yipeiwu_com6年前
python是支持多线程的,主要是通过thread和threading这两个模块来实现的。thread模块是比较底层的模块,threading模块是对thread做了一些包装...
yipeiwu_com6年前
本文实例讲述了Python3使用requests包抓取并保存网页源码的方法。分享给大家供大家参考,具体如下: 使用Python 3的requests模块抓取网页源码并保存到文件示例:...
yipeiwu_com6年前
关于DHT协议 DHT协议作为BT协议的一个辅助,是非常好玩的。它主要是为了在BT正式下载时得到种子或者BT资源。传统的网络,需要一台中央服务器存放种子或者BT资源,不仅浪费服务器资源,...
yipeiwu_com6年前
爬虫真是一件有意思的事儿啊,之前写过爬虫,用的是urllib2、BeautifulSoup实现简单爬虫,scrapy也有实现过。最近想更好的学习爬虫,那么就尽可能的做记录吧。这篇博客...
yipeiwu_com6年前
用python也差不多一年多了,python应用最多的场景还是web快速开发、爬虫、自动化运维:写过简单网站、写过自动发帖脚本、写过收发邮件脚本、写过简单验证码识别脚本。 爬虫在开发过程...
yipeiwu_com6年前
mechanize是对urllib2的部分功能的替换,能够更好的模拟浏览器行为,在web访问控制方面做得更全面。结合beautifulsoup和re模块,可以有效的解析web...
yipeiwu_com6年前
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫。 第一步:分析网站的请求过程 我们在查看拉勾网上的...
yipeiwu_com6年前
Python2.7Mac OS 抓取的是电影天堂里面最新电影的页面。链接地址: http://www.dytt8.net/html/gndy/dyzz/index.html 获取页面的中...
yipeiwu_com6年前
urllib urllib模块是python3的URL处理包 其中: 1、urllib.request主要是打开和阅读urls 个人平时主要用的1: 打开对应的URL:urllib.re...
yipeiwu_com6年前
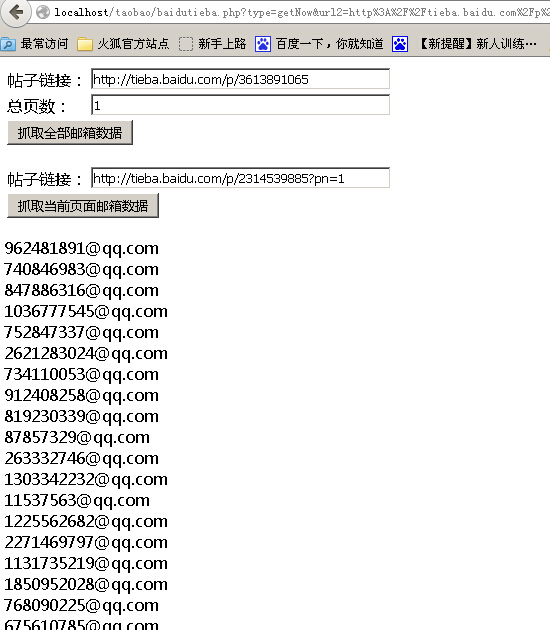
百度贴吧大家都经常逛,去逛百度贴吧的时候,经常会看到楼主分享一些资源,要求留下邮箱,楼主才给发。 对于一个热门的帖子,留下的邮箱数量是非常多的,楼主需要一个一个的去复制那些回复的邮箱,...