浅谈django url请求与数据库连接池的共享问题
但凡介绍数据库连接池的文章,都会说“数据库连接是一种关键的有限的昂贵的资源,这一点在多用户的网页应用程序中体现得尤为突出。对数据库连接的管理能显著影响到整个应用程序的伸缩性和健壮性,影响到程序的性能指标。数据库连接池正是针对这个问题提出来的。数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。”
这句话虽然说得很好,但也很让人疑惑。比如,多个请求是怎样共用数据库连接池啊?
其实,数据库连接池主要是利用了程序,静态变量与静态方法的概念实现的。静态变量和静态方法,是程序运行时,就被加载到内存中的。该进程中所有对于它的访问,都是对“唯一”的它的访问。所以,才能有数据库连接池被共享的概念。
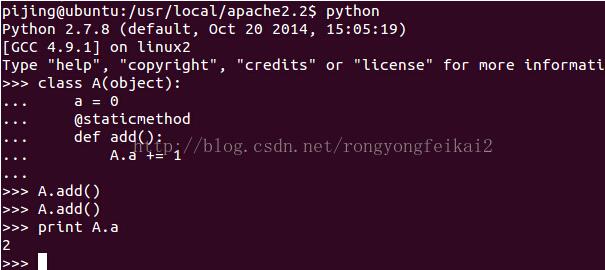
可以看到,静态变量a以及静态方法add,即使类A从未被实例化过,它们也都会被加载到内存中。
另外,在python的此次运行(一个进程)中,多次对a的操作,都是对为一个的这个a变量的操作,所以它的值是在被操作后累加的。
这个在我上面简单的例子中很好理解。那么如何理解Web应用程序(如django程序)在接到url请求时的场景呢?在多个请求时,他们是如何可以共享数据库连接池的?
我写了一个简单的例子:
Test model,使用了单例模式,它的功能是调用sqlalchemy.pool中的数据库连接池。
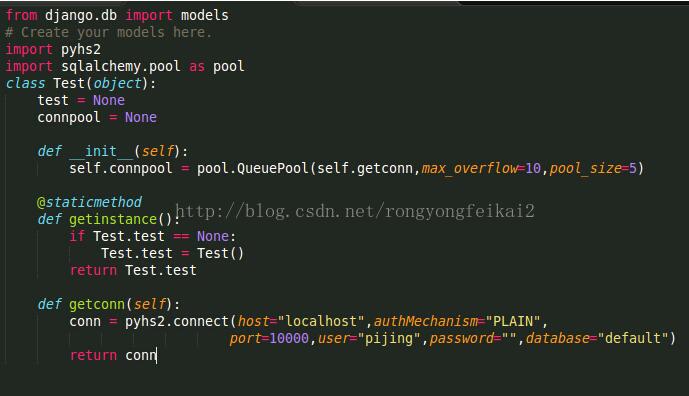
而views.py的index方法,则是调用Test的getinstance方法获得它的实例,同时用它的数据库连接池。
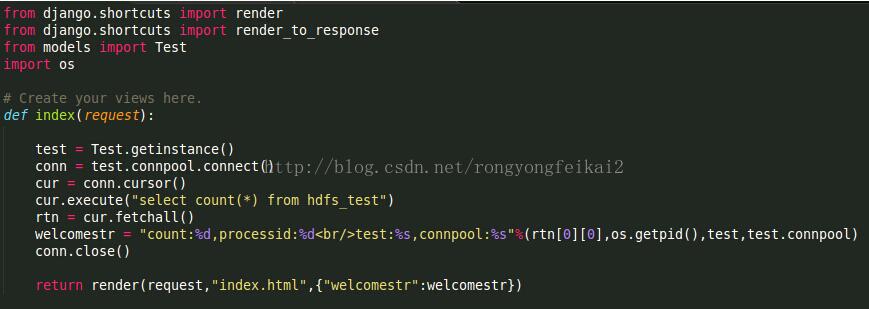
为了看得清楚,我在这个方法中增加打印了当前所属进程的pid,test和test.connpool信息。
首先要说明一点,apache在windows和linux中的运行方式不尽相同(windows是两个httpd进程,一个父进程,一个子进程,子进程里面多个线程处理请求)。在linux中,默认用prefork的方式运行。即一个父进程,多个子进程,这多个子进程负责处理web请求。
如下图所示:
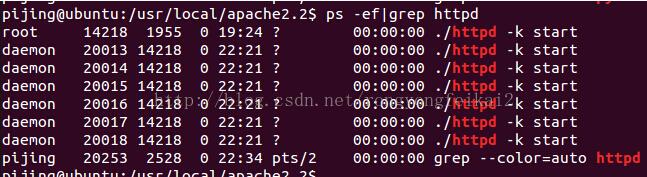
然后我们尝试多次url请求(适当变化url,避免缓存);并记录结果:
http://10.67.2.21:8081/ips/
count:3,processid:20016<br/>test:<ipsapp.models.Test object at 0x7f2b1070ac50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b1070ad10>
http://10.67.2.21:8081/ips/?user=kjsdkfjsdf&kljsdlkfjsdf
count:3,processid:20013<br/>test:<ipsapp.models.Test object at 0x7f2b107c6c10>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b107c6cd0>
http://10.67.2.21:8081/ips/?user=kjsdkfjsdf&kljsdlkfjsdf&pass=ksjdkjdf
count:3,processid:20018<br/>test:<ipsapp.models.Test object at 0x7f2b103c6c50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b103c6d10>
http://10.67.2.21:8081/ips/?user=123u42i3u4
count:3,processid:20016<br/>test:<ipsapp.models.Test object at 0x7f2b1070ac50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b1070ad10>
http://10.67.2.21:8081/ips/?user=123u42i3u4&tewstsjdfkjslfj
count:3,processid:20013<br/>test:<ipsapp.models.Test object at 0x7f2b107c6c10>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b107c6cd0>
http://10.67.2.21:8081/ips/?user=passwode
count:3,processid:20018<br/>test:<ipsapp.models.Test object at 0x7f2b103c6c50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b103c6d10>
http://10.67.2.21:8081/ips/?newiusd=kjsdkjfd&kjsdkjf=ksdjflksjdlkf
count:3,processid:20016<br/>test:<ipsapp.models.Test object at 0x7f2b1070ac50>,connpool:<sqlalchemy.pool.QueuePool object at 0x7f2b1070ad10>
apache pid Test object QueuePool object
20016 0x7f2b1070ac50 0x7f2b1070ad10
20013 0x7f2b107c6c10 0x7f2b107c6cd0
20018 0x7f2b103c6c50 0x7f2b103c6d10
20016 0x7f2b1070ac50 0x7f2b1070ad10
20013 0x7f2b107c6c10 0x7f2b107c6cd0
20018 0x7f2b103c6c50 0x7f2b103c6d10
20016 0x7f2b1070ac50 0x7f2b1070ad10
我把分属于不同apache进程处理的请求用颜色标出了,在本例子中,7个请求,分配到了3个apache进程处理。可以看到,被同一个apache子进程处理的请求,是共用同一个test和test.connpool实例的,即他们共享数据库连接池。
所以,数据库连接池,对于web请求而言,是属于同一个apache子进程处理的请求共用一个数据库连接池。
以上这篇浅谈django url请求与数据库连接池的共享问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。