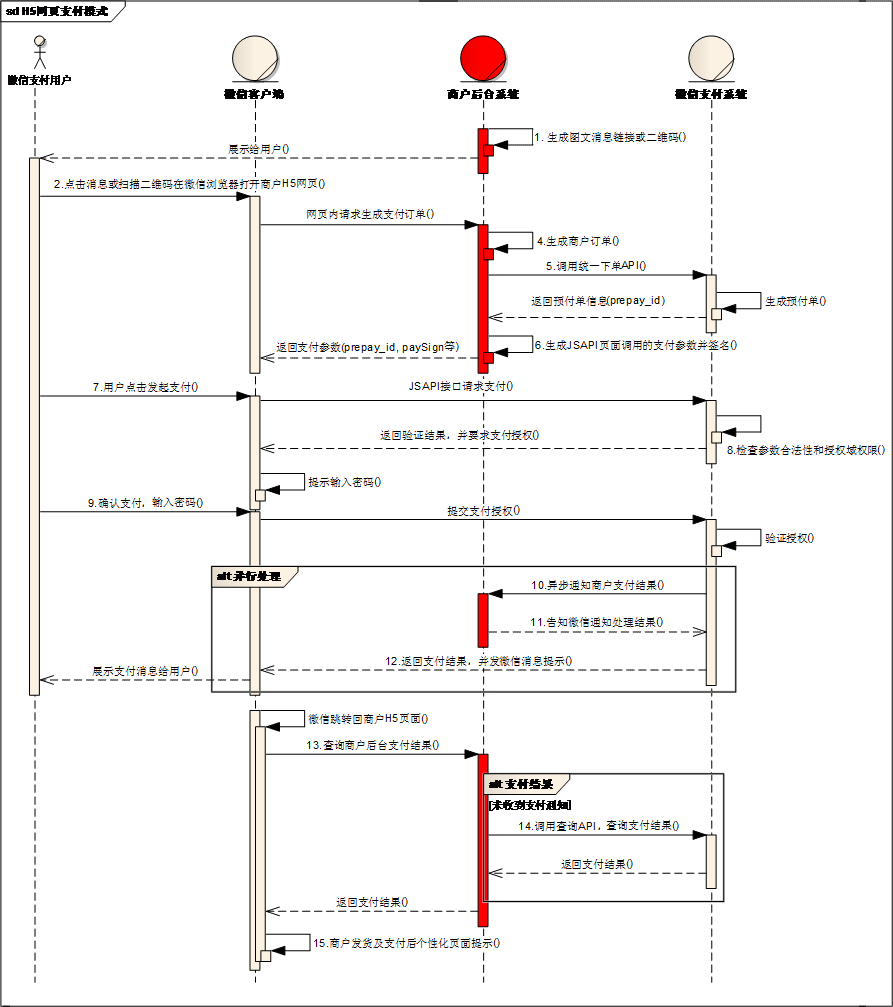
python 使用pdfminer3k 读取PDF文档的例子
1、安装 pdfminer3k
通过pip安装: pip install pdfminer3k
下载安装:在网页 https://pypi.org/project/pdfminer3k/1.3.1/#files 进行下载,解压。然后cmd命令进入到当前文件夹:
可以直接在资源管理器的路径栏直接输入cmd进入到当前目录。然后执行 python setup.py install 等待安装完成
2.读取pdf中的TXT代码示例:
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
# 可以使用此方法获取网络上的pdf
from urllib.request import urlopen
fp = urlopen("https://******/articles/800348152163.pdf")
#获取文档对象
#fp = open("****.pdf", "rb")
#创建一个一个与文档关联的解释器
parser = PDFParser(fp)
#PDF文档的对象
doc = PDFDocument()
#连接解释器和文档对象
parser.set_document(doc)
doc.set_parser(parser)
#初始化文档,当前文档没有密码,设为空字符串
doc.initialize("")
#创建PDF资源管理器
resource = PDFResourceManager()
#参数分析器
laparam = LAParams()
#创建一个聚合器
device = PDFPageAggregator(resource, laparams=laparam)
#创建PDF页面解释器
interpreter = PDFPageInterpreter(resource, device)
#使用文档对象得到页面的集合
for page in doc.get_pages():
# 使用页面解释器读取
interpreter.process_page(page)
# 使用聚合器来获得内容
layout = device.get_result()
for out in layout:
if hasattr(out, "get_text"):
print(out.get_text())
以上这篇python 使用pdfminer3k 读取PDF文档的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。