浅谈Python中(&,|)和(and,or)之间的区别
(&,|)和(and,or)是两组比较相似的运算符,用在“与”/ “或”上,在用法上有些许区别。
(&,|)和(and,or)是用来比较两组变量的,格式基本上是:
a & b a | b a and b a or b
如果a,b是数值变量, 则&, |表示位运算, and,or则依据是否非0来决定输出,
&, |:
# 1&2,2在二进制里面是10,1在二进制中是01,那么01与运算10得到是0 1 & 2 # 输出为 0, 1 | 2 # 输出为3
and, or:
# 判断变量是否为0, 是0则为False,非0判断为True, # and中含0,返回0; 均为非0时,返回后一个值, 2 and 0 # 返回0 2 and 1 # 返回1 1 and 2 # 返回2 # or中, 至少有一个非0时,返回第一个非0, 2 or 0 # 返回2 2 or 1 # 返回2 0 or 1 # 返回1
如何a, b是逻辑变量, 则两类的用法基本一致
In[103]:(3>0) | (3<1) Out[103]: True In[104]:(3>0) and (3<1) Out[104]: False In[105]:(3>0) or (3<1) Out[105]: True In[106]:(3>0) & (3<1) Out[106]: False
值得提及的是在DataFrame的切片过程,要注意逻辑变量的使用,
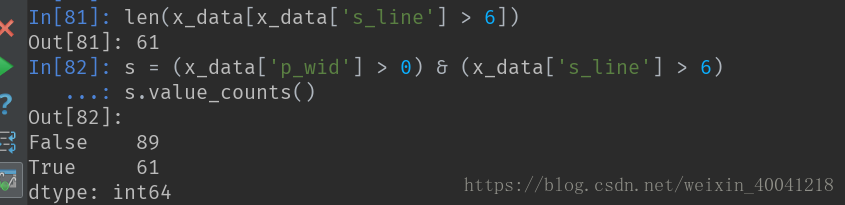
需要求得满足多个逻辑条件的数据时,要使用& 和|,在某些条件下用and/ or会报错‘ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().'
target_url = "http://aima.cs.berkeley.edu/data/iris.csv" data = pd.read_csv(target_url, header=None, columns=['s_line', 's_wid', 'p_line', 'p_wid', 'kind']) data.columns = ['s_line', 's_wid', 'p_line', 'p_wid', 'kind'] x_data = data.iloc[:, :-1] # 在多个逻辑条件下,用& 或者|, x_1 = x_data[x_data['s_line'] > 6 & x_data['p_wid'] > 0]

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。