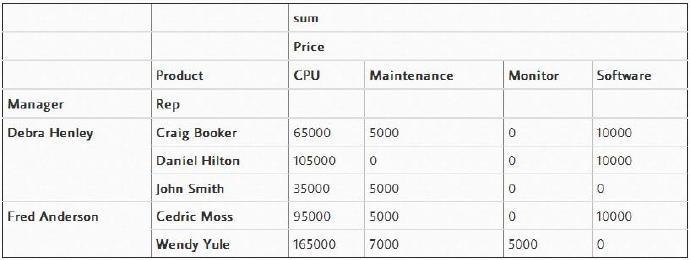
然而,非数值(NaN)有点令人分心。如果想移除它们,我们可以使用“fill_value”将其设置为0。
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"],
columns=["Product"],aggfunc=[np.sum],fill_value=0)
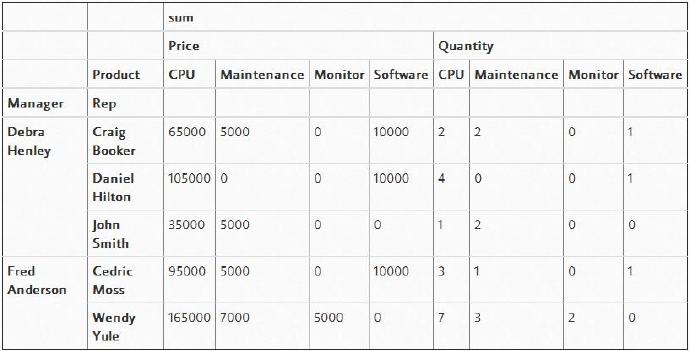
其实,我觉得添加“Quantity”列将对我们有所帮助,所以将“Quantity”添加到“values”列表中。
pd.pivot_table(df,index=["Manager","Rep"],values=["Price","Quantity"],
columns=["Product"],aggfunc=[np.sum],fill_value=0)
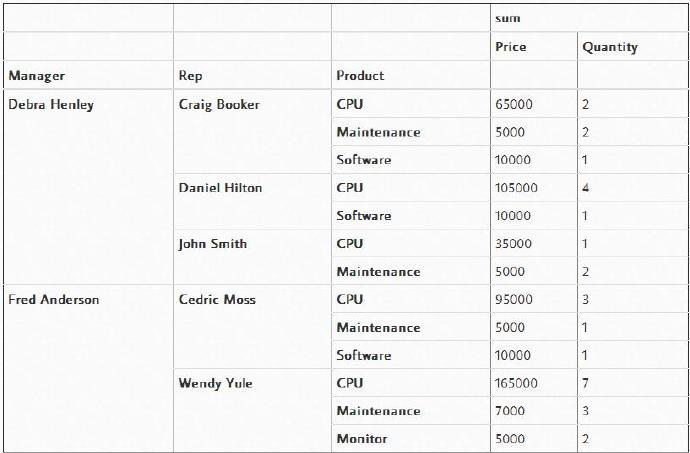
有趣的是,你可以将几个项目设置为索引来获得不同的可视化表示。下面的代码中,我们将“Product”从“columns”中移除,并添加到“index”变量中。
pd.pivot_table(df,index=["Manager","Rep","Product"],
values=["Price","Quantity"],aggfunc=[np.sum],fill_value=0)
对于这个数据集,这种显示方式看起来更有意义。不过,如果我想查看一些总和数据呢?“margins=True”就可以为我们实现这种功能。
pd.pivot_table(df,index=["Manager","Rep","Product"],
values=["Price","Quantity"],
