基于Python检测动态物体颜色过程解析
本篇文章将通过图片对比的方法检查视频中的动态物体,并将其中会动的物体定位用cv2矩形框圈出来。本次项目可用于树莓派或者单片机追踪做一些思路参考。寻找动态物体也可以用来监控是否有人进入房间等等场所的监控。不仅如此,通过对物体的像素值判断分类,达到判断动态物体总体颜色的效果。
引言
物体检测,是一种基于目的几何学和统计资料特点的影像拆分,它将目的的拆分和辨识,其准确度和实时性是整个该系统的一项最重要战斗能力。特别是在是在简单桥段中的,必须对多个目的展开实时处理时,目的系统会萃取和辨识就变得尤其最重要。
随着计算机的持续发展和计算机系统感官基本原理的应用,建模数据处理新技术对目的展开动态追踪研究工作更加受欢迎,对目的展开静态动态追踪整合在信息化公交系统、人工智能监视该系统、军事战略目的检验及药学导航系统手术后中的手术器械整合等各个方面具备普遍的应用于商业价值。
开始前的准备
而这里显然我们没必要做到如此高深的地步,而是借助python和OpenCV通过图片相减的方法找到动态物体,然后根据像素值的大小判断其中的均值颜色。
import cv2 import numpy as np import collections import time
下面是读取摄像头:
camera = cv2.VideoCapture(0)
做一些开始前的准备,包括循环次数,摄像头内容读入,保存上一帧的图片作为对比作差找到动态物体,然后定义框架的长和宽。
firstframe = None
a=0
ret0,frame0 = camera.read()
cv2.imwrite("1.jpg",frame0)
x, y, w, h = 10,10,100,100
下面是定义颜色的部分代码,比如定义的黑色,可以参照hsv表进行拓展,如图所示
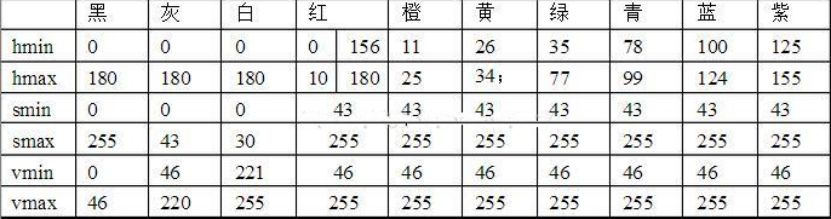
然后可以知道黑色的最低值为0,0,0,最大值为180,255,46然后建立数组存储颜色数据,通过字典达到映射效果。
# 处理图片
def get_color(frame):
print('go in get_color')
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
maxsum = -100
color = None
color_dict = getColorList()
for d in color_dict:
mask = cv2.inRange(frame, color_dict[d][0], color_dict[d][1])
cv2.imwrite(d + '.jpg', mask)
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1]
binary = cv2.dilate(binary, None, iterations=2)
img, cnts, hiera = cv2.findContours(binary.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
sum = 0
for c in cnts:
sum += cv2.contourArea(c)
if sum > maxsum:
maxsum = sum
color = d
return color
图像处理
紧接着是图像处理,其中包括转为灰度图,读取颜色字典,然后腐化膨胀操作。
# 处理图片
def get_color(frame):
print('go in get_color')
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
maxsum = -100
color = None
color_dict = getColorList()
for d in color_dict:
mask = cv2.inRange(frame, color_dict[d][0], color_dict[d][1])
cv2.imwrite(d + '.jpg', mask)
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1]
binary = cv2.dilate(binary, None, iterations=2)
img, cnts, hiera = cv2.findContours(binary.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
sum = 0
for c in cnts:
sum += cv2.contourArea(c)
if sum > maxsum:
maxsum = sum
color = d
return color
图片相减的办法
然后是图片相减找到动态物体的代码,每循环5次保存一次图片,时间是很短的不用担心。然后通过absdiff函数对图片像素值作差找到动态物体,接着讲像素值相减非零的部分用矩形框圈出来。
while True:
ret, frame = camera.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (21, 21), 0)
a=a+1
if a%5==0:
cv2.imwrite("1.jpg", frame)
