python3 selenium自动化 下拉框定位的例子
我们在做web UI自动化时,经常会碰到下拉框,如下图:
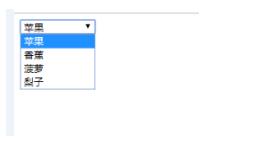
所上图,下拉框的源代码如下:
<html1> <head></head> <body> <select id="fruit" name="水果" style="width:100px;"> <option value ="0">苹果</option> <option value ="1">香蕉</option> <option value="2">菠萝</option> <option value="3">梨子</option> </body> </select>
假如我们要选择‘菠萝',我们将怎么实现呢?
首先我们要定位水果框,再定位水果下面的元素,如下图所示:
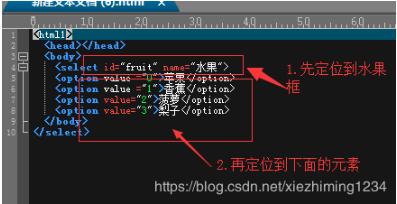
具体代码如下:
from selenium import webdriver
from selenium.webdriver.support.select import Select #首先必须要导入select包才能定位
from time import sleep
dr = webdriver.Chrome()
dr.get(r'D:\下拉框.html')
#先定位到水果框,用变量selectfruit
selectFruit = dr.find_element_by_id('fruit')
#再定位到具体的元素,菠萝
Select(selectFruit).select_by_visible_text('菠萝')
定位完毕,收工。
以上这篇python3 selenium自动化 下拉框定位的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。