Python实现投影法分割图像示例(二)
在上篇博客中,我们已经实现了水平投影和垂直投影图的绘制。接下来,我们可以根据获得的投影数据进行图像的分割,该法用于文本分割较多,所以此处依然以上次的图为例。
先把上次的两幅图搬过来,方便讲解。
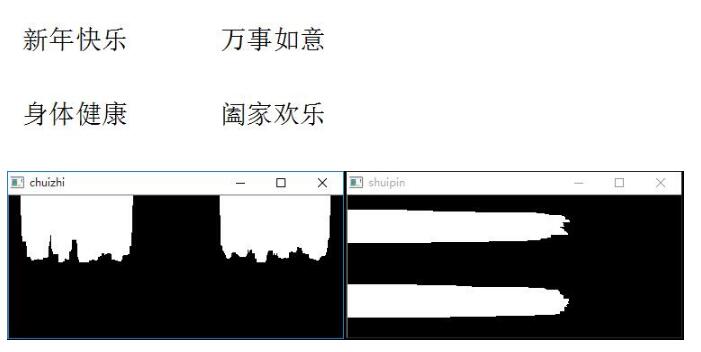
上面两图分别从垂直和水平方向描述了图像中文本的分布。我们想象一下,将两幅图重叠起来(当然这里比例要调整下),那么我们就能得到四个重叠的白块,而这些白块所处的位置正是原图中文本的位置。所以接下来的任务就是,找出这些白块的坐标,此处白块近似矩形,所以我们要求矩形的四个坐标。
下面看代码。
#根据水平投影值选定行分割点
inline = 1
start = 0
j = 0
for i in range(0,height):
if inline == 1 and z[i] >= 150 : #从空白区进入文字区
start = i #记录起始行分割点
print i
inline = 0
elif (i - start > 3) and z[i] < 150 and inline == 0 : #从文字区进入空白区
inline = 1
hfg[j][0] = start - 2 #保存行分割位置
hfg[j][1] = i + 2
j = j + 1
确定行分割点的原理就是判断每一行的像素点数是否足够。我们可以从水平投影图中看出,白块是有文字的地方(原图是黑字白底,只是画投影图时选用白块黑底),即前面几行,灰度值为0的点的个数N很少,所以当遇到文字区时,N会很大,根据这一点,我们确定进入文字区的坐标(A1,B1)。然后,当从文字区出来时,N又变的很小,我们再记下它的坐标(A1,B2)。同理,我们可以确定列分割点。
incol = 1
start1 = 0
j1 = 0
z1 = hfg[p][0]
z2 = hfg[p][1]
for i1 in range(0,width):
if incol == 1 and v[i1] >= 20 : #从空白区进入文字区
start1 = i1 #记录起始列分割点
incol = 0
elif (i1 - start1 > 3) and v[i1] < 20 and incol == 0 : #从文字区进入空白区
incol = 1
lfg[j1][0] = start1 - 2 #保存列分割位置
lfg[j1][1] = i1 + 2
l1 = start1 - 2
l2 = i1 + 2
j1 = j1 + 1
最后根据矩形的坐标将文本在图中框出来。附上完整代码。
import cv2
import numpy
img = cv2.imread('D:/0.jpg',cv2.COLOR_BGR2GRAY)
height, width = img.shape[:2]
#print height, width
#resized = cv2.resize(img, (2*width,2*height), interpolation=cv2.INTER_CUBIC)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
(_, thresh) = cv2.threshold(gray, 140, 255, cv2.THRESH_BINARY)
#使文字增长成块
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))#形态学处理,定义矩形结构
closed = cv2.erode(thresh, None, iterations = 7)
#cv2.imshow('erode',closed)
height, width = closed.shape[:2]
#print height, width
z = [0]*height
v = [0]*width
hfg = [[0 for col in range(2)] for row in range(height)]
lfg = [[0 for col in range(2)] for row in range(width)]
box = [0,0,0,0]
#水平投影
a = 0
emptyImage1 = numpy.zeros((height, width, 3), numpy.uint8)
for y in range(0, height):
for x in range(0, width):
cp = closed[y,x]
#if np.any(closed[y,x]):
if cp == 0:
a = a + 1
else :
continue
z[y] = a
#print z[y]
a = 0
#根据水平投影值选定行分割点
inline = 1
start = 0
j = 0
for i in range(0,height):
if inline == 1 and z[i] >= 150 : #从空白区进入文字区
start = i #记录起始行分割点
#print i
inline = 0
elif (i - start > 3) and z[i] < 150 and inline == 0 : #从文字区进入空白区
inline = 1
hfg[j][0] = start - 2 #保存行分割位置
hfg[j][1] = i + 2
j = j + 1
#对每一行垂直投影、分割
a = 0
for p in range(0, j):
for x in range(0, width):
for y in range(hfg[p][0], hfg[p][1]):
cp1 = closed[y,x]
if cp1 == 0:
a = a + 1
else :
continue
v[x] = a #保存每一列像素值
a = 0
#print width
#垂直分割点
incol = 1
start1 = 0
j1 = 0
z1 = hfg[p][0]
z2 = hfg[p][1]
for i1 in range(0,width):
if incol == 1 and v[i1] >= 20 : #从空白区进入文字区
start1 = i1 #记录起始列分割点
incol = 0
elif (i1 - start1 > 3) and v[i1] < 20 and incol == 0 : #从文字区进入空白区
incol = 1
lfg[j1][0] = start1 - 2 #保存列分割位置
lfg[j1][1] = i1 + 2
l1 = start1 - 2
l2 = i1 + 2
j1 = j1 + 1
cv2.rectangle(img, (l1, z1), (l2, z2), (255,0,0), 2)
cv2.imshow('result', img)
cv2.waitKey(0)
代码中注释掉的一些代码,有的是我做的一些小变动,有的是观察中间值。大家可自行查看。
最后放上结果图。

由于文本的坐标已经有了,还可以把这些文本块截取下来,用一下PIL或者OPENCV就好了,此处就不做了。
以上这篇Python实现投影法分割图像示例(二)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。