firstframe=cv2.imread("1.jpg")
firstframe= cv2.cvtColor(firstframe, cv2.COLOR_BGR2GRAY)
firstframe= cv2.GaussianBlur(firstframe, (21, 21), 0)
frameDelta = cv2.absdiff(firstframe, gray)
thresh = cv2.threshold(frameDelta, 25, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.dilate(thresh, None, iterations=2)
# cnts= cv2.findContours(thresh.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
x, y, w, h = cv2.boundingRect(thresh)
frame = cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow("frame", frame)
因为保存图片是每隔5次进行一次,在某个瞬间可能保存的图片不存在等原因,所以需要通过try的方法避免错误,最终的演示效果文末有。
try:
ret0, frame0 = camera.read()
cropped = frame0[y:y+h,x:x+w ] # 裁剪坐标为[y0:y1, x0:x1]
cv2.imwrite("3.jpg", cropped)
frame1 = cv2.imread(filename)
print(get_color(frame1))
# plt.title(label[model.predict_classes(image)], fontproperties=myfont)
imgzi = cv2.putText(frame, get_color(frame1), (30, 30), cv2.FONT_HERSHEY_COMPLEX, 1.2,
(255, 255, 255), 2)
cv2.imwrite("2.jpg", imgzi)
cv2.imshow("frame", cv2.imread("2.jpg"))
except:
pass
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
camera.release()
其最终演示效果如图所示:

至此,动态物体检测代码基本实现。其中的拓展功能可以按照自己的需求进行修改、
目标检测的发展
下面就将目标检测发展做个简单介绍,感兴趣的朋友可以多多学习。
目标检验对于生物来说非常艰难,通过对照片中的有所不同色调组件的感官很更容易整合并归类出有其中目标物体,但对于计算机系统来说,面临的是像素分辨率行列式,难以从影像中的必要获得猫和狗这样的基本概念并整合其方位,再行再加通常多个物体和凌乱的复杂背景夹杂在一同,目标检验更为艰难。但这难不倒生物学家们,在现代感官各个领域,目的检验就是一个十分受欢迎的研究工作朝向,一些特定目的的检验,比如图片检验和天桥检验早已有十分成熟期的新技术了。一般来说的目标检验也有过很多的试图,但是视觉效果常常不错。现代的目的检验一般用于转动视窗的构建,主要还包括三个方法:
借助有所不同大小的转动视窗框住图中的某一部分作为候选区域内;
萃取候选区域内涉及的感官特点。比如图片检验常见的Harr特点;天桥检验和一般来说目的检验常见的HOG特点等;
借助决策树展开辨识,比如常见的SVM建模。
目的检验的第一步是要做到区域提名(region Proposal),也就是找到有可能的有兴趣区域内(region In Risk, ROI)。区域提名类似透镜字符识别(OCR)各个领域的重复,OCR重复常见过重复方式,非常简单说道就是尽可能磨碎到小的相连(比如小的笔划之类),然后再行根据邻接块的一些亲缘特点展开拆分。但目的检验的单纯比起OCR各个领域千差万别,而且三维点状,大小不等,所以一定高度上可以说道区域提名是比OCR重复更难的一个难题。
区域提名有可能的方式有:
一、转动视窗。转动视窗事物上就是穷举法,借助有所不同的时间尺度和长方形比把所有有可能的大大小小的块都穷举出来,然后送来去辨识,辨识出来机率大的就留下。很显著,这样的方式复杂性太低,造成了很多的校验候选区域内,在现实生活中不不切实际。
二、比赛规则块。在穷举法的为基础展开了一些剪枝,只搭配相同的尺寸和长方形比。这在一些特定的应用于桥段是很有效地的,比如照片搜题App小猿搜题中的的简化字检验,因为简化字方方正正,长方形比多数较为完全一致,因此用比赛规则块做到区域内奖提名是一种较为适合的自由选择。但是对于一般来说的目的检验来说,比赛规则块仍然必须采访很多的方位,复杂性低。
三、特异性搜寻。从神经网络的视角来说,后面的方式解任是不俗了,但是精确度不错,所以难题的架构在于如何有效除去校验候选区域内。只不过校验候选区域内多数是再次发生了重合,特异性搜寻借助这一点,自底向上拆分邻接的重合区域内,从而增加校验。
区域内奖提名非常只有以上所说的三种方式,实质上这块是灵活的,因此变型也很多,感兴趣的阅读不妨参照一下历史文献,最终介绍到此结束。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