aggfunc=[np.sum,np.mean],fill_value=0,margins=True)
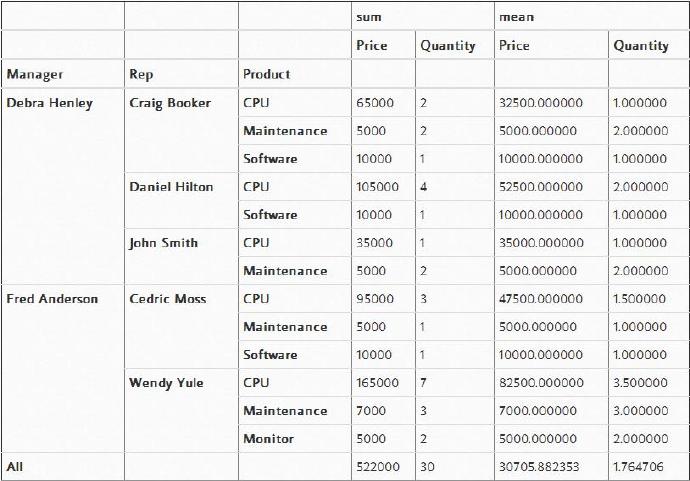
下面,让我们以更高的管理者角度来分析此渠道。根据我们前面对category的定义,注意现在“Status”是如何排序的。
pd.pivot_table(df,index=["Manager","Status"],values=["Price"],
aggfunc=[np.sum],fill_value=0,margins=True)
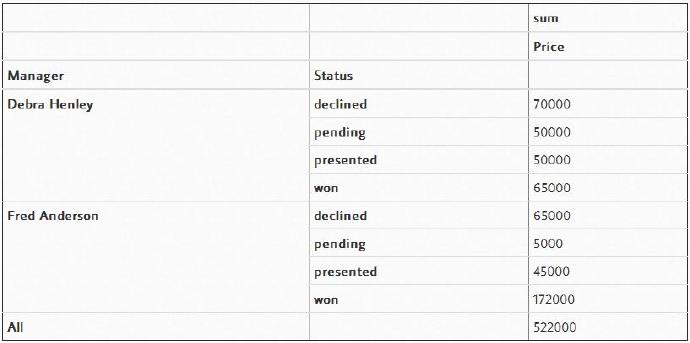
一个很方便的特性是,为了对你选择的不同值执行不同的函数,你可以向aggfunc传递一个字典。不过,这样做有一个副作用,那就是必须将标签做的更加简洁才行。
pd.pivot_table(df,index=["Manager","Status"],columns=["Product"],values=["Quantity","Price"],
aggfunc={"Quantity":len,"Price":np.sum},fill_value=0)
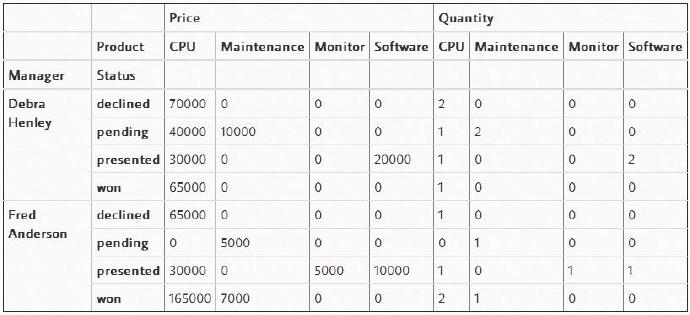
此外,你也可以提供一系列的聚合函数,并将它们应用到“values”中的每个元素上。
table = pd.pivot_table(df,index=["Manager","Status"],columns=["Product"],values=["Quantity","Price"],
aggfunc={"Quantity":len,"Price":[np.sum,np.mean]},fill_value=0)
table
