


相关文章

对pyqt5中QTabWidget的相关操作详解
首先,下面贴上designer处理的界面文件(转换成py后的): # -*- coding: utf-8 -*- # Form implementation generated...
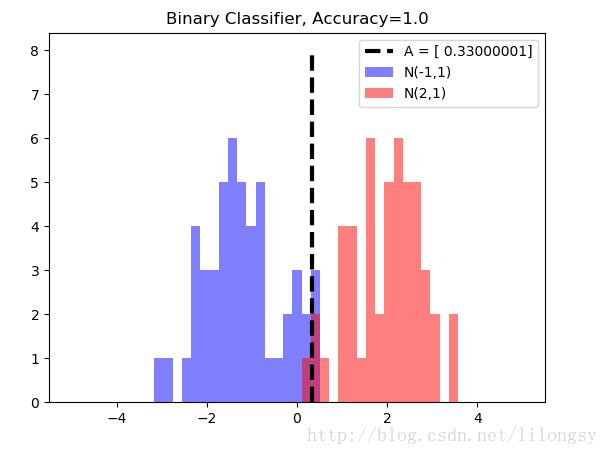
TensorFlow实现模型评估
我们需要评估模型预测值来评估训练的好坏。 模型评估是非常重要的,随后的每个模型都有模型评估方式。使用TensorFlow时,需要把模型评估加入到计算图中,然后在模型训练完后调用模型评...
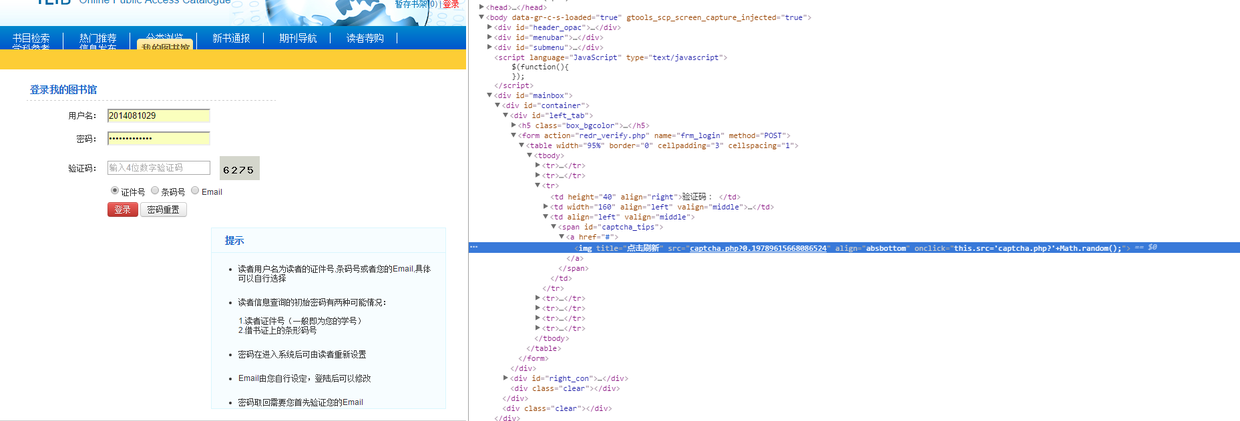
利用Python实现图书超期提醒
一、模拟登录图书馆管理系统 我们可以先看一下登录页面(很多学校这些管理系统页面就是很low): 两种方式去模拟登录图书馆: 1. 构造登录表单进行模拟登录 这种方式模拟登录似乎是很可...
Python列表(List)知识点总结
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。 Python有6个序列的内置类型,但最常见的是列...
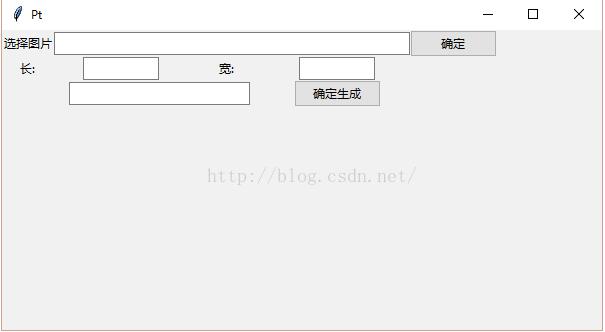
python如何制作缩略图
本文实例为大家分享了python制作缩略图的具体代码,供大家参考,具体内容如下 import cv2 #导入opencv模块 from tkinter import * #导入tki...