Python 一键获取百度网盘提取码的方法

该 GIF 图来自于官网,文末有给出链接。
描述
依托于百度网盘巨大的的云存储空间,绝大数人会习惯性的将一些资料什么的存储到上面,但是有的私密链接需要提取码,但是让每个想下载私密资源的人记住每一个提取码显然是不现实的。这个时候,云盘万能钥匙 诞生了,我们通过安装相应的浏览器插件就可以自动获获取相应链接的提取码。我在 Github 上看了一下,有 Web JS 版的, python 版的貌似还没有找到,所以我参照了JS 版本和官网的请求接口写了两种方式的获取脚本。
实现
下述两种方式的具体实现就不做代码解释了,思路都是一样,通过请求接口,拿到数据,然后返回即可。
v1
"""
Author:hippieZhou
Date:20190608
Description: Get BaiDuYun shared link's Code
"""
import argparse
import re
import requests
import json
import time
VERSION = "VERSION 1.0.0"
def checkUrl(url: str) -> str:
m1 = re.match(
"https?:\/\/pan\.baidu\.com\/s\/1([a-zA-Z0-9_\-]{5,22})", url)
m2 = re.match(
"https?:\/\/pan\.baidu\.com\/share\/init\?surl=([a-zA-Z0-9_\-]{5,22})", url)
if not m1 and not m2:
print("参数不合法")
return False
else:
return True
def getKey(url: str) -> bool:
if checkUrl(url):
try:
req = requests.get(f"https://node.pnote.net/public/pan?url={url}")
code = req.status_code
if code == 200:
data = dict(json.loads(req.text))
status = data.get("status", False)
if status:
return data.get("access_code", "未能查询到该链接的提取码,可能原因是:该链接不需要提取码或已过期")
else:
return data.get("messages", "为能查询到提取码")
elif code == 404:
return "不存在该链接的记录"
except Exception as e:
return f"请求服务器失败,错误代码:[code]"
def get_parser():
parser = argparse.ArgumentParser()
parser.description = "百度网盘提取码一键获取器"
parser.add_argument('urls', metavar="urls", type=str, nargs="*",
help='设置要获取提取码的链接(多个链接请用空格分隔)')
parser.add_argument('-v', '--version', action='store_true',
help='版本号')
return parser
def command_line_runner():
parser = get_parser()
args = vars(parser.parse_args())
if args['version']:
print(VERSION)
return
s_time = time.time()
if len(args['urls']) > 1:
for item in args["urls"][1:]:
print(f"{item}:\r\n\t{getKey(item)}")
e_time = time.time()
print(f"\n\n操作完毕,总耗时:{e_time-s_time} 秒")
def main():
command_line_runner()
if __name__ == "__main__":
main()
运行效果如下图所示:

v2
"""
Author:hippieZhou
Date:20190608
Description: Get BaiDuYun shared link's Code
"""
import argparse
import time
import re
import requests
from datetime import datetime
import json
accessKey = "4fxNbkKKJX2pAm3b8AEu2zT5d2MbqGbD"
clientVersion = "web-client"
def getPid(url: str) -> str:
matches = re.match(
"https?:\/\/pan\.baidu\.com\/s\/1([a-zA-Z0-9_\-]{5,22})", url)
return matches[1] if matches else None
def getUuid(pid: str) -> str:
return f"BDY-{pid}"
def getKey(url: str) -> str:
pid = getPid(url)
uuid = getUuid(pid)
headers = {
"type": "GET",
"data": '',
"dataType": "json"
}
url = f"http://ypsuperkey.meek.com.cn//api/items/{uuid}?access_key={accessKey}&client_version={clientVersion}&{datetime.utcnow()}"
try:
req = requests.get(url, headers=headers)
code = req.status_code
if code == 200:
data = json.loads(req.text)
accessCode = data.get("access_code", None)
return "没找到提取密码,o(╥﹏╥)o" if (accessCode == "undefined" or accessCode == None or accessCode == "") else accessCode
elif code == 400:
return " 服务器不理解请求的语法"
elif code == 404:
return "不存在该链接的记录"
else:
return f"请求服务器失败,错误代码:[code]"
except Exception as e:
return e
def get_parser():
parser = argparse.ArgumentParser()
parser.description = "百度网盘提取码一键获取器"
parser.add_argument('urls', metavar="urls", type=str, nargs="*",
help='设置要获取提取码的链接(多个链接请用空格分隔)')
parser.add_argument('-v', '--version', action='store_true',
help='版本号')
return parser
def command_line_runner():
parser = get_parser()
args = vars(parser.parse_args())
if args['version']:
print(VERSION)
return
s_time = time.time()
if len(args['urls']) > 1:
for item in args["urls"][1:]:
print(f"{item}:\r\n\t{getKey(item)}")
e_time = time.time()
print(f"\n\n操作完毕,总耗时:{e_time-s_time} 秒")
def main():
command_line_runner()
if __name__ == "__main__":
main()
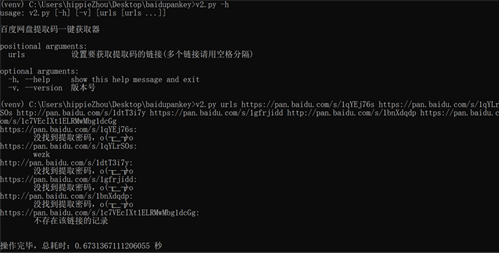
运行效果如下图所示:
总结
v1 版本和 v2 版本是通过请求不同的接口方式来实现的, v2 接口的数据要相对更准确一些。具体可查阅具体的代码实现。
如果你觉得上述代码不错的话,欢迎访问对应的仓库地址: baidupankey 进行 star 、fork 和 follow。
相关参考
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。