pandas DataFrame行或列的删除方法的实现示例
此文我们继续围绕DataFrame介绍相关操作。
平时在用DataFrame时候,删除操作用的不太多,基本是从源DataFrame中筛选数据,组成一个新的DataFrame再继续操作。
1. 删除DataFrame某一列
这里我们继续用上一节产生的DataFrame来做例子,原DataFrame如下:

我们使用drop()函数,此函数有一个列表形参labels,写的时候可以加上labels=[xxx],也可以不加,列表内罗列要删除行或者列的名称,默认是行名称,如果要删除列,则要增加参数axis=1,操作如下:
#pd.__version__ =='0.18.0' #drop columns test_dict_df.drop(['id'],axis=1) #test_dict_df.drop(columns=['id']) # official operation, maybe my pandas version needs update!
结果如下,对于上面的代码,官方教程文档中给出了columns=['name'],但是在我测试的时候会报错,我用的python3,pandas版本为0.18,可能是pandas版本太老的缘故。
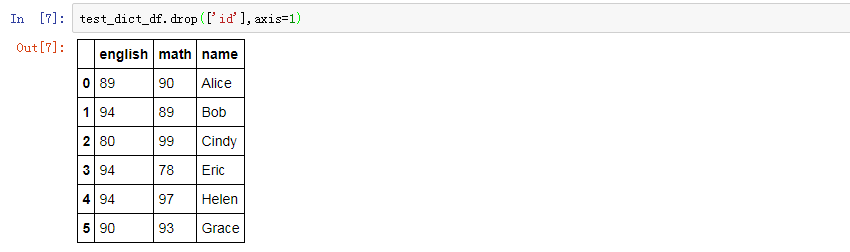
这里注意输出的结果是执行此方法的结果,而不是输出test_dict_df的结果,是因为方法默认的并不是在本身执行操作,这时候输出test_dict_df输出的仍然是没有进行删除操作的原DataFrame,如果你想在原DataFrame上进行操作,需要加上inplace=True,等价于在操作完再赋值给本身:
test_dict_df.drop(['id'],axis=1,inplace=True) # test_dict_df = test_dict_df.drop(['id'],axis=1)
2. 删除DataFrame某一行
删除某一行,在上面删除列操作的时候也稍有提及,如果不加axis=1,则默认按照行号进行删除,例如要删除第0行和第4行:
test_dict_df.drop([0,4])
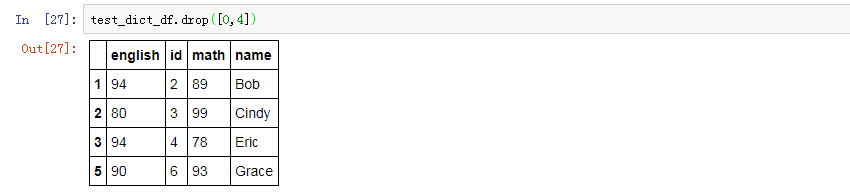
同理,你要在源DataFrame上进行操作就得加上inplace参数,否则不会在test_dict_df上改动。
当然,如果你的DataFrame有很多级,你可以加上level参数,这里就不多赘述了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。