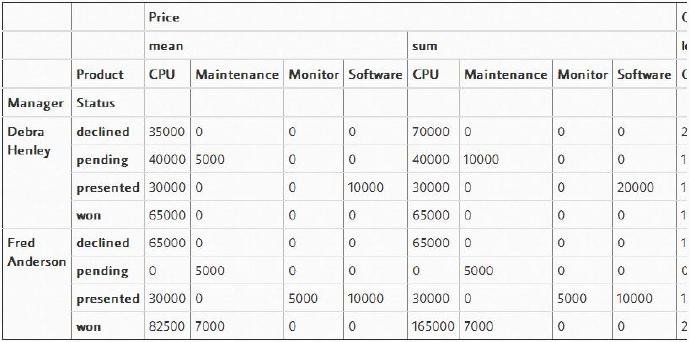
也许,同一时间将这些东西全都放在一起会有点令人望而生畏,但是一旦你开始处理这些数据,并一步一步地添加新项目,你将能够领略到它是如何工作的。我一般的经验法则是,一旦你使用多个“grouby”,那么你需要评估此时使用透视表是否是一种好的选择。
高级透视表过滤
一旦你生成了需要的数据,那么数据将存在于数据帧中。所以,你可以使用自定义的标准数据帧函数来对其进行过滤。
如果你只想查看一个管理者(例如Debra Henley)的数据,可以这样:
table.query('Manager == ["Debra Henley"]')
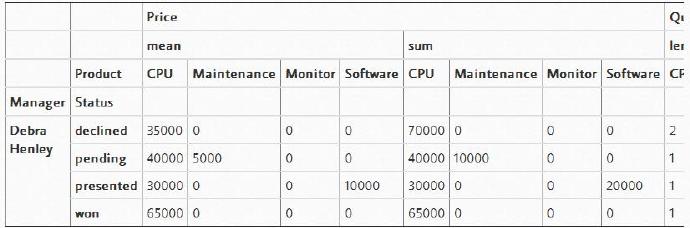
我们可以查看所有的暂停(pending)和成功(won)的交易,代码如下所示:
table.query('Status == ["pending","won"]')
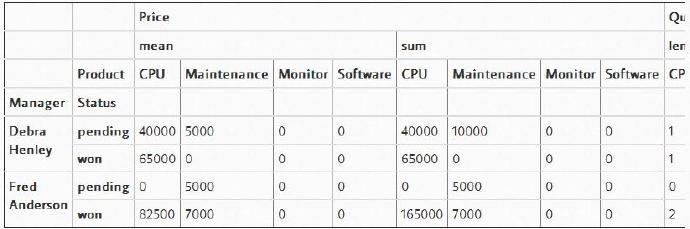
这是pivot_table中一个很强大的特性,所以一旦你得到了你所需要的pivot_table格式的数据,就不要忘了此时你就拥有了pandas的强大威力。
The full notebook is available if you would like to save it as a reference.
如果你想将其保存下来作为参考,那么这里提供完整的笔记。
备忘单
为了试图总结所有这一切,我已经创建了一个备忘单,我希望它能够帮助你记住如何使用pandas的pivot_table。
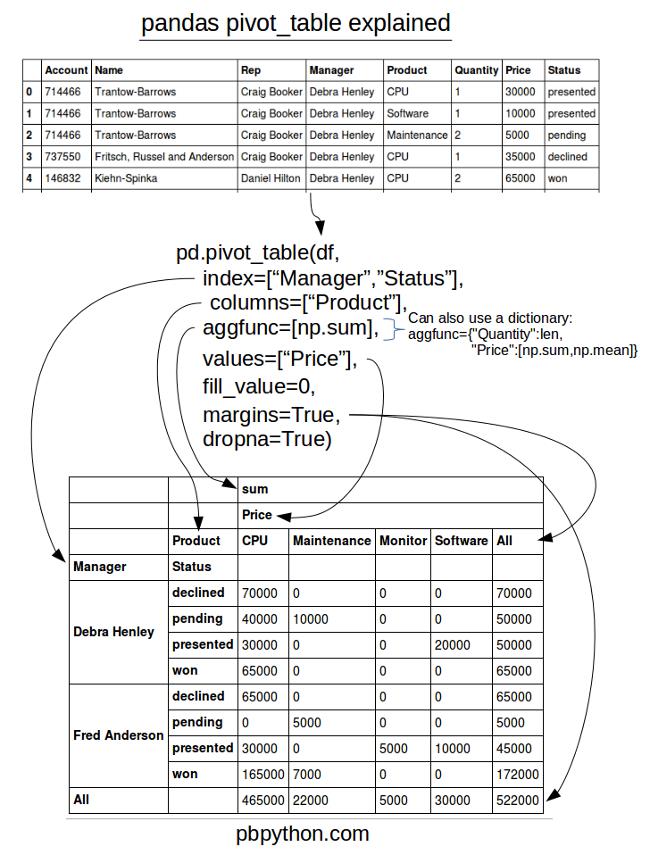
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。